Foundry Fine-Tuning Nisan Güncellemesi: RFT Artık Ucuz
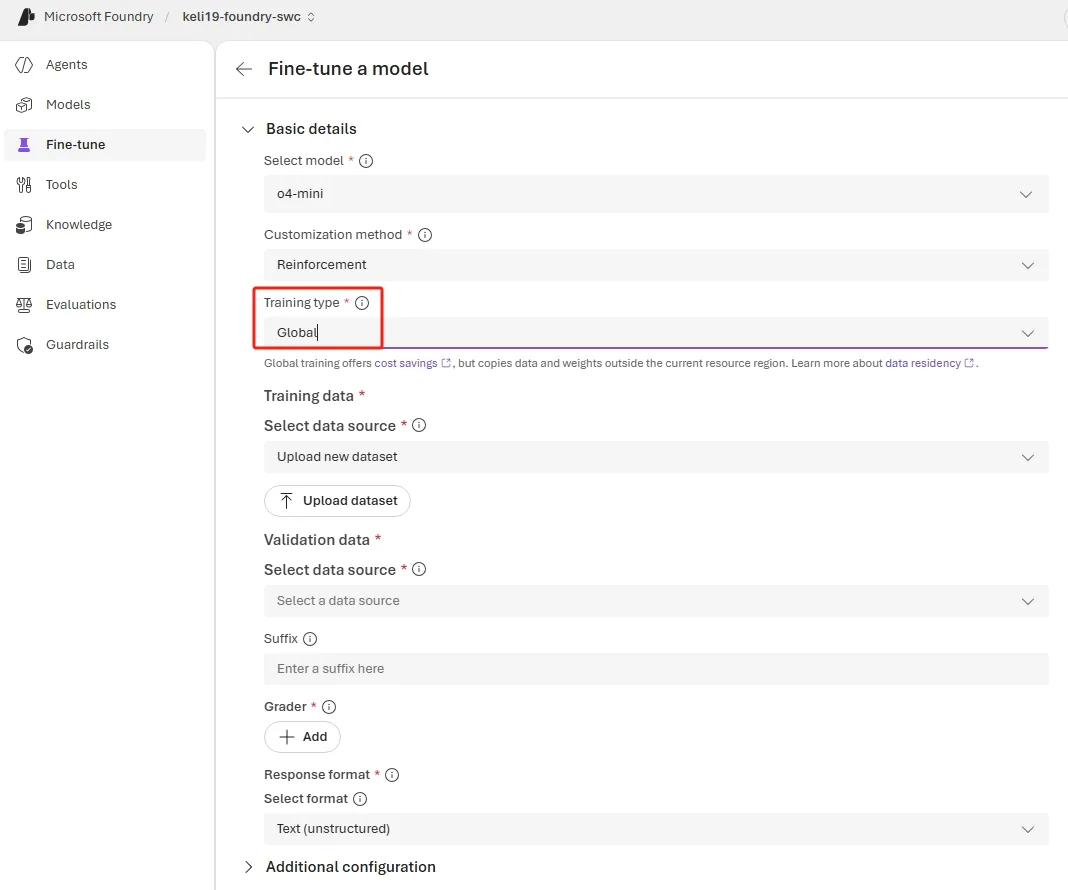
Geçen ay
Peki neden?
Maliyet Perspektifi: TL Bazında Düşününce
Yanı, Bu konuyu atlayamam, çünkü Türkiye’de ekipler en çok bunu soruyor. Bakın, Global Training ile Standard Training arasındaki fiyat farkı özellikle hacim büyüyünce hemen hissediliyor; ama işin asıl can sıkan tarafı gizli maliyetler, çünkü model grader kullanıyorsanız her grading çağrısı ayrı token yiyor — valla güzel iş çıkarmışlar —. 1000 eğitim örneğinde bu kalem bir anda gözünüzün önüne çıkıyor.
Bakın, Hmm, bir dakika… Şöyle somut anlatayım. Diyelim elinizde 200 örneklik bir eğitim seti var, her örneğin çıktısı ortalama 500 token, grader prompt’u da 300 token. GPT-4.1-nano ile grade ettiğinizde maliyet X seviyesinde kalırken, GPT-4.1’e geçtiğinizde bu rakam 5-6X bandına çıkabiliyor; TL’ye çevirince de kur oynaklığı yüzünden iş baya büyüyor, yanı burada mesele sadece teknik değil, bildiğiniz bütçe yönetimi.
Az önce “nano her zaman en ucuz” dedim ama açık konuşayım, öyle düz bir denklem yok. Nano’nun grading kalitesi düşük kalırsa model yanlış yöne kayabiliyor, sonra sız bir epoch daha çalıştırıyorsunuz, bazen iki kere uğraşıyorsunuz,. Toplam maliyet sessiz sedasız şişiyor; buna karşılık biraz daha pahalı ama oturaklı bir grading yaklaşımı çoğu senaryoda cebinizi daha az yorabiliyor.
Evet.
İşin püf noktası burada. Sız ne dersiniz?
Dikkat Etmeniz Gereken Eksikler
Güzel tarafları var, evet. Ama işin bir de pürüzlü yanı dürüyor; hani her şey parlak görünür ya, burada o kadar da cilalı değil.
Birincisi, Global Training bölge listesine bakınca Türkiye’ye yakın seçenekler görüyorsunuz ama hâlâ UAE North ya da Qatar Central gibi Orta Doğu bölgeleri yok. Bazı müşteriler için bu küçük bir detay değil, çünkü veri residency işi bazen bütün mimariyi baştan aşağı değiştiriyor (ve açık konuşayım, bu tarafta “idare eder” demek pek yetmiyor).
Kendi deneyimimden konuşuyorum, İkincisi, model grader’ların tutarsız davranması. Microsoft bunu zaten kabul ediyor. “deterministik grader’ları tercih edin” diyor, tamam; ama pratikte birçok görevde deterministik grader yazmak öyle kolay bir iş değil. Kalibrasyon tarafı, confidence scoring tarafı, bunlar da henüz tam oturmuş değil. Kağıt üstünde fena durmuyor, sahada işe biraz daha pişmesi gerekiyor.
Üçüncüsü — ve burada ben de biraz duraksadım — RFT hâlâ sadece belli modellerde çalışıyor. Supervised fine-tuning ile yan yana koyunca model desteği daha dar kalıyor. Yanı iş görüyor, ama genişlik arıyorsanız eliniz biraz sıkışıyor; umarım önümüzdeki aylarda liste uzar.
Ha bu arada, Azure MCP Server 2.0: Kendi Sunucunuzda Ajan Otomasyonu yazımda anlattığım ajan mimarileriyle birlikte düşününce, fine-tuned o4-mini modellerini ajan workflow’larının içine sokmak baya iyi bir kombinasyon olabilir. Reasoning tarafı güçlü, maliyet tarafı düşük; ajansal senaryolar için tam ortada duran bir seçenek gibi geliyor bana.
Pratikte İlk Adımlar
Şöyle ki, Tamam, teori kısmını geçelim (inanın bana). Denemek istiyorsanız, işin aslı ne yapacaksınız?
- Azure OpenAI kaynağınızın Global Training destekleyen bir bölgede olduğuna bakın. Değilse, yeni bir kaynak açmanız gerekecek.
- En az 50 örnekten oluşan bir eğitim seti hazırlayın. Her örnekte bir prompt ve ona karşılık gelen referans cevap olsun. — ciddi fark yaratıyor
- İşe basit bir string_check grader ile başlayın. İlk sonuçlara bir bakın, sonra karar verin.
- Eğer deterministik grader yetmezse, GPT-4.1-nano ile model grading tarafını deneyin. Bazen orada daha iyi sinyal alıyorsunuz.
- Sonuçları yan yana koyun, gerekirse grader’ı ve veriyi adım adım iyileştirin. Hani sihirli değnek yok, biraz iterasyon gerekiyor.
Bir de ChatGPT ile Araştırma: Search ve Deep Research Rehberi yazıma göz atmanızı öneririm — grader prompt’larını tasarlarken araştırma yeteneklerini nasıl kullanacağınız konusunda epey fikir verebilir, hatta beklemediğiniz birkaç noktayı da fark ettirebilir.
Bir şey dikkatimi çekti: Neyse, uzatmayalım. Bu Nisan güncellemesi tek başına devrim gibi durmuyor; ama doğru tarafa atılmış sağlam bir adım bence. Neyse, en çok da Global Training’in maliyeti aşağı çekmesi ve yeni grader seçenekleri, RFT’yi daha erişilebilir hâle getiriyor. Ben önümüzdeki haftalarda birkaç müşteri projesinde bunları daha detaylı test edeceğim; sonuçlar şaşırtırsa ayrıca paylaşırım.
Sıkça Sorulan Sorular
Global Training ile Standard Training arasındaki fark ne?
Global Training, fine-tuning işini birden fazla Azure bölgesinden başlatmanıza izin veriyor ve aslında per-token eğitim maliyeti Standard’a göre daha düşük. Model kalitesi ve altyapı aynı, yanı sadece erişim noktası ve fiyatlandırma değişiyor. Bölge kısıtlaması yaşayan ekipler için bence gerçekten büyük bir kolaylık bu.
Model grader mı kullanayım, deterministik grader mı?
Açıkçası varsayılan olarak her zaman deterministik grader’ı (string match, Python script) tercih edin — daha hızlı, daha ucuz. Tekrarlanabilir. Model grader’lara sadece açık uçlu, subjektif ya da çok boyutlu değerlendirme gerektiren görevlerde başvurun. Peki bunu neden söylüyorum? İkisini hibrit kullanmak da aslında çok etkili bir strateji, tecrübeme göre işe yarıyor.
RFT için en az kaç eğitim örneği lazım?
Kısacası, microsoft’un önerisi en az 50 örnek. Ama benim tavsiyem şu: 50 ile başlayın, sonuçlara bakın, sonra iteratif olarak 100-200’e çıkarın. Örneklerin zorluk dağılımına dikkat edin — hepsi çok kolay ya da çok zor olmasın, yanı biraz karışık olsun.
GPT-4.1-nano grader olarak işe yarar mı?
Basit kalite kontrolü ve ön filtreleme için gayet yeterli, mesela ilk geçişlerde iyi iş çıkarıyor. Ama karmaşık rubric’leri doğru yorumlama kapasitesi GPT-4.1’e göre düşük kalıyor. E peki, sonuç ne öldü? Büyük veri setlerinde maliyet avantajı ciddi — o yüzden ilk geçiş için nano kullanıp detaylı değerlendirmeyi mini veya full modelle yapmak bence mantıklı bir strateji.
Türkiye’ye en yakın Global Training bölgesi hangisi?
Şu an France Central, Germany West Central ve Switzerland North en yakın seçenekler. Latency açısından aslında büyük fark yok çünkü eğitim işi asenkron çalışıyor — ama monitöring (en azından benim deneyimim böyle). Dosya yükleme sırasında yakın bölge yine de avantaj sağlıyor.
Kaynaklar ve İleri Okuma
What’s New in Microsoft Foundry Fine-Tuning | April 2026 — Resmî Blog Yazısı
Azure OpenAI Fine-Tuning Resmî Dokümantasyonu
Reinforcement Fine-Tuning (RFT) Kavramları — Microsoft Learn

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.















4 comments