PostgreSQL’de Yeni Dönem: Commit’ten Buluta Uzanan Yol
PostgreSQL niye hâlâ oyunun içinde?
İşin aslı, PostgreSQL uzun zamandır sadece “iyi bir açık kaynak veritabanı” değil; modern uygulamaların arka plandaki omurgası gibi çalışıyor. Küçük bir startup da olsanız, bankacılık tarafında yüz binlerce eşzamanlı işlemi de taşısanız, aynı çekirdek mantık sizi ayakta tutuyor: doğruluk, genişletilebilirlik ve sağlam bir topluluk.
Ben bu yapıyı ilk kez 2000’lerin sonuna doğru bir hosting ortamında kurcaladığımda, açık söyleyeyim, MySQL’den farkını kağıt üstünde anlatmak kolaydı (şaşırtıcı ama gerçek). Pratikte hissettirdiği şey bambaşkaydı. En çok da karmaşık sorgular, transaction davranışı ve veri bütünlüğü konusunda PostgreSQL’in “ben buradayım” dediği anlar oluyor (yanlış duymadınız). Hani bazen bir sistem iyi çalışır ama baskı artınca dağılıverir ya… Postgres öyle değil. Sınanmayı seviyor gibi.
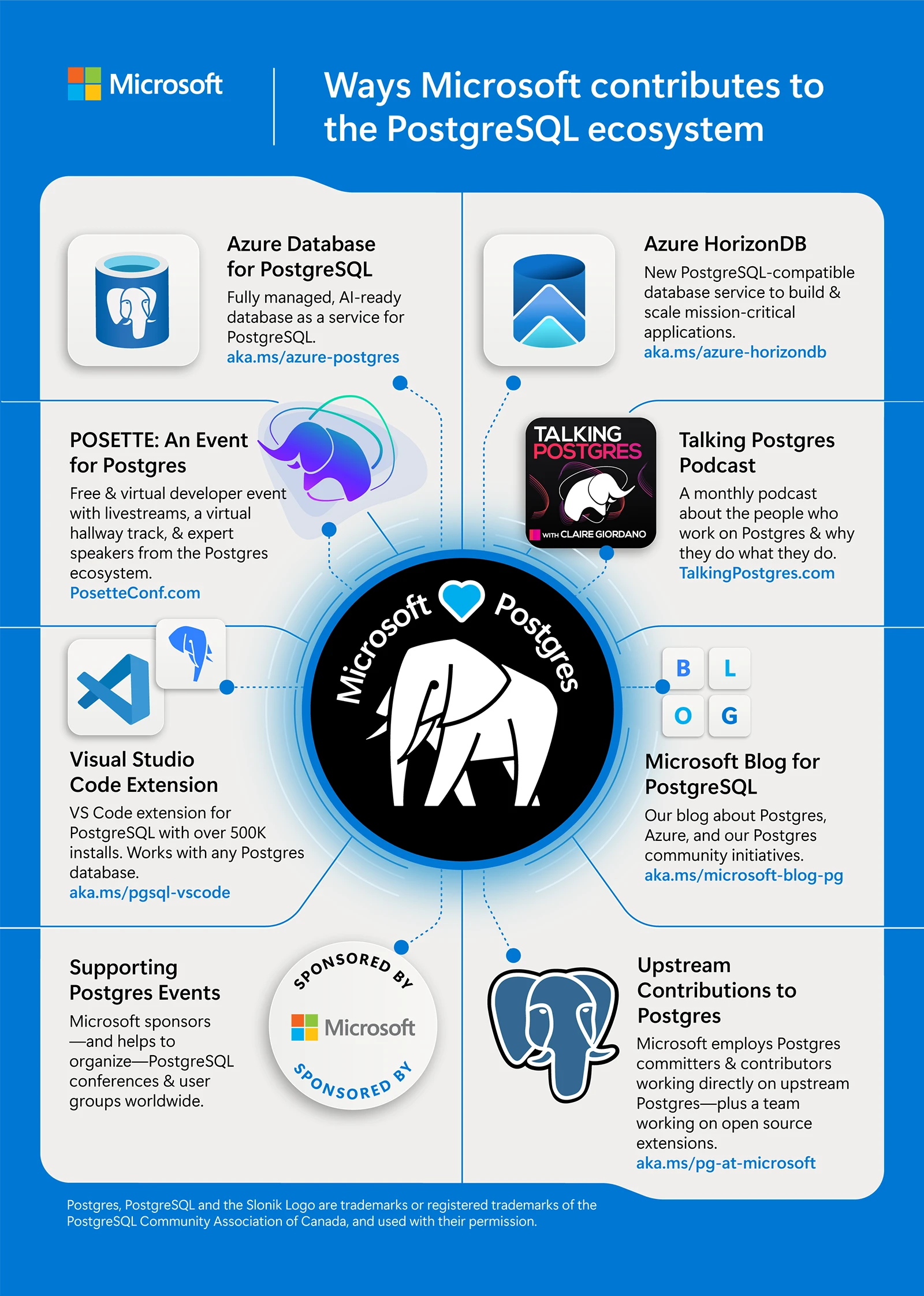
Microsoft’un son dönemde PostgreSQL’e ciddi yatırım yapması da boşuna değil. 345 commit gibi rakamlar dışarıdan güzel görünüyor. Daha önemli olan şey şu: upstream projeye doğrudan dokunmak, yanı sadece servis satmak değil, çekirdeğin pişmesine de katkı vermek. Bu bana 2023’te İstanbul’da görüştüğüm bir perakende müşterisini hatırlattı; ekip “managed servis alalım mı yoksa kendimiz mi yöneteceğiz” diye gidip geliyordu. Sonunda gördüler ki asıl mesele maliyet değil, operasyonel yük ve hata toleransıydı.
Bulut çağında veritabanından beklenti değişti
Açıkçası, Eskiden veritabanı denince akla sadece kayıt saklamak gelirdi. Şimdi öyle değil. Veri artık karar verdiriyor, öneri sunuyor, arama yapıyor, hatta ajanlara zemin hazırlıyor. Bir anda veritabanı rafın arkasındaki kutu olmaktan çıkıp uygulamanın beynine yakın bir yere oturdu.
Garip gelecek ama, Geçen sene Ankara’da bir finans kuruluşuyla yaptığımız görüşmede bunu çok net gördüm. Ekip klasik OLTP işlerini yürütüyordu ama aynı anda müşteri davranışına göre skor üretmek istiyordu (eh, fena değil). İşte burada SQL ile AI dünyasının birbirine yaklaşması kritik hâle geliyor. Vector search ayrı yerde dursun, transaction data ayrı yerde dursun demek artık biraz eski kafalı kalıyor.
Aslında — dur bir saniye — önce şunu söyleyeyim: herkes “AI için en yeni araç hangisi” diye soruyor ama çoğu projede asıl kazanç veri katmanını doğru kurgulamakta geliyor. PostgreSQL’in güzelliği de burada; extensibility sayesinde aynı sistemde hem klasik ilişkisel yapı hem de AI’ya göz kırpan özellikler kullanılabiliyor.
PostgreSQL’i farklı yapan şey yalnızca performans değil; değişen iş yüklerine uyum sağlayabilmesi. Bugün transactional işler için kullanırsınız, yarın aynı omurgada vektör arama ya da model çağrısı yaparsınız.
Microsoft neden bu kadar içeri girdi?
Vallahi, Açık konuşayım, Microsoft’un PostgreSQL tarafındaki hamlesi bana yıllar önce Azure SQL çevresinde verdiği dersleri hatırlatıyor: müşteri neyi kullanıyorsa oraya gitmek gerekiyor. Kurumsal dünyada “bizim ürünümüz en iyisi” demek yetmiyor; insanların gerçekten kullandığı teknolojiye değer katmanız lazım.
Şöyle ki, Ben AZ-305 hazırlığı yaparken mimarı sorularda hep aynı yere takılırdım: “Bu çözüm neden yönetilebilir?” Cevap çoğu zaman şuydu —. Mevcut ortame yakın dürüyor. Microsoft’un PostgreSQL’e yatırımını da böyle okuyorum. Sadece Azure Database for PostgreSQL’i büyütmek değil mesele; upstream’e dokunup pek çok çevrei itmek daha stratejik bir hareket.
Kısa bir not düşeyim buraya.
Bir de şu var: kurumsal müşterilerde güven konusu çok ağır basıyor. Telekom sektöründe 2024 başında görüştüğüm bir ekip açık kaynak kullanımına sıcak bakıyordu ama tek endişeleri “yarın kim destek verecek?” idi. Managed service + upstream katkı + çevre desteği birleşince tablo daha ikna edici hâle geliyor.
Commit sayısı tek başına hikâye anlatmaz
Evet, commit sayısı dikkat çeker. Ama gerçek değer o commit’in hangi problemi çözdüğünde yatıyor. Asenkron I/O iyileştirmeleri ya da vacuum davranışları gibi konular dışarıdan sıkıcı görünür; içeride işe tam anlamıyla hayat kurtarır.
Bunu kendi laboratuvarımda da yaşadım. 2019’da evdeki test sunucumda benzer bir yoğunluk senaryosu kurmuş. Checkpoint/vacuum dengesini bozmuştum; sonuç? Disk I/O yükseldi, gecikme fırladı ve ben “bu niye böyle öldü şimdi” diye ekran karşısında kaldım… Sonra küçük ayarların büyük etkisini tekrar gördüm.
AI ile Postgres yan yana gelince neler değişiyor?
Bakın şimdi, esas kırılma burada başlıyor. Veritabanı artık sadece satır döndüren makine değil; AI akışının parçası oluyor. Vektör veri ile klasik SQL filtresinin birlikte çalışması kulağa hoş geliyor çünkü pratikte de işe yarıyor. Daha fazla bilgi için Kubernetes v1.36: Mixed Version Proxy ile Yükseltme Korkusu Azalıyor yazımıza bakabilirsiniz.
Küçük ekipseniz bu size hız kazandırır. Ayrı ayrı servisler kurup birbirine bağlamak yerine tek platform üzerinde ilerlersiniz; daha az entegrasyon kablosu, daha az baş ağrısı… Büyük enterprise yapılarda işe konu biraz farklıdır: güvenlik ayrımı, ağ segmentasyonu. Uyumluluk gereksinimleri devreye girer. Yanı her iş yükünü tek sepete atmak doğru olmaz.
| Senaryo | Küçük ekip | Büyük kurumsal yapı |
|---|---|---|
| Aynı DB’de AI + OLTP | Daha hızlı prototip | Sınırlı alanlarda mantıklı |
| Ayrık servis mimarisi | Fazla operasyon yükü | Daha kontrollü ve güvenli |
| Maliyet | Düşük başlangıç maliyeti | Büyüdükçe optimizasyon şart |
| Yönetim modeli | Tamamını dışarı vermek rahatlatır | Governance zorunlu olur |
İşin garibi, Neyse uzatmayalım: benim görüşüm şu yönde — AI özellikleri güzel ama henüz ham sayılırlar. Üretimde kullanacaksanız önce dar kapsamda deneyin, sonra yaygınlaştırın. Kağıt üstünde süper duran şeylerin saha testinde beklediğiniz kadar pürüzsüz çıkmadığını defalarca gördüm.
Maliyet mi? Yönetim mi? İkisini de konuşmak lazım
İtiraf edeyim, Bence Türkiye’de şirketlerin en sık yaptığı hata şu: teknoloji seçimini sadece lisans fiyatıyla değerlendirmek. Oysa TL bazında bakınca asıl masraf çoğu zaman operasyonel emek oluyor; gece alarmına kim kalkacak, yedekleme kimin sorumluluğunda olacak, failover senaryosunu kim test edecek? Bunlar görünmez giderler. Bu konuyla ilgili .NET 11 Preview 4: Sessiz Ama Dolu Gelen Sürüm yazımıza da göz atmanızı tavsiye ederim. Bu konuyla ilgili Azure DevOps Server Mayıs Yamaları: Neyi, Neden, Nasıl Kontrol Etmeli? yazımıza da göz atmanızı tavsiye ederim.
Durun, bir saniye.
E tabi startup tarafında durum farklı olabilir. Eğer iki kişilik ürün ekibisiniz ve hızlı MVP çıkaracaksanız managed hizmet baya iş görüyor. Ama on-prem alışkanlığı güçlü büyük kurumlarda migration planını aceleye getirmek yanlış olur; adım adım geçmek lazım.
# Basit düşünce modeli
1) İş yükünü tanımla
2) RPO/RTO beklentisini netleştir
3) Yönetilen servis mi self-managed mi karar ver
4) İzleme ve yedeklemeyi ilk günden aç
5) Yük testi yapmadan prod'a çıkma
Kötü deneyim de anlatalım bari
Bunu ilk denediğimde küçük bir izin hatası aldığımı hâlâ hatırlıyorum: bağlantı vardı ama extension kurulumu patlıyordu çünkü rol yetkileri eksikti. Çözüm basitti aslında — kullanıcıya gerekli yetkiyi verdik. Yeniden denedik — fakat o ilk saat insanın moralini biraz bozuyor. Güzel özellik ama biraz pişmesi gerek işte.
Sahada benim gördüğüm üç pratik ders
Cömert olmayan mimariyi zorlamayın. Yanı her şeyi tek node’a bindirmeyin diyeceğim ama zaten biliyorsunuzdur; yine de tekrar etmekte fayda var. Postgres ölçeklenir fakat ölçeklenme şekli iş yüküne göre değişir.”
Oops—burada toparlayayım: read-heavy sistemlerde replikasyon başka türlü konuşulur,write-heavy işlerde partitioning ya da tasarım revizyonu gündeme gelir. Her çözümü aynı tornavidayla sıkmaya kalkarsanız ipucu kaçırırsınız.”
- Lafı gevelemeden söyleyeyim: önce veri modelini düzeltin. — ciddi fark yaratıyor
- Sorgu planlarını izlemeden index yağmuruna başlamayın.
- Müşteri işi kritikse backup restore testini canlıya çıkmadan yapın.
NL2SQL’de Asıl Soru: Prompt mu, Veritabanı mı? Bu konuyla ilgili Python ile Teams SDK artık GA: Benim Sahada Gördüklerim yazımıza da göz atmanızı tavsiye ederim. Microsoft Foundry Nisan 2026: Üretimde Dikkat Çeken Yenilikler yazımızda bu konuya da değinmiştik.
Microsoft SQL ile Agentic AI Güvenliği: Katman Katman Savunma
Bence nerede iyi çalışır?
Kurum içinde standart raporlama varsa ve üstüne biraz AI dokunuşu gelecekseniz bu yaklaşım bayağı mantıklı. Hele bir de hybrid senaryolarda Azure tarafının elinizin altında olması rahatlatıyor.
Nereden başlamalı?
Denenmek istiyorsanız ilk işiniz pilot kapsam belirlemek olsun. Tek seferde tüm üretimi taşımaya kalkmayın; küçük başlayın,ölçün,sonra büyütün. Bu sırayı birkaç müşteride bilerek bozduklarında sorun yaşadılar—özellikle compliance ağırsa.
- Kritik olmayan bir veri kümesi seçin.
- Sorgu gecikmesini. Maliyeti izleyin.
- Yedekten geri dönüş süresini ölçün.
- Erişim modellerini sade tutun.
Sıkça Sorulan Sorular
PostgreSQL neden bu kadar popüler öldü ki?
Aslında birkaç şeyin bir araya gelmesiyle öldü bu. Veri bütünlüğüne çok ciddi bakıyor, genişletmesi kolay ve açık kaynak ekosistemi gerçekten güçlü. Üstüne bir de cloud-native dünyaya gayet iyi uyum sağlıyor — bence bu son nokta yeni projelerde bu kadar tercih edilmesinin asıl sebebi.
Şimdi gelelim işin can alıcı noktasına.
Ana üretim verisi için Azure Database for PostgreSQL işe yarar mı?
Küçük bir detay: Yanı çoğu senaryoda bana kalırsa yarar. Şimdi, en çok da yönetim yükünden kurtulmak istiyorsanız, açıkçası çok iyi bir seçenek. Ama şunu da atlamamak lazım: performans, güvenlik ve yedeklilik ihtiyaçlarınıza göre doğru SKU’yu seçmek şart, yoksa sonradan baş ağrısı olabiliyor.
PostgreSQL ile AI özelliklerini aynı anda kullanmak mantıklı mı?
Aslında, Küçük ve orta ölçekli projelerde? Tartışmasız mantıklı. Veriyi dağıtmadan hızlıca prototip çıkarabiliyorsunuz, hani tek yerden hallediyorsunuz her şeyi. Ama büyük kurumsal yapılarda mesela güvenlik, uyumluluk (ki bu çoğu kişinin gözünden kaçıyor). Izolasyon gereksinimleri devreye giriyor — o zaman tasarımı biraz daha dikkatli yapmak gerekiyor tecrübeme göre.
Kendi sunucumda mı tutayım, managed service mi kullansam?
Ekip küçükse managed service genelde çok daha rahat ediyor, bence büyük çoğunluk için doğru başlangıç noktası bu. Büyük organizasyonlarda işe iş biraz değişiyor — özel ağ, özel politika ya da regülasyon gibi durumlar çıkıyor ortaya, o zaman hibrit bir yaklaşım daha doğru olabiliyor.
Kaynaklar ve İleri Okuma
Dürüst olmak gerekirse, Orijinal Azure Blog Yazısı (ciddiyim)
Azure Database for PostgreSQL Resmî Dokümantasyonu
PostgreSQL GitHub Deposu (Upstream Kaynak)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











2 comments