Model Router Evals: Doğru Modeli Seçtiğini Nasıl Kanıtlarsın?

Bir model router fikri ilk anda baya çekici geliyor: tek uç nokta, arkada bir sürü model, sistem de gelen prompt’a göre en uygun olanı seçiyor. Kağıt üstünde temiz dürüyor. Pratikte işe iş biraz daha kirli; çünkü mesele sadece “doğru cevap” değil, aynı zamanda maliyet, gecikme, uyumluluk ve ekiplerin buna ne kadar güvendiği.
Ben bu tip seçim problemlerini yıllardır farklı yerlerde gördüm. 2018’de bir hosting müşterisinde trafik pik yapınca “en güçlü sunucu” yaklaşımının bazen yanlış karar olduğunu fark etmiştik; çünkü her iş yükü aynı kaş gücünü istemiyor. Şimdi aynı mantık LLM tarafında karşımıza çıkıyor. Model router da tam burada devreye giriyor: her işi aynı modele yıkmak yerine işi bölüyor.
Kısa bir not düşeyim buraya.
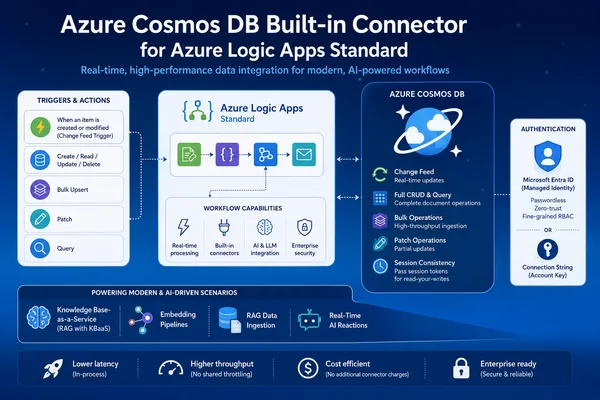
Bu yazıda, Foundry içindeki model router için eval nasıl koşulur ona kendi gözümden bakacağım. Kaynak yazıdaki akışı birebir takip etmeyeceğim; zaten gerek de yok. Asıl soru şu: Router gerçekten para kazandırıyor mu, kaliteyi düşürüyor mu, yoksa sadece “akıllı görünüp” arkada başka bir maliyet mi çıkarıyor?
Neden Router’ı Ölçmeden Kullanmak Riskli?
Bir şey dikkatimi çekti: Bakın şimdi, üretimde bir şeyi ölçmeden kullanmaya başlamak genelde pahalıya patlıyor. Model router’da da durum farklı değil. Mesela büyük kurumsal yapılarda “Balanced” ya da “Quality” seçip geçmek kolay geliyor ama sonra biri çıkıp soruyor: Bu seçim bizim compliance sınırlarımızla uyumlu mu? Peki latency ne öldü? Hangi model kaç kez seçildi?
Peki neden?
Geçen sene Kasım 2024’te bir finans kurumunda yaptığımız PoC’de benzer bir durum yaşadık (buna dikkat edin). Ekip önce tek modelle ilerliyordu, sonra router’lı mimariye geçti. İlk hafta herkes mutlu öldü çünkü cevap kalitesi fena değildi. İkinci hafta FinOps ekibi geldi ve “güzel de, toplam spend niye beklediğimiz kadar düşmedi?” diye sordu. İşin aslı şu ki, routing katmanının kendi maliyeti var; üstüne alt model fiyatları eklenince tablo biraz değişiyor.
Bir de şunu söyleyeyim: küçük startup ile enterprise arasında yaklaşım aynı olmuyor. Startup iseniz hızla denersiniz, hızlı karar verirsiniz, hatta bazen hata payını göze alırsınız. Ama enterprise ortamda bir router’ın hangi modele ne zaman gittiğini kanıtlamanız gerekir. Ben AZ-305’e hazırlanırken bile hep şunu düşünürdüm: mimarı iyi görünmek zorunda değil, savunulabilir olmak zorunda.
Durun, bir saniye.
Evals Ne Ölçüyor, Ne Ölçmüyor?
Foundry’nın kendi kurumsal değerlendirme araçları. Var; bu açık kaynak repo işe daha erken aşamada elinizi rahatlatıyor. Yanı henüz sistemi production’a bağlamadan önce hızlı ve savunulabilir bir cevap istiyorsanız bayağı işe yarıyor. Ama açık konuşayım: bu tür eval’lar her şeyi çözmez. En çok da domain’e özgü doğruluk ya da kullanıcı deneyimi gibi şeyleri yalnızca otomatik metriklere bırakırsanız eksik kalır. Copilot CLI’yi Telefondan Yönetmek: Benim Sahada Gördüğüm Etki yazımızda bu konuya da değinmiştik.
Repo’nun güzel tarafı üç ana boyutu aynı anda ele alması: kalite, maliyet ve gecikme. Üstelik bunu router’ın seçtiği gerçek modele göre yapıyor; yanı teorik değil, fiili davranışa bakıyorsunuz. Bu önemli çünkü bazen Balanced modda güzel sonuç alıyorsunuz ama gerçekte dağılım beklediğinizden farklı oluyor… işte orada sürpriz çıkıyor. Daha fazla bilgi için Copilot Spaces API GA: Kurumsal ekipler için gerçek fark ne? yazımıza bakabilirsiniz.
Router eval’larında asıl oyun sadece “cevap doğru mu?” sorusu değil; “bu doğruluk bize hangi fiyata geldi?” sorusu.
Kendi Deneyimimden Üç Küçük Uyarı
İlk uyarı şu: Routing kararları metin odaklıdır. Görsel kabul edilse bile resimler routing kararını etkilemez; ses tarafı da yok zaten. Geçen ay Mart 2026’da bir medya şirketiyle konuşurken ekip görüntülü prompt’ların modeli etkilediğini varsayıyordu — etkilemiyormuş gibi düşünmek daha doğru çıktı.
İkinci uyarı bölgesel kısıtlar. Şu an East US 2. Sweden Central gibi bölgelerle sınırlı deployment senaryoları varmış gibi düşünün; yanı globalde her yerde hazır bekleyen sihirli bir servis değil bu. Türkiye’deki kurumlar açısından bakınca bu durum iki sebeple önemli: veri yerleşimi ve gecikme algısı. Kullanıcı İstanbul’da ama inference Stockholm’den dönüyorsa kağıt üstündeki latency ile hissedilen latency farklı olabiliyor.
Tuhaf ama, Üçüncü uyarı Claude tarafında ayrı deployment gerekliliği. Bir müşteri geçen yıl Eylül 2025’te bana “router. Her şeyi bilir” dediğinde gülmemek için kendimi zor tuttum (iyi niyetle tabiî). Mantıklı değil mi? Hayır, bazı modeller için ayrı hazırlık gerekiyor; aksi hâlde routing zinciri eksik kalıyor. Bu konuyla ilgili .NET ve .NET Framework Mayıs 2026 Güncellemeleri: Ne Değişti? yazımıza da göz atmanızı tavsiye ederim.
Maliyet Hesabı Neden Bu Kadar Kritik?
Maliyet kısmında insanın kafası çabuk karışıyor çünkü yalnızca alt modelin token fiyatına bakmak yetmiyor; router’ın input-prompt markup’ını da katmanız lazım. Ben bunu basitçe şöyle anlatıyorum: restorana gidip ana yemeğin fiyatına bakmak yetmez, servis ücreti de var mı ona bakarsın. .NET 11’de Process API’si Neden Bu Kadar Önemli? yazımızda bu konuya da değinmiştik.
Küçük ekipseniz ve kullanım hacminiz düşükse bazı karmaşıklıkları tolere edebilirsiniz. Ama enterprise ölçekte aylık binlerce çağrı varsa küçük görünen farklar bütçede ciddi oynar hâle geliyor. Bir bankacılık projesinde Şubat 2026’da yaptığımız analizde yalnızca %8 civarı iyileşme bile ay sonu raporunda fark yaratmıştı.
| Kriter | Küçük Startup | Enterprise |
|---|---|---|
| Ana hedef | Hızlı doğrulama | Savunulabilir karar |
| Evals derinliği | Orta seviye yeter | Kapsamlı benchmark şart |
| Maliyet hassasiyeti | Düşük-orta | Çok yüksek |
| Compliance ihtiyacı | Daha esnek olabilir | Sert kontrol gerekir |
Evals Nasıl Koşulur? Pratik Akış Ne?
Neyse uzatmayalım, pratik akış aslında oldukça temiz görünüyor:
- Eval repo’şunu indirip örnek veri setini inceleyin.Kendi prompt set’ınızı hazırlayın; mümkünse üretim trafiğinden anonimleştirilmiş örnekler kullanın.Aynı run içinde kalite, maliyet ve latency metriklerini birlikte ölçün.Router’ın hangi alt modellere dağıldığını mutlaka raporlayın.Birkaç farklı subset ile testi tekrarlayın; özellikle compliance sınırlaması varsa.
Bence en kritik nokta veri setinin kalitesi. Eğer test girdileriniz çok steril işe sonuçlar sizi kandırır… İlginç, değil mi? gerçek hayat öyle işlemiyor çünkü kullanıcı prompt’u bazen yarım cümle oluyor, bazen içinden emoji fırlıyor, bazen de görev tanımı beş satır uzuyor ve ortasında konu değiştiriyor.
# Basit düşünce modeli if quality_gain > cost_increase and latency_ok: use_router = True else: use_router = False # Gerçek hayatta bunu tek başına böyle bırakmayın; # subset policy + compliance + region + quota da işin içine girer.Llm-as-a-Judge Tarafında Dikkat Edilecek Şeyler
Garip gelecek ama, Açıkçası judge scoring tarafını seviyorum ama kör güvenmemek gerekiyor. Dual-ordered pairwise yaklaşımı pozisyon bias’ını azaltıyormuş; iyi haber bu. Yine de özellikle Türkçe gibi dillerde veya domain jargonunun ağır olduğu alanlarda jüri modeli bazen lafın özünü kaçırabiliyor. Copilot cloud agent ile Kırık Actions İşini Tek Tıkta Çözmek yazımızda bu konuya da değinmiştik.
Bunu ilk kez Mayıs 2025’te bir telekom müşterisinde gördüm. Aynı cevabı iki sırada verince skor hafif oynuyordu… ufak ama can sıkıcıydı yanı artık buna şaşırmıyorum bile.
Türkiye’de Bu Yapının Karşılığı Ne Olur?
‘
Bence Türkiye’de en büyük farklardan biri satın alma refleksiyle ilgili. Kurumlar çoğu zaman önce — ki bu tartışılır — lisans/servis fiyatına bakıyor ama AI projelerinde asıl mesele toplam sahip olma maliyeti oluyor (TCO deyince bazı ekiplerin gözü korkuyor ama korkmasın). Router eval tam burada değer veriyor çünkü size soyut vaat yerine somut karşılaştırma sunuyor.
Kısıtlı Bütçe İçin Alternatif Yol Var mı?
‘
Evet var! Eğer bütçe dar işe bütün trafiği doğrudan router’a taşımak yerine önce belirli workload’larda pilot açın mesela destek botu ya da iç bilgi asistanı gibi düşük riskli alanlarda başlayın. Sonra üretim benzeri yüklerde benchmark alın. Azure maliyetleri TL’ye vurunca küçük görünen kullanım artışı bile etkili olabiliyor;
Bazı ekipler benden doğrudan en pahalı modeli öner diyor ama ben çoğu zaman bunun tersini söylüyorum: önce orta segment modeli alın, sonra gerçekten gereken yerde yükseltin. Çünkü iyi tasarlanmış routing bazen pahalı modeli hiç çağırmadan işi çözüyor… güzel his!
Bence En Doğru Başlangıç Planı Şu Olmalı
‘
- Trafiği sınıflandırın: kısa soru mu uzun analiz mi? — bunu es geçmeyin
- SLA tanımlayın: gecikme mi kalite mi öncelikli?
- Pilot veri seti oluşturun: gerçek örnekleri anonimleştirin.
- Metrikleri sabitleyin: quality-per-dollar ve quality-per-second birlikte izleyin.
Ana tavsiyem şu: ilk gün mükemmel pipeline kurmaya uğraşmayın (buna dikkat edin). Önce dürüst ölçün. Sonra optimize edin. Ben Azure DevOps Server yamalarını kontrol ederken de hep aynı zihniyeti kullanıyorum—önce risk görünür olsun, sonra çözersiniz.
Sıkça Sorulan Sorular
Model router ne iş yapıyor?
Aslında işi basit: gelen prompt’a bakıp en uygun LLM’i seçmeye çalışan bir yönlendirme katmanı. Ama sihir değil tabiî; yanı veri, politika ve kısıtlarla çalışıyor.
Neden eval yapmak gerekiyor ki?
Açıkçası, router’ın size gerçekten fayda sağladığını kanıtlamak istiyorsanız eval şart. Kaliteyi, maliyeti ve latency’yi birlikte görmeden karar vermek pek sağlam olmuyor bence.
Tüm modelleri aynı anda test etmek zorunda mıyım?
Size bir şey söyleyeyim, Zorunlu değil. Ama etraflı bir kıyas yapmak istiyorsanız iyi bir fikir. Mesela subset politikaları varsa, birkaç varyasyonu yan yana görmek çok işe yarıyor — tecrübeme göre bu adımı atlamamak daha iyi.
Küçük ekipler bu repo’dan faydalanabilir mi?
Bunu yaşayan biri olarak söyleyeyim, Evet, hatta bazen en çok onlar faydalanıyor. Çünkü hızlı karar vermeleri gerekiyor; yanı açık kaynak pipeline onları kurumsal araçlara bağımlı bırakmadan ilerletiyor. Bence bu en büyük avantajı.
Kaynaklar ve İleri Okuma
Microsoft DevBlog Orijinal Yazı – How to run evals for the model router
Azure AI Foundry Resmî Dokümantasyonu
Microsoft GitHub Depoları

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











4 comments