Kubernetes v1.36’da PSI GA: Sinyali Gürültüden Ayırmak
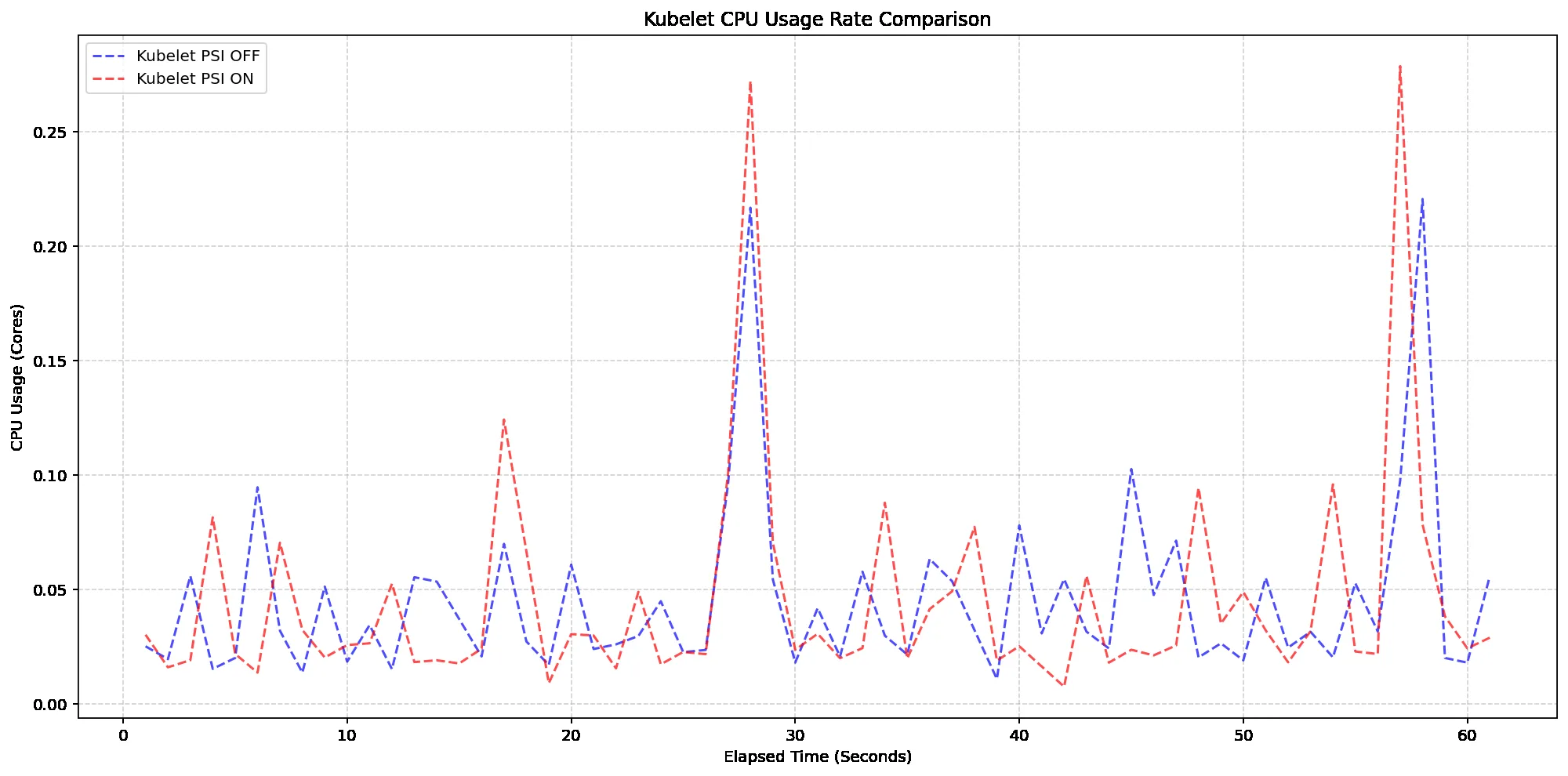
Bir Kubernetes kümesini izlerken çoğu kişinin ilk baktığı şey CPU yüzdesi oluyor. Hani şu klasik grafik… %60, %70, %80. Güzel görünüyor ama işin aslı şu ki, o rakam tek başına pek bir şey anlatmıyor. Geçen yıl Mart 2025’te bir finans müşterisinde bunu birebir yaşadık: node’lar “rahat” görünüyordu,. Pod tarafında istekler — kendi adıma konuşayım — yavaşlıyor, zaman aşımı artıyor, kullanıcı da doğal olarak şikâyet ediyordu. Sonradan anladık ki mesele kullanım değil, baskıydı.
Vallahi, İşte PSI tam bu noktada devreye giriyor. Pressure Stall Information, yanı sistemin ne kadar süreyle beklediğini ve hangi kaynakta sıkıştığını gösteren sinyal. CPU dolu mu, bellek nefes alamıyor mu, I/O kuyruğu uzamış mı (en azından benim deneyimim böyle). bunları yüzdelerle anlatıyor. Kubernetes v1.36 ile bu veri artık GA seviyesinde daha güvenilir bir kapıdan sunuluyor (kendi tecrübem). Açık konuşayım, bu küçük gibi görünen bir adım ama operasyon tarafında bayağı büyük etkisi var.
Benim hoşuma giden taraf şu: PSI, “kullanım” ile “sıkışma” arasındaki farkı netleştiriyor. Bulut dünyasında bu ayrım altın değerinde (kendi tecrübem). Çünkü bazen %40 CPU kullanıyorsunuz ama scheduler gecikmesi yüzünden uygulama sürünüyor; bazen de bellek tarafında ufak bir gerilim var. Sistemin tadı kaçıyor. Kağıt üstünde süper görünen metrikler pratikte yetmeyince olay başka yere gidiyor işte.
Evet, doğru duydunuz.
Neden kullanım metriği yetmiyor?
İlginç olan şu ki, Az önce dedim ya, yüzde grafikleri çoğu zaman kandırıcı olabiliyor. Bir makineyi düşünün; CPU ortalaması düşük ama birkaç hayatı thread sürekli bekliyor. Bu durumda “kaynak var” sanırsınız, halbuki darboğaz başka yerde gizlenmiştir. Hele bir de yüksek yoğunluklu Kubernetes kümelerinde bu durum çok görülüyor.
2019’da kendi labor ortamımda benzer bir senaryo kurmuştum; o dönem klasik node exporter metrikleriyle her şeyi izlediğimizi sanıyorduk. Sonra bir test sırasında pod başlangıç süreleri saçma şekilde uzadı. Meğer problem CPU kapasitesi değilmiş, disk I/O kuyruklarıymış (şaşırtıcı ama gerçek). O gün anladım ki iyi gözlemleme biraz da doğru soruyu sormakla ilgili.
Bence, PSI’nın güzel yanı burada ortaya çıkıyor: size sadece “ne kadar kullandım” demiyor, “ne kadar bekledim” de diyor. Mesela memory pressure yükseliyorsa belki GC baskısı vardır; I/O pressure artıyorsa log yazımı veya veri katmanı tökezliyordur. Yanı olay sadece sıcaklık ölçmek değil, ateşin nerede çıktığını bulmak.
Bakın, burayı atlarsanız yazının kalanı anlamsız kalır.
Bir de şu var: startup ile enterprise aynı sorunu aynı şekilde yaşamıyor. Küçük ekiplerde genelde sorun hızlı fark ediliyor çünkü trafik az ve topoloji sade oluyor. Kurumsal yapılarda işe gürültü çok daha fazla; onlarca namespace, farklı node pool’lar, değişik SLA’lar… İşte orada PSI baya işe yarıyor çünkü sinyali temiz veriyor.
Kubernetes v1.36 ile ne değişti?
Kubernetes tarafında en sevdiğim gelişmelerden biri hep şu öldü: kernel’in. Bildiği bilgiyi kubelet üzerinden daha düzgün taşımak. v1.36 ile PSI’nın GA seviyesine çıkması tam da böyle bir his veriyor. Linux kernel uzun zamandır bu veriyi tutuyordu; Kubernetes şimdi bunu daha düzenli ve üretime uygun hâle getiriyor.
Durun, bir saniye.
Araya gireyim: Bu geçişi Azure perspektifinden düşündüğümde şunu söylüyorum: izleme tarafında stabilite bazen yeni özellikten bile kıymetli oluyor. Çünkü üretimde herkes “çalışıyor mu?” diye bakar ama asıl soru “yoğun yük altında hâlâ çalışacak mı?” olmalı. AZ-305 çalışırken de benzer mantığı hep tekrar ederiz; mimariyi sadece mutlu akışta değil, stres altında da düşünmek lazım. Microsoft Agent Framework ve AGT: Ajanları Üretimde Güvende Tutmak yazımızda bu konuya da değinmiştik.
PSI’nın asıl değeri metrik sayısını artırması değil; yanlış karar verme riskini azaltmasıdır.
(şaşırtıcı ama gerçek) Visual Studio Agent Skills: Copilot’a Takımınızı Öğretmek yazımızda bu konuya da değinmiştik.
Bence burada güzel olan şey yalnızca teknik doğruluk değil… operasyonel sadelik de geliyor yanında keşke her gözlemleme özelliği böyle olsa dediğim yerlerden biri bu öldü gerçekten.
Cumulative totals ve moving averages neden önemli?
Bak şimdi, Cumulative totals kısmı size toplam sıkışma süresini verir; moving averages işe son 10 saniye, 60 saniye ve 300 saniye içinde ne olup bittiğini gösterir. Ben bunu hep araba göstergesi gibi anlatıyorum: toplam kilometre ayrı şeydir, son beş dakikadaki hız ayrı şeydir.
E tabi burada tek başına kısa pencere yeterli olmuyor çünkü anı spike’lar sizi gereksiz alarm yağmuruna boğabilir (inanın bana). Uzun pencere de tersine gerçek sorunu saklayabilir… yanı ikisini birlikte okumak lazım.
Sahada performans testi ne söylüyor?
Kubernetes ekibinin yaptığı testlerde beni en çok ikna eden nokta overhead’in düşük çıkması öldü.Bu tarz yeni telemetry özelliklerini insanlar sever. Üretimde ekstra yük istemezler — haklılar da! SIĞ Node’un yüksek yoğunluklu test yaklaşımı burada önemliydi; 80+ pod senaryolarında Kubelet’in davranışı incelenmiş. Azure Functions’ta Retry Fırtınasını Durdurmak: Backoff ve Circuit Breaker yazımızda bu konuya da değinmiştik.
Şöyle ki, Ben Logosoft tarafında geçtiğimiz Kasım 2025’te bir telekom müşterisinde buna benzer bir değerlendirme yapmıştım.Aslında korkuları şuydu: “Bu metriği açarsak node zaten zorlanıyor, daha da kötüleşir mi?” Sonuç şaşırtıcıydı; doğru ayarlı koleksiyonun etkisi ihmal edilebilir düzeyde kaldı. Yanlış alarm eşikleri kurunca herkes panikledi… sorun çoğu zaman araçta değil eşikte oluyor. Bu konuyla ilgili NL2SQL’de Asıl Soru: Prompt mu, Veritabanı mı? yazımıza da göz atmanızı tavsiye ederim.
| Senaryo | Anlamı | Sahadaki karşılığı |
|---|---|---|
| Kernel PSI açık / Kubelet özelliği kapalı | Koleksiyon etkisini ayırır | Kerneli baz alıp kubelet yükünü ölçersiniz |
| Kernel PSI açık / Kubelet özelliği açık | Tam etkin kullanım | Gerçek üretim senaryosu gibi davranır |
| Kernel PSI kapalı / Kubelet özelliği açık | Tespit sınırı görünür olur | Sistem desteği yoksa veri gelmez |
Küçük ekip için ne yapmalı?
Eğer iki kişilik bir platform ekibiniz varsa işi basit tutun derim mesela önce node seviyesinde PSI’yı açın sonra birkaç hayatı workload için alarm belirleyin yeterli olabilir fazla karmaşa genelde faydadan çok zarar veriyor hani insan elindeki şeyi büyütmeye çalışınca yönetemez hâle gelebiliyor ya aynen öyle…
Büyük kurumsal yapı için yaklaşım nasıl olmalı?
Büyük yapılarda işe sadece açmak yetmez; namespace bazlı ayrıştırma, node pool segmentasyonu. SLO bağlantısı gerekir çünkü aynı kümeye hem batch işlerini hem müşteri trafiğini koyarsanız gürültü patlıyor benim önerim PSI’yı mevcut Prometheus/Grafana zincirine ekleyip kapasite planlama raporlarının içine sokmanız olur özellikle aylık trend analizi baya işe yarar (inanın bana)
Maliyet ve uygulama açısından gerçek hayat okuması
Açık konuşayım: yeni gözlemleme özelliğinin maliyeti çoğu zaman lisans parasından değil operasyon karmaşasından gelir Azure’da da benzer şekilde mesele yalnızca servis ücreti değildir veri hacmi retention süresi dashboard sayısı alert storm hepsi toplandığında fatura kabarır TL bazında düşününce bu küçük ayarlar bile fark ettirir.
Eğer bütçe kısıtlıysa doğrudan tüm cluster’a ağır metrik setleri yaymak yerine can alıcı node havuzlarında başlamak daha mantıklı olabilir hatta bazı ortamlarda sadece production namespace’i izlemek bile yeterli olur enterprise tarafta geniş kapsam şart. Startup dünyasında sade çözüm çoğu zaman kazandırır çünkü para harcamadan önce öğrenirsiniz. Daha fazla bilgi için Segment Heap: Visual Studio’da C++ Belleği Neden Değişti? yazımıza bakabilirsiniz.
Benim şahsi kanaatim şu yönde: PSI GA olması iyi haber ama önü sihirli değnek gibi görmek yanlış olur Alarm eşiğini doğru koymazsanız yine boşuna uyanırsınız Bununla ilgili en kötü deneyimlerden biri Eylül 2024’te Ankara’daki bir müşteride yaşandı eşik o kadar hassastı ki gece vardiyası gereksiz yere ayağa kalktı sonunda problemi metric’te değil tuning’de bulduk biraz can sıkıcıydı doğrusu!
# Örnek yaklaşım
# Önce base line alın
kubectl top nodes
kubectl get --raw /metrics/resource
# Ardından PSI trendini takip edin
# Node/pod/container ayrımını mevcut gözlemleme aracınıza bağlayın
# Kritik eşikleri önce "warning", sonra "critical" olarak kademelendirin
Bence burada asıl mesaj ne?
Bence mesaj net: Kubernetes artık bize sadece kaynak tüketimini değil kaynak sıkışmasını da daha düzgün gösteriyor Bu ufak fark prod ortamda büyük fark yaratır özellikle latency-sensitive uygulamalarda ödeme sistemlerinde API gateway katmanında veya veri yoğun işler yapan platformlarda (ciddiyim)
Neyse uzatmayayım; eğer cluster yönetiyorsanız PSI’yı sırf “yeni özellik” diye geçmeyin İlk işiniz mevcut monitöring stack’inizde hangi alanda kör olduğunuzu bulun sonra bunu PSU gibi yanı görünmez güç kaynağı gibi arkaya koyun — sessiz çalışsın. Hani ne farkı var diyorsunuz, değil mi? Gerektiğinde sizi kurtarsın.
Ben olsam ilk üç adımı nasıl atarım?
- Kritik production cluster’da PSI verisinin aktif olup olmadığını kontrol ederim.
- Birkaç gerçek workload için CPU/memory/I/O pressure trendlerini çıkarırım.
- Aynı anda utilization grafikleriyle karşılaştırıp yanlış pozitifleri temizlerim.
Sıkça Sorulan Sorular
PSI tam olarak ne ölçüyor?
PSI, aslında sistemin kaynak bekleme süresini ölçüyor. Işlemcinin ne kadar meşgul olduğuyla değil, işlerin ne kadar süre takılıp kaldığıyla ilgileniyor.
Kubernetes’te PSI açmak performansı düşürür mü?
Açıkçası pek düşürmez. Yapılan testler overhead’in oldukça düşük olduğunu gösteriyor. Ama yine de bence her ortamda kısa bir pilot deneme yapmak en sağlıklısı.
CPU kullanımı düşükse yine de sorun olabilir mi?
Evet, olabilir. Hatta en sinsi problemlerden biri de tam olarak bu. CPU rahat görünüyor, her şey normal gibi, ama task’ler scheduling ya da I/O nedeniyle sessiz sedasız bekliyordur.
PSI alertlerini nasıl kurmak gerekir?
Önce warning seviyesinden başlayın ve kısa/orta/uzun pencereyi birlikte değerlendirin. Tecrübeme göre tek metriğe bağlı sert alarm vermek genelde sadece gereksiz gürültü çıkarıyor.
Küçük ekipler direkt kullanabilir mi?
Evet, kullanılabilir. Ama kapsamı dar tutmak daha iyi olur; mesela önce kritik servislerde deneyin, sonra yavaş yavaş yaygınlaştırın.
Kaynaklar ve İleri Okuma
Kubernetes Resource Usage Monitöring Dokümantasyonu
Linux Kernel Pressure Stall Information (PSI)
İlgili yazılarımızdan Kubernetes v1.36: Workload-Aware Scheduling Yeni Boyutta, Kubernetes v1.36’da DRA: Donanım Paylaşımında Yeni Dönem, Kubernetes v1.36 Volume Group Snapshots Sonunda GA Öldü.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.










4 comments