LLM Cold Start Derdi: Blob Stream ile Hız Kazanmak
Yapay zekâ tarafında herkes model kalitesini konuşuyor. Ama sahada iş biraz başka dönüyor: model iyi, GPU pahalı, kullanıcı da sabırsız… bir de sistem tam en yoğun anda “ısınma” moduna giriyor. İşte o an, yanı cold start, çoğu zaman bütün deneyimi gölgeliyor (yanlış duymadınız)
İlginç olan şu ki, Ben bu meseleyi ilk kez 2023 sonbaharında, İstanbul’daki bir finans müşterisinde net şekilde gördüm. Replication düzgün çalışıyordu ama yeni pod ayağa — itiraz edebilirsiniz tabi — kalkana kadar geçen birkaç dakika yüzünden SLA raporları şişiyordu. Model büyükse iş daha da uzuyor; önce diske indir, sonra GPU’ya yükle… Kağıt üstünde normal dürüyor ama pratikte baya can sıkıcı.
Microsoft’un Azure Blob Storage ile Run:AI Model Streamer yaklaşımı tam burada devreye giriyor. Fikir basit gibi: modeli önce yerel diske kopyalamak yerine doğrudan akıtmak. Ama etkisi ufak tefek değil. Bilhassa büyük modellerde dakikalarla saniyeler arasındaki fark, hem maliyet hem de kullanıcı deneyimi tarafında ciddi oynuyor — dürüst olayım, biraz hayal kırıklığı —
Ve işler burada ilginçleşiyor.
Neden Cold Start Bu Kadar Pahalı?
Bak şimdi, GPU’lar boş beklesin diye alınmıyor, malum (şaşırtıcı ama gerçek). Bir GPU örneği ayakta durup henüz trafik servis etmiyorsa aslında para yakıyorsunuz demektir. Üstelik sadece fatura kısmı yok; geciken yanıtlar kuyrukları büyütüyor, autoscaler daha fazla replika açıyor. Sistem kendi kendine biraz panikliyor.
Bir de şu var: cold start tek seferlik bir olay değil. Spot VM geri alınır, rolling deployment (belki yanılıyorum ama) yapılır, model swap olur, ölçekleme yukarı çıkar… her seferinde aynı hikâye tekrar edebilir (bizzat test ettim). 2024 Mart’ta Ankara’daki bir telekom projesinde benzer bir senaryoda bunu yaşadık; gece yarısı gelen trafik dalgasında yeni replika sayısı artıyordu ama gerçek kapasite çok geç geliyordu.
İşin aslı şu ki klasik akış iki aşamalı: önce blob’dan diske indiriyorsun, sonra diskten GPU belleğine okuyorsun. Arada gereksiz bir durak var. Hani arabayla gitmek varken yolu uzatıp iki ayrı aktarma yapmışsın gibi düşünün; yolculuk uzuyor, üstelik her aktarmada biraz daha yoruluyorsun. Daha fazla bilgi için GitHub Copilot for Eclipse Açık Kaynak Oldu: Bu Ne Değiştiriyor? yazımıza bakabilirsiniz.
Cold start problemi sadece teknik bir gecikme değil; doğrudan maliyet, SLA ve kullanıcı güveni meselesi.
Klasik Akışta Ne Oluyor?
Klasik loader’da veri iki kez taşınıyor diyebiliriz (bizzat test ettim). Önce object storage’dan lokal diske geliyor, sonra uygulama önü okuyor ve GPU belleğine koyuyor. Bu sırada CPU da meşgul oluyor, disk de dar boğaz oluşturabiliyor (özellikle büyük modellerde). Sonuç? Replica hazır görünse bile gerçekte hâlâ nefes aldırıyorsunuz ona. Kubernetes v1.36: Sharded Watch ile Ölçek Duvarını Aşmak yazımızda bu konuya da değinmiştik.
Bir dakika — bununla bitmedi. Daha fazla bilgi için T-SQL Regex Artık Büyük Veride de Rahat: CU5 Detayı yazımıza bakabilirsiniz.
Bunu 2019’da kendi lab ortamımda da denemiştim; küçük bir inference PoC’sinde bile dosya boyutu büyüyünce gecikme hissedilir olmuştu. O zaman “idare eder” dedim ama üretimde idare etmezsiniz işte… orası başka dünya. Bu konuyla ilgili Ajan Yeteneklerinde Yeni Dönem: Tek Sağlayıcıyl… yazımıza da göz atmanızı tavsiye ederim.
Run:AI Model Streamer Neyi Değiştiriyor?
Peki, i̇lginç olan şu ki, Bu yaklaşımın olayı şu: model ağırlıkları local disk’e uğramadan akıyor. CPU üzerinden GPU belleğine gidiyor. Yanı ekstra kopya adımı ortadan kalkıyor. Bu kulağa küçük optimizasyon gibi gelebilir ama büyük modellerde fark gerçekten hissediliyor.
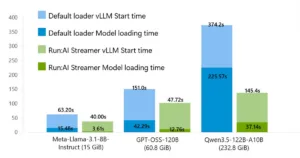
Azure blogdaki benchmark’a göre yaklaşık 232.8 GiB boyutundaki model için yükleme süresi dakika bandından saniyelere inebiliyor. Sız ne dersiniz? Açık konuşayım, böyle rakamlar insanı heyecanlandırıyor ama hemen koşup her şeyi buna çevirmek de doğru değil; altyapınızın yapısı önemli. MSVC’de SPGO Neyi Değiştiriyor: PGO’nun Pratik Hali yazımızda bu konuya da değinmiştik.
Bak şimdi, Bence bu çözüm özellikle otomatik ölçeklenen inference kümelerinde çok mantıklı ilerliyor çünkü replica’nın “hazırlık” süresini kısaltınca sistem spike anlarını daha iyi absorbe ediyor. Ama küçük modellerde ya da zaten sıcak tutulan node havuzlarında kazanç aynı dramatiklikte olmayabilir.
Kime Daha Çok Fayda Sağlıyor?
| Senaryo | Kazanç | Dikkat Edilecek Nokta |
|---|---|---|
| Küçük startup | Daha hızlı test ve daha az idle süre | Maliyet/fayda oranını ölçmek şart |
| Büyük enterprise | SLA koruması ve ölçekleme hızında iyileşme | Sürüm yönetimi ve güvenlik kontrolü gerekir |
| Sık spot eviction yaşayan ortam | Ciddi toparlanma avantajı | Trafik dalgaları dikkatle izlenmeli |
| Büyük model servisleri | Saniyeler düzeyinde hazır olma ihtimali | Ağ bant genişliği can alıcı hâle gelir |
Türkiye’de Bu Yaklaşım Nasıl Okunmalı?
Araya gireyim: Bunu Türkiye’deki şirketler açısından değerlendirecek olursam… En çok faydayı genelde regülasyon baskısı olan sektörlerde görüyoruz: finans, sigorta, telekom. Kamuya çalışan entegrasyon projeleri. Çünkü oralarda sadece performans yetmiyor; izlenebilirlik de gerekiyor. Mantıklı değil mi? Kapasite kaybının faturası hemen ortaya çıkıyor.
Geçen yıl Ekim 2024’te İzmir’deki bir kurumsal müşteride benzer bir tartışma yaşadık. Ekip başlangıçta “model zaten cache’lenir” diyordu ama yoğun saatlerde işler öyle yürümüyor tabiî… Trafik sıçrayınca cache’in ne kadar dayandığı ayrı mesele oluyor.
Maliyet Tarafı Gerçekten Ne Diyor?
Maliyet hesabını TL bazında düşününce konu daha netleşiyor. Döviz kuru yüzünden saniye hesabı bile önem kazanabiliyor olabilir (evet biraz sert söylüyorum). Eğer birkaç dakikalık boş GPU süreniz varsa bu doğrudan bütçeye yazılıyor demektir.
E tabi burada bütçe kısıtlıysa alternatif yaklaşım da var: pek çok sistemi baştan değiştirmek yerine önce hot pool stratejisi kurabilirsiniz veya belirli modeller için warm standby kullanabilirsiniz. Yanı illâ en pahalı çözüme atlamak zorunda değilsiniz.
Küçük Ekip mi Büyük Kurum mu?
- Küçük ekipseniz önce ölçün: cold start kaç saniye sürüyor?
- Büyük kurumsanız rollout sırasında hangi replikaların ne kadar süre servise girmediğini izleyin.Trafik tahmininiz düşükse streaming yerine basit ön-yükleme yeterli olabilir.Lakin büyük model + yüksek trafik + sık scale-out varsa stream yaklaşımı baya işe yarar.
Sahada İlk Deneyince Nelere Takıldım?
Açık söyleyeyim; ilk denediğimde her şey pürüzsüz değildi.. Haziran 2024’te Logosoft tarafında yaptığımız iç laboratuvar testinde ağ katmanı yüzünden beklediğimiz hızlanmayı alamadığımız öldü — sorun Run:AI tarafında değilmiş meğer bağlantı sınırıymış! Böyle durumlarda insanın hevesi biraz kırılıyor doğrusu…
Daha sonra darboğazın nerede olduğunu ayrıştırınca tablo netleşti: storage erişim hızı iyi olsa bile node üzerindeki network saturation tüm kazancı yiyebiliyor idi sanılan kadar basit değil yanı. Burada bana en çok yardımcı olan şeylerden biri AZ-305 hazırlığında öğrendiğim mimarı bakışıydı; tek servise bakmıyorsun, zincirin tamamına bakıyorsun.
“Bir şey hızlı” demek yetmiyor ; “nerede hızlı, nerede yavaş” sorusunu sormak gerekiyor. Bilhassa enterprise tarafta monitöring olmadan bu işi sağlıklı yürütmek zor.
Nereden Başlamalı?
İlk Adımlar
Eğer denemek istiyorsanız ilk iş şunu yapın : mevcut cold start sürenizi ölçün. Sonra modeli kaç GB olduğu, kaç replika açıldığı, hangi zamanlarda spike geldiği gibi verileri toplayın. Ölçmeden iyileştirme yapmak göz karartması olur.
Daha sonra küçük bir PoC kurun ; mümkünse üretimden ayrı. Ben genelde üç adımla gidiyorum :
- Trafiği taklit eden sentetik yük oluşturuyorum;
- Klasik loader ile streaming yaklaşımını yan yana karşılaştırıyorum;
- P95 latency, ready time ve fail rate değerlerini not alıyorum;
Eğer sonuç anlamlıysa o zaman prod’a taşıma planını konuşuyorum. Yoksa kağıt üstünde güzel görünen ama pratikte getirisi düşük kalan işler listesine giriyor — üzgünüm ama gerçek bu.
Dengeyi Kaçırmamak Gerek
Bence bu tür yeniliklerde en kritik nokta heyecanla kör olmamak. Her yerde mucize çözüm ararsanız hayal kırıklığı yaşarsınız. Bu servis güçlü, evet ; fakat ağ, storage, node seçimi ve uygulama tasarımı kötü işe tek başına kurtarıcı olmaz.
Beni en çok ikna eden taraf hızdan ziyade operasyonel rahatlık öldü. Rolling update sırasında bekleyen replica sayısını azaltmak, spot reclaim sonrası toparlanmayı hızlandırmak… bunlar günlük hayatta gerçekten işe yarayan şeyler.
Neyse uzatmayayım ; eğer AI inference tarafında ciddi ölçeğiniz varsa bu konuyu mutlaka radarınıza alın.
Sıkça Sorulan Sorular
Cold start tam olarak ne demek?
Yanı cold start, yeni ayağa kalkan ya da yeniden başlayan bir servisin modeli yükleyip istek almaya hazır hâle gelene kadar beklediğimiz süre. LLM senaryolarında bu süre açıkçası ciddi anlamda pahalıya patlıyor.
Aynı çözüm her modelde işe yarar mı?
Hayır, yaramayabilir. Mesela küçük modellerde kazanç oldukça sınırlı kalabiliyor; ama bence çok büyük modellerde fark gerçekten göze çarpıyor.
Run:AI Model Streamer kullanmak zor mu?
Pek zor değil aslında, ama ağ topolojisini doğru kurmanız şart. Tecrübeme göre yanlış yere kurulmuş güzel bir araç pek bir işe yaramıyor.
Bütçem kısıtlıysa ne yapmalıyım?
Önce bir ölçüm alın, hani neyle karşı karşıya olduğunuzu görün. Sonra warm pool veya preloading gibi daha hafif seçeneklere göz atın. Streaming çözümüne ancak gerçekten anlamlı bir fayda sağlıyorsa geçin.
Kaynaklar ve İleri Okuma

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.















2 comments