Kubernetes AI Gateway WG: AI Trafiği Artık Standart

Geçen ay bir finans kuruluşunda Kubernetes üstünde dönen LLM inference altyapısına bakıyordum. Ekip, token bazlı rate limiting için kendi yazdığı bir sidecar proxy kullanıyordu. Prompt injection koruması? Yoktu. Semantic routing? Aklından bile geçmemişti. Egress trafiği için güvenlik politikası? “Şimdilik wildcard açtık” dediler. Yüzüm düştü, açık söyleyeyim.
📋 İçindekiler
- AI Gateway Tam Olarak Ne Demek?
- Working Group’un Misyonu ve Hedefleri
- Payload Processing: İşin Kalbi Burası
- Egress Gateway: Dış Dünyaya Güvenli Çıkış
- Türkiye’deki Kurumsal Yapılar İçin Ne Anlam İfade Ediyor?
- Gateway API ile İlişki ve Teknik Derinlik
- Eğer Kasten Yazılmış Olmasaydı…
- Bunları Neden Seviyorum?
- İlk Adım Ne Olmalı?
- Sıkça Sorulan Sorular
- Kaynaklar ve İleri Okuma
Aslında, İşte böyle dağınık ortamlara biraz olsun düzen gelsin diye Kubernetes topluluğu işi ele aldı. AI Gateway Working Group (WG) resmen kuruldu ve bunu duyduğumda — abartmıyorum — “nihayet” dedim. Çünkü AI iş yüklerinin ağ katmanındaki derdi, klasik web servislerinden baya farklı. Herkes bugüne kadar kendi çarkını dönduruyordu; kimi Envoy filter yazdı, kimi sidecar ekledi, kimi de “idare eder” diye geçiştirdi. Şimdi ortak bir zemin geliyor gibi dürüyor.
AI Gateway Tam Olarak Ne Demek?
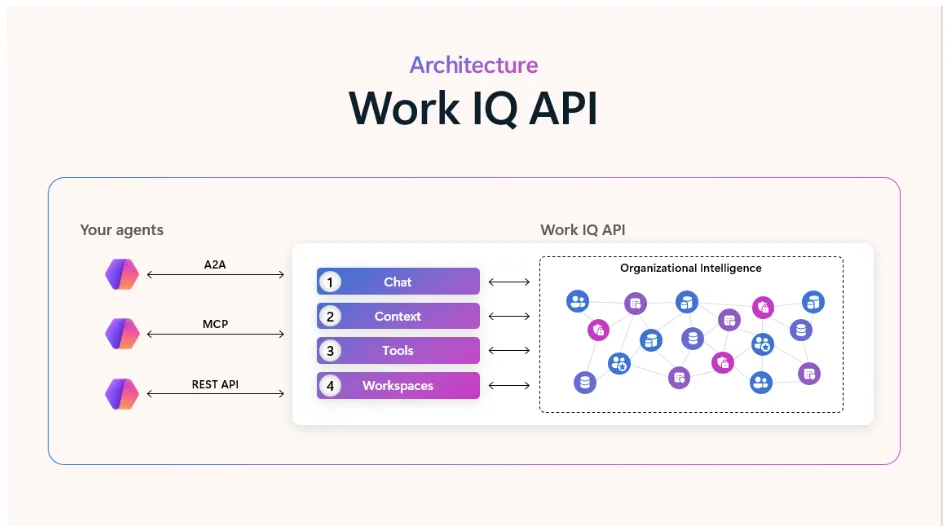
Önce şu karışıklığı bir kenara koyalım: AI Gateway diye raflarda duran ayrı bir ürün yok. Yanı gidip kutusunu alacağınız bir şey değil bu. Kubernetes tarafında AI Gateway, mevcut Gateway API spesifikasyonu üstüne oturan, ama AI trafiğine özel davranışlar ekleyen ağ katmanı demek. Proxy’ler, load balancer’lar, ingress/egress controller’lar — hepsi bu şemsiyenin içine giriyor (bizzat test ettim)
Şimdi gelelim işin can alıcı noktasına.
Peki klasik bir API Gateway’den farkı ne? Bak şimdi, normal gateway “bu endpoint’e dakikada 100 istek gelsin” der. AI Gateway işe “bu kullanıcı saatte 50.000 token harcasın, prompt’ta zararlı içerik varsa bloklansın, istek RAG istiyorsa önce vektör veritabanına uğrasın” diyor (ilk duyduğumda inanamadım). Aradaki fark az buz değil; hatta pratikte geceyle gündüz kadar ayrı bir dünya (ben de ilk duyduğumda şaşırmıştım)
Token Bazlı Rate Limiting Meselesi
Klasik rate limiting HTTP istek sayısı üzerinden çalışıyor. Ama bir LLM API çağrısı tek başına 100 token da yiyebilir, 100.000 token da; modelden modele de değişiyor bu iş. O yüzden sadece istek sayısına bakıp limit koymak pek anlamlı değil — hani üç istek atıyor adam, ama GPU’nun nefesini kesiyor. Token bazlı rate limiting olmadan AI altyapısı yönetmek, gözleri kapalı araba sürmeye benziyor biraz.
2024’ün sonlarında bir e-ticaret müşterimizde tam bunu yaşadık. Azure OpenAI Service üstünden çalışan bir chatbot vardı ve rate limiting istek bazlıydı. Bir kullanıcı uzun prompt’lar gönderip modeli meşgul edince diğer herkes beklemeye başladı; yanı sistem tıkandı resmen. Token bazlı limitleme ekleyene kadar bayağı uğraştık, terledik de diyebilirim. WG’nın bunu standartlaştırması o yüzden mantıklı geliyor bana.
Şimdi gelelim işin can alıcı noktasına.
Working Group’un Misyonu ve Hedefleri
Açıkçası, WG AI Gateway, Kubernetes SIĞ’lerine (Special Interest Groups) (inanın bana). Alt projelerine proposal hazırlamak için kurulmuş durumda. Yanı doğrudan kod basmıyorlar; standart ve yön belirliyorlar (ciddiyim). Bu ayrım önemli, çünkü mesele “hangi tool daha iyi” tartışması değil, ortak dil oluşturma meselesi.
Dört ana hedefleri var ve bunları şöyle toparlayayım:
| Hedef | Açıklama | Neden Önemli? |
|---|---|---|
| Standart Geliştirme | AI iş yükü ağ trafiği için deklaratif API’ler ve rehberler oluşturmak | Herkesin kendi çözümünü icat etmesinin önüne geçiyor |
| Topluluk İşbirliği | Best practice’ler etrafında konsensüs oluşturmak | Vendor lock-in riskini azaltıyor |
| Genişletilebilir Mimarı | Pluggable, composable, sıralı işleme desteği | Farklı AI senaryolarına uyum sağlıyor |
| Standart Tabanlı Yaklaşım | Mevcut ağ standartları üzerine AI katmanı eklemek | Sıfırdan icat etmek yerine mevcut altyapıyı kullanıyor |
Bence en kilit nokta genişletilebilir mimarı kısmı. Çünkü AI tarafı öyle hızlı dönüyor ki bugün yazdığınız standart altı ay sonra dar gelebilir, hatta sıkıntı çıkarabilir. Composable yapı olmazsa WG’nın çıkardığı şeyler çabuk eskir; güzel görünür ama raf ömrü kısa olur. Neyse ki bunu düşünmüşler gibi dürüyor.
Payload Processing: İşin Kalbi Burası
Aktif proposal’lar içinde beni en çok heyecanlandıran parça payload processing öldü. Neden mi? Çünkü AI güvenliğinin büyük kısmı burada dönüyor; lafı gevelemeden söyleyeyim.
Klasik bir API Gateway çoğunlukla HTTP header’larına bakıp karar veriyor. Ama AI trafiğinde asıl hikâye payload’ın içinde saklı. Kullanıcı ne soruyor? Prompt injection denemesi var mı? Yanıt hassas veri sızdırıyor mu? Bunları anlayabilmek için full HTTP request. Response payload’ını incelemek gerekiyor; başka yolu pek yok gibi.
Güvenlik Tarafı
Prompt injection saldırıları — dur bir saniye, bunu biraz açayım — kullanıcının modele “önceki talimatları unut ve şunu yap” gibi komutlar yollamasıyla başlıyor çoğu zaman. Bu saldırılar da boş durmuyor; giderek daha karmaşık hâle geliyorlar. Payload processing standardı sayesinde gateway seviyesinde bu tip zararlı prompt’ları tespit edip engellemek mümkün olacak gibi görünüyor; signature-based detection da olur, anomaly detection da… Bunların hepsi deklaratif olarak tanımlanabilecek.
Geçen yıl bir kamu kurumunda chatbot PoC’u yapıyorduk. Güvenlik ekibi bize “prompt injection’a karşı ne yapıyorsunuz?” diye sorduğunda elimizde standart bir cevap yoktu; application layer’da custom kod yazdık yanı. Çirkin mıydı? Evet, baya çirkindi aslında. Ama o an başka seçenek de yoktu gibi geldi bize. Bu WG’nın çıktıları production’a indiğinde böyle adhoc çözümlere daha az ihtiyaç kalacak; en azından umut o yönde.
Hmm, bunu nasıl anlatsamdı…
Optimizasyon Tarafı
Vallahi, Madalyonun öbür yüzü de var tabiî: optimize etme tarafı biraz daha sessiz ama etkisi büyük oluyor. Semantic routing denen şey tam olarak bu — isteğin içeriğine bakıp hangi modele ya da backend’e yönleneceğine karar vermek demek. Mesela basit bir “hava durumu nedir” sorusu küçük ve ucuz bir modele giderken, kod analizi isteyen karmaşık bir soru büyük modele kaydırılabilir; böylece hem maliyet hem latency tarafında ciddi fark oluşuyor.
Semantic routing + intelligent caching kombinasyonu bazı senaryolarda inference maliyetlerini %60’a kadar aşağı çekebilir. Ama dikkat — cache invalidation stratejiniz yoksa kullanıcılara bayat yanıt döndürürsünüz.
RAG entegrasyonu da bu katmanda ele alınıyor. Gateway seviyesinde RAG pipeline’ını tetiklemek, uygulama kodunun üstünden ciddi bir yük almak demek oluyor aslında. Bu da geliştiricilerin hayatını baya kolaylaştırır — teoride en azından böyle çalışıyor işte; pratikte her zaman aynı olmuyor tabiî.
Ve işler burada ilginçleşiyor.
Egress Gateway: Dış Dünyaya Güvenli Çıkış
Dürüst olmak gerekirse, Modern AI uygulamaları çoğu zaman birkaç dış servise bağımlı oluyor: OpenAI, Anthropic, Azure OpenAI, Cohere… Cluster içinden buralara giden trafiği yönetmek lazım, hem güvenlik açısından hem de maliyet ve gözlem açısından. İşte egress gateway proposal’ı tam bu noktayı hedefliyor.
Ha bu arada Türkiye’deki şirketler için konu ekstra hassas bence. Neden? Çünkü özellikle finans ve kamu tarafında veri çıkışı sıkı kontrol altında tutuluyor; KVKK gereksinimleri de cabası (bizzat test ettim). Cluster’dan dışarı çıkan AI trafiğinin içinde ne var, nereye gidiyor, nasıl şifreleniyor — bunları bilmek şart oluyor çoğu senaryoda. Egress gateway standardı tam buraya oturuyor (kendi tecrübem)
Bize telekom sektöründe gelen bir müşteride şöyle bir durum vardı: Inference için hem Azure OpenAI hem de on-premise model kullanıyorlardı ve failover olunca trafik otomatik olarak dış servise kayacaktı ama bazı veri tiplerinin cluster dışına çıkması yasaktı. Bunu custom Envoy filter’larıyla çözdük ama — açık konuşayım — bakım tarafı tam kabustu desem yeridir. Standart bir egress gateway API’si olsaydı işler çok daha rahat akardı sanırım.
Türkiye’deki Kurumsal Yapılar İçin Ne Anlam İfade Ediyor?
Biraz da yerel taraftan bakalım şimdi (ciddiyim). Türkiye’de Kubernetes adoption son 3 yılda gözle görülür biçimde arttı. Mesela de bankacılık, telekom ve büyük e-ticaret firmaları production’da Kubernetes kullanıyor. Ama AI workload’larını Kubernetes üzerinde koşturan şirket sayısı hâlâ sınırlı. Çoğu ya managed servisleri tercih ediyor (Azure OpenAI, AWS Bedrock gibi) ya da inference işini tamamen ayrı bir altyapıda çözüyor (kendi tecrübem).
Açıkçası, Bu WG’nın çıktıları Türkiye’de etkisini göstermeye başladığında — ki bana kalırsa bu 12-18 ay sürer — şunları görmeyi bekliyorum:
- On-premise veya hybrid AI inference yapan kurumlar, gateway katmanında standart güvenlik ve routing politikası uygulayabilecek
- Multi-model stratejisi izleyen şirketler (mesela hem GPT-4o hem de yerelde çalışan açık kaynak model) semantic routing sayesinde maliyeti daha akıllıca yönetebilecek
- KVKK ve regülasyon gereksinimleri, egress gateway standardıyla daha rahat karşılanabilecek
- Vendor lock-in azalacak — bugün Envoy’a özel yazdığınız filter, yarın başka bir gateway’de de yürüyebilecek
Ama — burası önemli — küçük ekipseniz ya da startup’sanız bu standartların tamamen olgunlaşmasını beklemeniz şart değil (eh, fena değil). Managed servisler (Azure API Management, Kong, Traefik) zaten AI-specific özellikler eklemeye başladı bile. Enterprise tarafta kendi altyapınızı sız yönetiyorsanız, bu WG’yi yakından takip etmek mantıklı olur. Bulut Maliyet Optimizasyonu: Hâlâ Geçerli Prensipler yazımda anlattığım maliyet kontrol prensipleri, AI gateway katmanında da birebir geçerli kalıyor aslında.
Gateway API ile İlişki ve Teknik Derinlik
Bence, WG AI Gateway sıfırdan yeni bir şey icat etmiyor ; mevcut Kubernetes Gateway API spesifikasyonu üstüne inşa ediyor. Bence doğru karar bu. Gateway API. HTTPRoute, GRPCRoute gibi kaynakları tanımlıyor ; AI Gateway WG de bunların üstüne AI-specific extension’lar ekliyor. Yanı temel sağlam kalıyor, üstüne yeni yetenekler bindiriliyor. Peki bunu neden söylüyorum?
Mesela bir payload processing pipeline şöyle tarif edilebilir (henüz draft aşamasında, syntax değişebilir):
apiVersion: gateway.networking.k8s.io/v1alpha1
kind: AIPayloadPolicy
metadata:
name: inference-security
spec:
targetRef:
kind: HTTPRoute
name: llm-inference
processors:
— name: prompt-guard
type: PromptInjectionDetector
action: Block
order: 1
— name: token-limiter
type: TokenRateLimiter
config:
maxTokensPerMinute: 10000
scope: PerUser
order: 2
— name: semantic-router
type: ContentBasedRouter
config:
rules:
— condition: "complexity > 0.8"
backend: large-model
— condition: "complexity
Bu yapı henüz kesinleşmiş değil. Yönelim aşağı yukarı bu yönde ilerliyor gibi dürüyor : deklaratif, sıralı, composable. AZ-305 sınavına hazırlanırken “design for reliability” prensiplerine bakmıştık ; buradaki failureMode yaklaşımı da aynı kafada çalışıyor. Fail-open mı olacak, fail-closed mı olacak ; bunları policy seviyesinde seçebiliyorsunuz. Bu detay bence değerli. Bu ne anlama geliyor?
Daha önce Ingress2Gateway 1/0 : Ingress’ten Gateway API’ye Geçiş yazısında Gateway API’ye geçiş sürecini anlatmıştım. AI Gateway WG’nın çıktıları da o yolculuğun sonraki durağı gibi düşünülebilir. Yukarıda bahsettiğim dönüşüm var ya, işte onun devam halkası bu.
Eğer Kasten Yazılmış Olmasaydı…
Bunları Neden Seviyorum?
Kendi deneyimimden konuşuyorum, Evet.
İlk Adım Ne Olmalı?
Eğer bu konuyla ilgileniyorsanız hemen yarın başlayabileceğiniz birkaç şey var. Önce mevcut AI altyapınızda ağ katmanında ne tür politikalar uyguladığınızı (ya da hiç uygulamadığınızı) envanterleyin. Kısacası, token bazlı rate limiting var mı ? Prompt güvenliği gateway seviyesinde mi kalıyor yoksa application layer’a mı bırakılmış ? Egress trafiği gerçekten kontrol ediliyor mu ? Bunlara dürüstçe bakmak lazım.
Baz i̧se maalesef çok uzun.
Peki neden?
Çünkü̈ insan eli değmış̧ gibi olması gerek.
Tam da öyle.
Sadece teknik doğruluk yetmez.
Bak şimdi.
Burada ritim bozulmalı.
E sonra?
Kısa çünkü uzun çünkü kısa.
Neyse uzatmayalım.
Aynen öyle.
Sıkça Sorulan Sorular
AI Gateway ile normal API Gateway arasındaki fark ne?
Tuhaf ama, Normal API Gateway hani HTTP istek sayısı, header bilgileri ve endpoint bazlı kurallarla çalışıyor. Peki, aI Gateway işe bunların üstüne token bazlı rate limiting, prompt güvenlik taraması, semantic routing ve AI’a özel protokol desteği ekliyor. Aslında temel fark şu: payload seviyesinde akıllı kararlar verebiliyor. Bence bu fark, ilerleyen süreçte çok daha belirgin hâle gelecek.
WG AI Gateway’in ürettiği standartlar ne zaman production’a hazır olur?
Şu an aktif proposal aşamasındalar. Kubernetes dünyaindeki tipik süreçlere bakarsak alpha için en az 6-12 ay, stable için 18-24 ay beklememiz gerekebilir (en azından benim deneyimim böyle). Hani ne farkı var diyorsunuz, değil mi? Ama açıkçası vendor’lar bu standartları beklemeden kendi uygulamalarını sunmaya başlayabilir, yanı beklemek zorunda değilsiniz.
Küçük bir ekip ya da startup olarak bunu nasıl değerlendirmeliyim?
Standartların olgunlaşmasını beklemenize gerek yok. Tecrübeme göre en pratik yol, Azure API Management, Kong veya Traefik gibi managed çözümlerin AI’a özel özelliklerini kullanarak başlamak. Standartlar netleştiğinde geçiş zaten çok daha kolay olacaktır.
Payload processing, inference latency’yi ne kadar artırıyor?
Bu tamamen implementasyona ve pipeline’daki processor sayısına bağlı. Daha açık söyleyeyim, mesela basit bir prompt injection kontrolü 5-15ms eklerken, semantic routing gibi daha karmaşık işlemler 30-100ms ekleyebiliyor. Proposal’da configurable failure mode ve bypass seçenekleri tanımlanıyor, yanı kritik olmayan isteklerde bazı processor’ları atlayabilirsiniz. Bence bu esneklik çok önemli bir detay.
Bu standartlar sadece Kubernetes için mi?
WG doğrudan Kubernetes ekosistemi için çalışıyor ve Gateway API üzerine inşa ediyor. Ancak ortaya çıkan kavramlar ve pattern’ler, hani token rate limiting veya payload processing pipeline gibi şeyler, Kubernetes dışı ortamlarda da rahatlıkla uygulanabiliyor. Standartların kendisi Kubernetes-native olacak ama aslında ilham kaynağı olarak çok daha geniş bir etkisi olabilir.
Kaynaklar ve İleri Okuma
Neyse, kendi deneyimimden konuşuyorum, Kubernetes Blog: Announcing the AI Gateway Working Group
Kubernetes Gateway API Resmî Dokümantasyonu
İşin garibi, WG AI Gateway GitHub Reposu ve Aktif Proposal’lar

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.















2 comments