Azure Functions’ta Retry Fırtınasını Durdurmak: Backoff ve Circuit Breaker
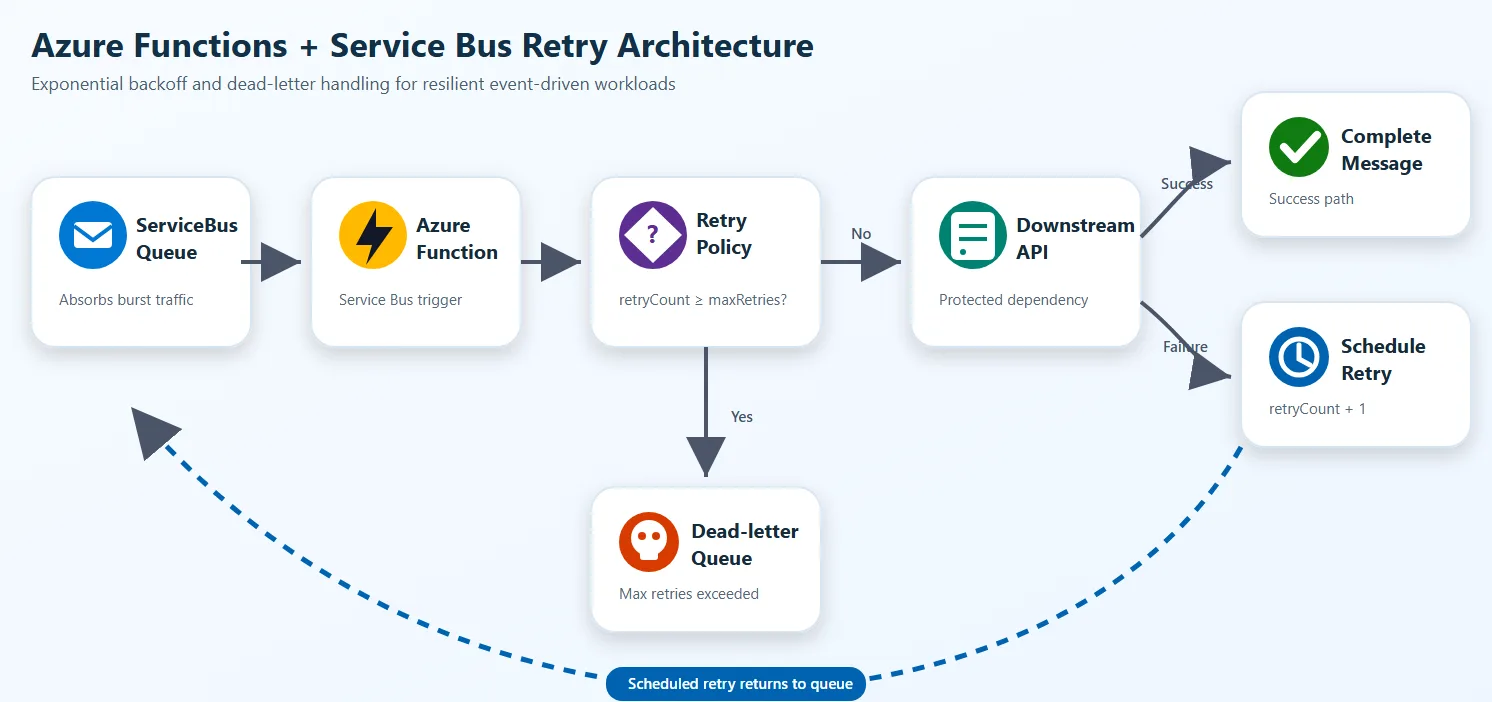
Geçen ay, Mart 2026’da bir finans müşterisinde tam da bu konuyu konuştuk: Azure Service Bus kuyruğu dışarıdan bakınca gayet sakın duruyordu (yanlış duymadınız). Arkadaki ödeme API’si arada bir tökezliyordu. İlk bakışta mesele ufak gibiydi. Sonra baktık ki Function instance’ları aynı hataya aynı anda yükleniyor, retry’lar üst üste biniyor, kuyruk uzuyor… klasik domino etkisi. İşin aslı şu: dağıtık sistemlerde en can sıkıcı hata çoğu zaman “tam çöküş” değil; yarım yamalak bozulma.
Ben Azure tarafında yıllardır hem hosting hem sistem yönetimi hem de bulut mimarisi görüyorum. AZ-104, AZ-305 ve AZ-500 hazırlıkları sırasında da kafama en çok kazınan şeylerden biri şuydu: Azure ölçekleniyor diye her şeyi sonsuza kadar denemek zorunda değilsiniz. Hatta bazen fazla denemek, hiç denememekten daha pahalıya patlıyor. Bilhassa serverless dünyada bu durum baya net.
Ve işler burada ilginçleşiyor.
Neden bu ikiliyi ciddiye almalıyız?
Azure Functions ile Service Bus kullandığınızda güzel bir akış kuruyorsunuz: mesaj geliyor, function çalışıyor, iş yapılıyor. Kağıt üstünde tamam gibi. Pratikte işe üçüncü parti servisler, SQL time-out’ları, network dalgalanmaları ve anlık trafik patlamaları devreye girince tablo değişiyor. Mesela geçen sene Eylül 2025’te bir e-ticaret projesinde bunu birebir gördük; kampanya başlangıcında mesaj hacmi arttı ve arka uç servisinin yanıt süresi normalin üç katına çıktı.
Eğer her instance hemen retry yaparsa, sistem kendi kendine yük bindiriyor. Yanı problem dışarıdan geliyor gibi görünüyor ama içerideki baskıyı biz büyütüyoruz. Bu bana hep kalabalık bir kavşakta herkesin aynı anda geri dönmeye çalışmasını hatırlatıyor — trafik sıkışıyor, çünkü herkes iyi niyetle ama yanlış anda hareket ediyor.
Yanı, Bir de şu var: Function app hızlı scale out ettiği için tekil bir dependency’ye onlarca paralel istek gidebiliyor. Küçük ekiplerde bu genelde ilk gün fark edilmiyor; startup tarafında “çalıştı mı tamamdır” yaklaşımı baskın oluyor. Ama enterprise ortamda olay farklı. Sız hiç denediniz mi? Orada birkaç dakika içinde binlerce mesaj gelebiliyor ve yanlış retry stratejisi pek çok operasyonu yoruyor.
Size bir şey söyleyeyim, Bence burada kritik nokta şu: transient failure ile kalıcı failure’ı ayırmak gerekiyor. Geçici hata varsa biraz beklemek mantıklı. Ama dependency gerçekten yere düştüyse önü dövmeye devam etmek sadece hasarı büyütüyor.
Exponential backoff nasıl düşünülmeli?
Backoff’un mantığı basit: ilk deneme kısa aralıkla yapılır, sonra bekleme süresi kademeli olarak artar. Yanı 1 saniye, iki saniye, — ki bu tartışılır — 4 saniye, 8 saniye gibi… Bunu çocuk oyuncağı gibi anlatıyorum ama etkisi ciddi. Çünkü kısa süreli kesintilerde sisteme nefes aldırıyor.
Ben bunu ilk kez 2019’da kendi lab ortamımda test etmiştim; o zamanlar küçük bir.NET tabanlı iş akışı vardı. Bilinçli olarak downstream servisi yavaşlatmıştım. Sabırsız retry yazınca CPU gereksiz yükseldi, loglar şişti ve gerçek hata kayboldu. Backoff ekleyince tablo değişti; hata sayısı düşmedi belki ama gürültü azaldı, asıl problem görünür öldü.
Bir dakika — bununla bitmedi.
retryCount = message.metadata.retryCount
delaySeconds = min(baseDelay * (2 ^ retryCount), maxDelay)
if retryCount >= maxRetries:
deadLetter(message)
else:
scheduleNewMessage(delaySeconds)
completeCurrentMessage()
Buradaki fikir şu: mevcut mesajı tamamla, yeni mesajı geleceğe planla ve sistemi kilitleme. Bu yöntem özellikle Service Bus-triggered Azure Functions senaryosunda güzel çalışıyor. Kuyruk zaten doğal bir tampon görevi görüyor.
Açık konuşayım; backoff tek başına yetmez. Sadece geciktirmek bazen sorunlu dependency’ye giden trafiği azaltır ama tamamen durdurmaz. Eğer servis uzun süre sağlıksız kalırsa yine aynı yere çıkarsınız… işte orada circuit breaker devreye giriyor.
Circuit breaker neyi değiştiriyor?
Circuit breaker’ın olayı daha serttir: belirli eşik aşıldığında çağrıları keser ve fail-fast davranır. Yanı “şimdilik gitmiyorum kardeşim” der gibi düşünün. Bu kötü bir şey değil; tam tersine sistemi koruyan yetişkin davranışı bu.
Kurumsal projelerde bunun faydasını defalarca gördüm. Bilhassa bankacılık entegrasyonlarında dış servisler bazen kısa süreli bakım penceresine giriyor. Bunu size API seviyesinde açıkça söylemiyorlar. Eğer sız oraya körlemesine yüklenirseniz hem kendi uygulamanızı hem de karşı tarafı zorlarsınız (ki bu çoğu kişinin gözünden kaçıyor)
Circuit breaker’ın en sevdiğim yanı şu: başarısızlığı saklamaz, kontrollü hâle getirir.
Ha bu arada, circuit breaker’ın dezavantajı da var. Fazla agresif ayarlanırsa normalleşen servise geç dönersiniz ya da gereksiz yere trafiği kesersiniz. Yanı eşikler öyle rastgele koyulmaz; ölçüm ister, gözlem ister, biraz da saha hissi ister. .NET MAUI Artık CoreCLR’da: Mono’nun 24 Yıllık Yolculuğu yazımızda bu konuya da değinmiştik. Segment Heap: Visual Studio’da C++ Belleği Neden Değişti? yazımızda bu konuya da değinmiştik.
Küçük ekipte yaklaşım
Araya gireyim: Eğer iki kişilik ya da beş kişilik küçük bir ekipseniz önce basit başlayın derim: exponential backoff + sınırlı retry + dead-letter yolu yeterli olabilir. Her şeyi Polly policy orkestrasyonuna boğmaya gerek yok yanı… Daha fazla bilgi için Visual Studio Agent Skills: Copilot’a Takımınızı Öğretmek yazımıza bakabilirsiniz.
Büyük kurumsalda yaklaşım
Enterprise tarafta işe telemetry olmadan ilerlemek zor olur. Application Insights metrikleri, dependency health sinyalleri. Merkezî alerting olmadan circuit breaker kararlarını kör verirsiniz. O noktada iş teknikten çok operasyonel disipline dönüyor.
Bütçe dar işe ne yapmalı?
Eğer bütçe kısıtlıysa ekstra özel altyapıya abanmak yerine önce native mekanizmaları kullanın: Service Bus scheduled messages, dead-letter queue. Azure Functions host ayarları çoğu senaryoda iş görüyor.
| Desen | Amaç | Ne zaman işe yarar? | Zayıf yanı |
|---|---|---|---|
| Exponential backoff | Retry temposunu yavaşlatmak | Kısa süreli geçici hatalarda | Sorunu tamamen durdurmaz |
| Circuit breaker | Zehirli dependency’ye çağrıyı kesmek | Sürekli hata veren servislerde | Eşikler yanlışsa erken kapanabilir |
| Together | Sistemi kontrollü degrade etmek | Dengesiz trafik + bağımlılık arızasında | Tasarım dikkat ister |
Türkiye’de bu desen neden daha kritik?
Bunu Türkiye’deki şirketler açısından değerlendirirsek mesele sadece teknik değil; maliyet meselesi de var. Döviz bazlı bulut tüketimi yüzünden gereksiz retry demek doğrudan fatura demek oluyor. Bir müşteri toplantısında Kasım 2025’te net gördüm bunu: küçük görünen bir timeout problemi hafta sonu boyunca binlerce boş çağrı üretmişti ve maliyet raporunda tatsız sürpriz yaratmıştı.
Kurumsal müşterilerimde gördüğüm kadarıyla Türkiye’de benimsenme biraz farklı ilerliyor çünkü çoğu ekip önce “iş yürüsün” diyor, resiliency ikinci plana atılıyor. Sonra canlıda aksayınca herkes panic mode’a geçiyor… halbuki bu desenleri baştan koymak daha ucuz oluyor.
Ayrıca yerel regülasyonlar. Veri egemenliği hassasiyetleri nedeniyle bazı organizasyonlarda çoklu bölge veya dış servis bağımlılığı daha temkinli ele alınıyor; dolayısıyla backoff/circuit breaker tasarımı yalnızca performans için değil operasyonel risk için de önemli hâle geliyor.
Bence Türk şirketlerinde en büyük kazanım şu olurdu: poison message ile transient error ayrımı daha net yapılmalıydı fakat pratikte çoğu yerde hepsi aynı sepete atılıyor). Bu da analiz süresini uzatıyor.
Bir dakika, şunu da ekleyeyim: dead-letter kuyruğunu sadece “çöp kutusu” gibi görmek yanlış olur; aslında o kuyruk sizin adlı kayıt alanınız gibi çalışıyor. Bu konuyla ilgili Kubernetes v1.36: Workload-Aware Scheduling Yeni Boyutta yazımıza da göz atmanızı tavsiye ederim.
Uygulamada nasıl ilerlemeli?
- İlk adım: Dependency timeout değerlerini ölçün.
- İkinci adım: Retry sayısını sınırlayın ve artan gecikme kullanın.
- Üçüncü adım: Dead-letter / quarantine akışını tanımlayın. (bence en önemlisi)
- Dördüncü adım: Health sinyali yoksa circuit breaker eşiğini konservatif tutun. — ciddi fark yaratıyor
- Beşinci adım: Application Insights ile başarısızlık oranını izleyin.
Araya gireyim: AZ-305’e hazırlanırken ben hep şu soruyu kendime sordum: “Bu mimarı kırıldığında sistem nasıl davranacak?” Cevap yoksa tasarım eksik demektir.
Azure SDK tarafındaki örnekler burada bayağı öğretici oluyor çünkü teoriyi doğrudan çalışan kodla bağlıyorlar.
Geçen yıl Logosoft’ta yaptığımız bir göç projesinde de benzer şekilde message-driven yapı kurduk; ilk versiyonda basit retry vardı ama canlı testte downstream ERP servisi tökezleyince çözüm yetmedi.
Sonra backoff ekledik… rahatladı işler.”
Burada gözden kaçırılmaması gereken noktalar
Bi saniye — Kod tarafında özellikle message metadata’yı doğru taşımak önemli. Retry sayısını kaybettiğiniz an bütün mantık bozuluyor. Bir başka hata da (belki yanılıyorum ama) scheduled message üretirken clock skew’i hesaba katmamak. Bu konuda ilk denediğimde ufak bir zamanlama sapması yüzünden mesajların erken düştüğünü görmüştüm; çözümü UTC üzerinden gitmek öldü. Şey… küçük detay gibi dürüyor ama prod’da can sıkıyor.”
Sıkça Sorulan Sorular
Azure Functions’ta exponential backoff neden gerekli?
Bakın, Hani kısa süreli hatalar oluyor ya, işte o anlarda sistemi biraz sakinleştiriyor (bizzat test ettim). Aynı hataya aniden üşüşmeyi önlüyor. En çok da Service Bus tabanlı işlerde gereksiz retry fırtınasını ciddi ölçüde azaltıyor. Bence bu tek başına bile yeterli bir neden.
Circuit breaker ile retry aynı şey mi?
Hayır, değil. Retry yeniden denemek; circuit breaker işe belirli bir eşikten sonra çağrıyı tamamen durdurmak (bizzat test ettim). Yanı biri tempoyu ayarlıyor, diğeri kapıyı kapatıyor. Aslında ikisi birbirini tamamlayan şeyler.
Pozisyonum küçük ekipse hangisinden başlamalıyım?
Küçük ekiplerde önce exponential backoff’tan başlayın. Sonra dead-letter akışını oturtun. Dependency gerçekten sık çöküyorsa, mesela haftalık rutin bir şeyse, o zaman circuit breaker ekleyin. Tecrübeme göre bu sırayı atlamamak çok önemli.
Anahtar metrik olarak neye bakmalıyım?
Error rate, timeout oranı, queue length ve downstream latency iyi başlangıç noktaları. Bunları Application Insights ya da Log Analytics üzerinden izlerseniz aslında karar vermek çok kolaylaşıyor. Açıkçası bu dördü bile başlangıç için fazlasıyla yeterli.
Bütün bunlar maliyeti düşürür mü?
Aslında, Evet, çoğu senaryoda düşürüyor. Boşa çalışan invocation sayısı azalınca compute tüketimi de azalıyor. Yoğun trafik alan yapılarda fark gerçekten bariz oluyor, bence bu en somut kazanımlardan biri.
Kaynaklar ve İleri Okuma
Doğrusu, Azure Functions Service Bus binding resmî dokümantasyonu
Azure Service Bus dead-letter queue rehberi
Microsoft Azure Architecture Center — Circuit Breaker Pattern
Microsoft SQL ile Agentic AI Güvenliği: Katman Katman Savunma

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar

Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











2 comments