Azure Cosmos DB’de Bölüm Bazlı Otomatik Failover: Sessiz Devrim
Şöyle söyleyeyim, Şunu açık söyleyeyim: veri tabanı tarafında “kesinti yok” lafı çoğu zaman biraz pazarlama kokuyor. Ama bazı özellikler var ki, kağıt üstünde iyi görünmekle kalmıyor, sahada da iş görüyor. Azure Cosmos DB’nın Per Partition Automatic Failover özelliği tam o tarafa düşüyor. Sız hiç denediniz mi? Mesela de de tek yazma bölgesi kullanan ama yine de bölgesel dayanıklılık isteyen sistemlerde baya anlamlı bir adım.
Ben bu tarz şeylere hep şu gözle bakıyorum: “Operasyon ekibinin omzundan ne kadar yük alıyor?” Çünkü gece 03:17’de alarm çaldığında, teorik mimarı çizimleri kimseyi kurtarmıyor. İşleyen şey otomasyon, doğru tasarım ve mümkün olduğunca az manuel müdahale. Bu yeni yaklaşım da değerini tam burada gösteriyor.
İşte tam da bu noktada devreye giriyor.
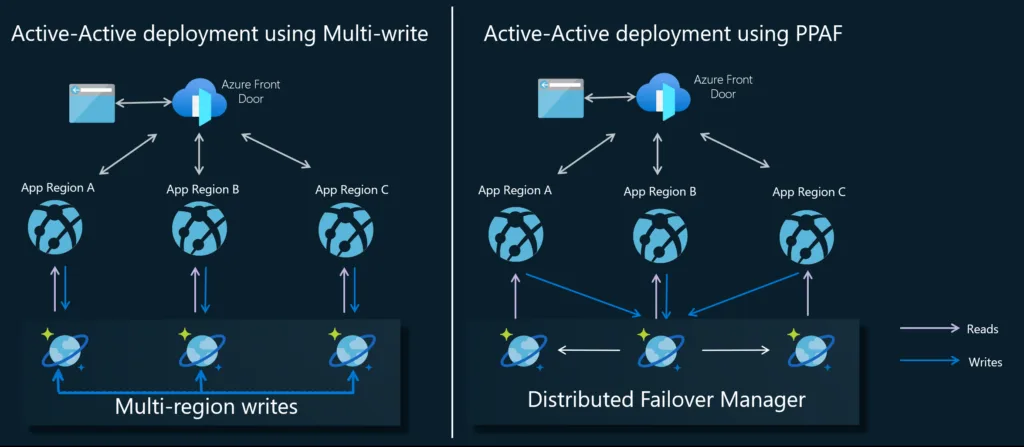
Azure Cosmos DB tarafında uzun zamandır çok bölgeli yazma senaryoları vardı. Güzel, tamam. Fakat herkesin ihtiyacı multi-write değil; hatta birçok kurumsal yapıda veri tutarlılığı, operasyonel sadelik ve regülasyon baskısı yüzünden tek yazma bölgesi tercih ediliyor. İşte PPAF dediğimiz yapı, bu kısıtın içinden akıllıca çıkmaya çalışıyor.
Bölge değil, bölüm bazında düşünmek neden önemli?
Şahsen, Klasik geo-failover yaklaşımında bir bölge sorun yaşarsa hesabın tamamını başka yere taşımak gerekir. Ağır bir hamle bu. Yanı tren raydan çıktıysa lokomotifi komple başka hatta almak gibi düşünün; çalışır ama hızlı değildir. Neden önemli bu? Kısacası, azure Cosmos DB burada olayı biraz daha ince ayara çekiyor: artık failover hesabın tamamı için değil, etkilenen partition set için yapılabiliyor.
Bunu biraz açayım.
Bu ayrım küçük gibi görünüyor ama etkisi büyük. Çünkü her partition aynı anda sorun yaşamıyor olabilir. Bir müşterimde 2024 başında İstanbul merkezli bir e-ticaret altyapısında benzer bir stres testinde bunu konuşmuştuk; bütün sistemi tek seferde taşımak yerine sadece etkilenen veri diliminin yönünü değiştirmek hem daha hızlıydı hem de daha az gürültü çıkarıyordu.
Bir dakika, şunu da ekleyeyim: bu model sadece teknik zarafet sağlamıyor, operasyonel maliyeti de aşağı çekiyor. Her şeyi yeniden yönlendirmek yerine dar kapsamlı toparlanma yapmak, özellikle yüksek trafik alan sistemlerde ciddi fark yaratıyor.
PPAF’ın en hoşuma giden yanı şu: uygulama koduna dokunmadan dayanıklılığı artırıyorsunuz. Yanı mimariyi büyütürken geliştirme takımına ekstra borç bırakmıyorsunuz.
Peki bu teknik olarak ne yapıyor?
Basit anlatayım: tercih edilen yazma bölgesinde bir partition set erişilemez hâle gelirse Azure Cosmos DB otomatik olarak başka bir bölgeyi o partition için yeni yazma noktası yapıyor. Uygulama tarafı çoğu durumda bunu hissetmiyor bile. İşin aslı şu ki, iyi tasarlanmış bir veri katmanının en sevdiğim hali biraz görünmez olmasıdır.
Bende ilk izlenim şöyle öldü: “Güzel. Acaba gerçekten o kadar akıcı mı?” Çünkü bazı bulut özellikleri demo’da şahane görünür, üretimde işe biraz yavaşlar (yanlış duymadınız). Neyse ki burada hedeflenen toparlanma süresi oldukça makul; P99 seviyesinde üç dakikanın altında kalmak cidden önemli bir eşik — itiraf edeyim, beklentimin üstündeydi —
Hmm, bunu nasıl anlatsamdı…
Tabiî her şey güllük gülistanlık değil. Eğer uygulamanız zaten kötü dağıtılmış partition anahtarlarıyla çalışıyorsa ya da sıcak veri birkaç partition üzerinde sıkışıp kalıyorsa, bu özellik tek başına mucize yaratmaz. Önce veri modelini düzeltmeniz lazım; sonra böyle şeyler anlam kazanır. Daha fazla bilgi için
2019’da Ankara’da bir finans müşterisinde buna benzer bir tartışma yaşamıştık. O dönem çoklu-yazma açmak istemiyorlardı çünkü çakışma çözümü ayrı dertti. Ekibin yarısı “yüksek erişilebilirlik olsun” derken diğer yarısı “işletmesi kolay olsun” diyordu. Bugün olsa onlara PPAF’ı hiç tereddüt etmeden masaya koyardım (inanın bana)
E tabi güçlü tutarlılık isteyen sistemlerde de ayrı değeri var. Ledger mantığıyla çalışan çözümler ya da stok takibi gibi hassas alanlarda Strong consistency ile birlikte kullanıldığında RPO sıfıra yakın kalabiliyor. Bu çok hafife alınacak iş değil.
| Senaryo | PPAF uygun mu? | Neden |
|---|---|---|
| E-ticaret sipariş sistemi | Evet | Yazma kesintisi direkt gelir kaybı yaratır |
| KOBI muhasebe uygulaması | Bazen | Maliyet ve ihtiyaç dengesi iyi kurulmalı |
| Sadece raporlama yapan uygulama | Pek değil | Failover değeri düşük kalır |
| Finansal işlem platformu | Evet | Tutarlılık ve süreklilik kritik |
Küçük ekip mi kurumsal yapı mı? Aynı cevap değil
Küçük ekipler için güzel haber şu: ekstra failover mantığı yazmak zorunda kalmıyorsunuz. Bu baya rahatlatıcı. Üç kişilik bir ürün ekibinde kimse gecenin köründe conflict resolver debug etmek istemez zaten.
Yanı, Büyük kurumsal yapılarda işe mesele biraz değişiyor. Orada teknoloji kadar süreç de önemli; değişiklik yönetimi, uyumluluk kontrolleri, izleme politikaları ve SLA hesapları devreye giriyor. Kurumsalda bence PPAF’ın kıymeti tam burada ortaya çıkıyor çünkü manuel failover prosedürlerini sadeleştiriyor.
Ama şöyle bir risk de var: kurumlar bazen “otomatikleştiyse tamamdır” diye düşünüyor ve test kısmını es geçiyor. Hayal kırıklığı yaşamak istemiyorsanız bunu yapmayın. Ben kendi projelerimde önce kontrollü outage senaryosu simüle edilmesini isterim; kağıt üstünde süper duran şeylerin üretimde tökezlediğini çok gördüm.
Maliyet tarafını nasıl okumalıyız?
Maliyeti sadece servis faturası olarak okumayın. Asıl masraf çoğu zaman operasyondur; insan zamanı, gece nöbeti, incident sonrası analiz ve müşteri güveni… Bunların toplamı genelde faturadan daha pahalıya geliyor.
Garip gelecek ama, Türkiye’deki şirketler açısından bakınca döviz kuru etkisi işi daha da hassas hâle getiriyor tabi ki. Azure tarafındaki tüketimi TL’ye çevirdiğinizde bazı ekipler hemen geri çekiliyor; haklılar da aslında… Ama burada şunu sormak lazım: Bir saatlik kesintinin size gerçek bedeli ne? Eğer cevap yüksekse, PPAF’ın sağladığı koruma çoğu zaman kendini savunuyor.
Sahada dikkat ettiğim pratik noktalar
İlginç olan şu ki, AZ-305 sınavına hazırlanırken de hep aynı yere dönüyordum: dayanıklılık tasarımı yalnızca servis seçmek değildir; ağ topolojisi, veri dağılımı ve iş sürekliliği birlikte düşünülür. Burada da aynı mantık geçerli oluyor.
Geçen yıl Kasım ayında İzmir’deki bir perakende projesinde şu hatayı gördüm: partition key öyle seçilmişti ki yoğun saatlerde tekil partition aşırı yük alıyordu (tam klasik sıcak nokta problemi). Böyle bir düzende failover özelliği var diye rahatlamak yanlış olurdu çünkü yük dağılımınız bozuksa fayda sınırlı kalır.
// Mantık örneği — uygulama değişmeden dayanıklılık artışı
{
"account": "cosmos-account-prod",
"consistencyLevel": "Strong",
"preferredRegions": ["westeurope", "northeurope"],
"failoverMode": "PerPartitionAutomaticFailover"
}
Denerken ilk iş ne yapmalı?
- NoSQL API hesabınızda tek-yazma bölgesi modelini doğrulayın.
- Sıcak partition’ları tespit edin; gerekirse telemetry ile ölçün.
- Tatbikat ortamında kontrollü regional outage senaryosu çalıştırın.
- Tutarlılık seviyesi ile iş ihtiyacını eşleyin; körlemesine yükseltmeyin.
Hani, Neyse uzatmayayım; benim önerim şu olurdu: eğer sisteminiz gerçekten kritikse. Multi-write karmaşasına girmek istemiyorsanız bu özelliğe mutlaka bakın.Azure Cosmos DB’de Silinenleri Görmek: Change Feed’in Sessiz Gücü
Bakın, burayı atlarsanız yazının kalanı anlamsız kalır.
SQL + AI: Elinizdeki Veriyi Bozmadan Akıllı Uygulama Kurmak yazısında anlattığım yaklaşımda olduğu gibi veri katmanı kararları hep ürün kararına dönüşüyor; yanı mesele sadece teknik değil (ciddiyim)
Azure IaaS’ta Performans: VM’den Çok Daha Fazlası Var yazısındaki performans bakışı da burada işe yarar. Dayanıklılık ile performansı ayrı kutular sanmak genelde pahalıya patlıyor.
Neden bence önemli bir GA duyurusu?
Bana göre bu duyuru sıradan bir ürün güncellemesi değil… Daha çok “kurumsal işletilebilirlik” tarafında küçük görünen ama büyük etki yapan türden yeniliklerden biri.Az önce söylediklerime rağmen hâlâ eksik olan yerler var mı? Var elbette mesela daha fazla görünürlük aracı. Daha ince alarm entegrasyonu görmek isterim ama başlangıç kötü değil hatta baya iyi.
Böyle özelliklerin asıl değeri kriz anında anlaşılır.Bir servis sabah dokuzda sorunsuz çalışıyorsa herkes memnun olur.Fakat öğleden sonra Avrupa bölgesinde kısa süreli bozulmalar başladığında olay değişir.O anda otomasyon konuşur insan susar işte mesele budur!
Sıkça Sorulan Sorular
PPAF ile multi-region writes aynı şey mi?
Hayır, ikisi farklı şeyler. PPAF, hani tek-yazma bölgeli hesaplarda çalışıyor ve bölüm bazında otomatik failover sağlıyor. Multi-region writes işe farklı bölgelerin aynı anda yazabilmesini hedefliyor — ama açıkçası conflict resolution meselesi ciddi bir karmaşıklık getiriyor (en azından benim deneyimim böyle)
PPAF uygulama kodu değişikliği ister mi?
Genelde hayır. Zaten amacı bu — uygulamaya dokunmadan dayanıklılığı artırmak. Hata toleransı büyük ölçüde platform tarafından yönetiliyor, yanı sizin tarafınızda ekstra bir şey yapmak gerekmiyor.
P99’da üç dakikanın altına inmek ne ifade ediyor?
Aslında şunu ifade ediyor: yazma erişimi bozulan partition’ların çoğu üç dakika civarında başka bir bölgeye taşınıyor. Tecrübeme göre bu süre birçok iş yükü için oldukça kabul edilebilir — ciddi bir iyileşme demek yanı.
PPAF hangi iş yüklerinde pek uygun değildir?
Aslında, Mesela düşük kritik önemdeki sistemlerde ya da yalnızca raporlama yapan yapılarda getirisi sınırlı kalabiliyor. Bence maliyet-benefit oranını iyi düşünmek lazım burada (buna dikkat edin)
Kaynaklar ve İleri Okuma
Azure Cosmos DB for NoSQL Resmî Dokümantasyonu
Azure Cosmos DB High Availability Rehberi (en azından benim deneyimim böyle)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.












4 comments