Azure Cosmos DB’de Partition Key Değiştirmek: Artık Daha Az Acı Veriyor
Azure Cosmos DB ile çalışan ekiplerin canını en çok sıkan şeylerden biri, yanlış seçilmiş bir partition key yüzünden aylar sonra duvara toslamak oluyor. İlk günlerde her şey yolunda gidiyor; trafik düşük, veri küçük, sorgular da masum görünüyor. Sonra ürün büyüyor, erişim paterni değişiyor. Bir bakıyorsunuz hot partition yüzünden RU tüketimi zıplamış, bazı sorgular fan-out yapmaya başlamış, gecikme de sessizce yukarı tırmanıyor. İşin aslı şu: partition key seçimi sadece teknik bir detay değil, mimarinin omurgası.
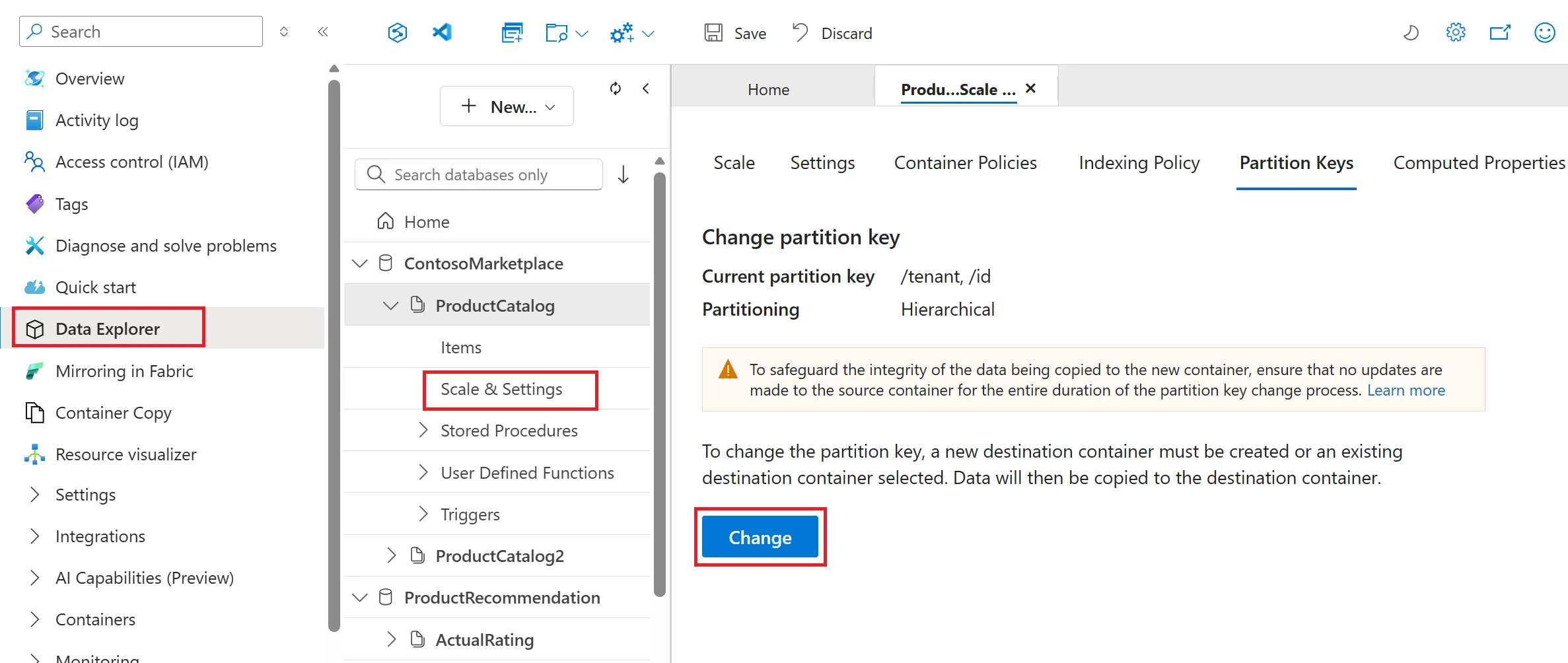
Microsoft’un Change Partition Key özelliğini genel kullanıma açması bence bayağı önemli bir adım. Çünkü daha önce bu işi çözmek için çoğu ekip ya yeni container açıp uygulama seviyesinde göç yazıyordu ya da “şimdilik böyle kalsın” deyip teknik borcu içeri alıyordu. İkisi de pek keyifli değil. Şimdi portal üzerinden, üstelik online copy desteğiyle, neredeyse kesintisiz şekilde bu dönüşümü yapmak mümkün hâle geldi. Kağıt üstünde güzel; pratikte işe hâlâ dikkat istiyor (bizzat test ettim). Evet.
Neden bu konu bu kadar kritik?
Ben bunu ilk kez 2019’da bir e-ticaret projesinde çok net gördüm. Siparişleri müşteri kimliğiyle bölmüştük çünkü başta mantıklı gelmişti (en azından benim deneyimim böyle). Trafik artınca aynı büyük müşteriler sürekli aynı logical partition’a yük bindirmeye başladı. Yanı sistem çalışıyordu ama “çalışıyor” ile “iyi çalışıyor” arasında dağ gibi fark varmış… Bunu canlıda görünce insanın aklına hemen şu geliyor: keşke başta biraz daha farklı modelleseydik.
Evet, doğru duydunuz.
Partition key’in önemi tam burada ortaya çıkıyor. Cosmos DB veriyi fiziksel parçalara dağıtırken bu anahtarı rehber gibi kullanıyor. Sorgu rotası da buna göre şekilleniyor. Yanlış anahtar seçerseniz yalnızca performans düşmüyor; maliyet de şişebiliyor. Mesela de Türkiye’de kurumsal yapılarda bunu sık görüyorum. Başlangıç aşamasında çoğu ekip hızla MVP çıkarma baskısıyla hareket ediyor, veri modelini ikinci plana atıyor. Bak şimdi, mesele tam da bu.
Bakın, Ha bu arada, startup ile enterprise arasında ciddi fark var. Küçük bir ekipte “bir an önce yayına çıkalım” refleksi anlaşılır. Büyük kurumda aynı yaklaşım birkaç ay sonra operasyonel kabusa dönebiliyor. Enterprise tarafında veri sahipliği, uyumluluk ve cutover planı devreye girince iş uzuyor. Startup tarafında işe hızlı deneme avantajı var; yanlış partition key’i erken fark ederseniz kurtarırsınız. Geç kalırsanız iş zorlaşıyor.
Evet, doğru duydunuz.
Tipik sorunlar nerede patlıyor?
En sık gördüğüm üç senaryo var: hot partition, cross-partition query ve logical partition limitine yaklaşmak. Hot partition dediğimiz şey aslında kasanın tek çekmecesine bütün faturaları doldurmak gibi; çekmece kapanmıyor tabiî ki. Cross-partition sorgular işe her istekte tüm mağazaları dolaşmak gibi düşünülebilir — kolayca RU yer ve gecikmeyi artırır.
Bir de şema evrimi var. Başta kullanıcı merkezli kurduğunuz model, sonra cihaz bazlı veya tenant bazlı erişime dönünce eski anahtar artık iş görmez hâle geliyor. Benim 2024’te Ankara’daki bir finans müşterisinde gördüğüm tablo buydu: ilk tasarım gayet düzgündü ama yeni raporlama ihtiyaçları gelince mevcut yapı yavaş yavaş sıkıştı. E peki, sonuç ne öldü? Şey yanı, sorun veri miktarından çok erişim şekliydi.
Bunu biraz açayım.
| Durum | Sorun | Etkisi |
|---|---|---|
| Hot partition | Aynı logical partition’a aşırı yük | Yüksek latency, dengesiz RU tüketimi |
| Cross-partition query | Sorgu tüm bölümlere yayılıyor | Daha fazla maliyet ve daha yavaş cevap |
| Büyüyen veri hacmi | Logical partition sınırına yaklaşma | Mimarı revizyon ihtiyacı |
Yeni özellik neyi değiştiriyor?
Şunu söyleyeyim, Daha önce bu iş neredeyse neredeyse tamamen manuel göç demekti: yeni container oluştur, veriyi taşıyacak kod yaz, kesme anını planla, yazmaları durdur, dual-write düşün… Uzayıp gidiyordu. Şimdi Change Partition Key özelliği intra-account container copy altyapısını kullanarak bunu çok daha kontrollü hâle getiriyor.
Bana göre en değerli tarafı online copy desteği. Yanı kaynak container’a yazılar devam ederken hedefe kopyalama yapılabiliyor. Bu küçük gibi görünür ama üretimde çalışan sistemler için hayat kurtarıcıdır. Tabiî burada “tamamen sihirli değnek” beklememek lazım; son geçiş anında yine disiplin gerekiyor (şaşırtıcı ama gerçek). Hatta bazen o son yüzde beşlik kısım en yorucu yer oluyor.
Partition key değişimi teknik olarak kolaylaştırılmış olabilir ama mimarı kararın kendisi hâlâ sizin sorumluluğunuzda kalıyor.
Açık konuşayım, bu özellik ilk duyulduğunda akla gelen soru şu oluyor: “Demek ki artık yanlış seçim yaparsam sorun yok?” Hayır, öyle değil. Bu servis hata affetme mekanizması değil; daha çok geri dönüş kapısı gibi düşünün. Çok iyi haber ama biraz ham tarafı da var — özellikle cutover planını hafife alırsanız sürpriz yaşayabilirsiniz. Discovery to Execution: Foundry’de Ajanları Toolbox ile Ölçeklemek yazımızda bu konuya da değinmiştik.
Küçük ekip mi, kurumsal yapı mı?
Eh, Küçük ekipler için önerim basit: önce yeni partition key ile gerçekten hangi sorguların iyileştiğini ölçün, sonra taşıyın. Çünkü her migration emek ister ve bütçe küçükse gereksiz deneme lüksünüz olmayabilir.
Bir şey dikkatimi çekti: Büyük kurumlarda işe iş biraz daha formal ilerlemeli. Test ortamında online copy sürecini birebir simüle etmek şart olurdu benim gözümde (özellikle regülasyonlu sektörlerde). Ayrıca uygulama katmanında connection string / container referansı değişimini nasıl yöneteceğinizi önceden netleştirin. Yoksa canlıya çıkınca herkes birbirine bakıyor. Bu konuyla ilgili vcpkg Mayıs 2026 Güncellemesi: Sessiz Güç, Büyük Etki yazımıza da göz atmanızı tavsiye ederim.
Sahada nasıl uygulanır?
Ne yalan söyleyeyim, Geçen yıl İzmir’de bir lojistik firmasına danışmanlık verirken benzer bir geçiş planladık ama o zaman Change Partition Key GA değildi; mecburen paralel yapı kurduk. Oldukça uğraştırdı bizi. Şimdi aynı senaryoda portal üzerinden job başlatıp ilerlemeyi izlemek çok daha temiz olurdu diye düşünüyorum.
Süreç kabaca üç parçaya ayrılıyor: job başlatma, ilerlemeyi izleme ve cutover yapma. Online modda kaynak container’daki yazmalar hedefe taşınmaya devam ediyor; sız de portal üzerinden doküman sayısını takip ediyorsunuz. Kopya neredeyse tamamlandığında yazmayı durdurup işlemi bitiriyorsunuz. Kulağa basit geliyor ama şey… canlı sistemde basit görünen işler bazen gece yarısı alarmına dönüşebiliyor.
# Pratik kontrol listesi
1) Mevcut access pattern'i çıkar
2) Yeni partition key için query'leri test et
3) Online copy job'u test ortamında dene
4) Cutover zamanını düşük trafikte planla
5) Uygulama tarafında bağlantı geçişini hazır tut
6) Eski container'ı hemen silme; kısa süre doğrulama bırak
Nerede hata yaptım?
Bunu saklamayayım: İlk Cosmos DB göçlerinden birinde destination container’ı doğru hazırladığımız hâlde throughput tarafını hafif tutmuşuz ve kopyalama sırasında beklediğimizden fazla gecikme aldık. Hata mesajı çok dramatik değildi ama performans bize tokat gibi geldi diyebilirim. Çözümümüz basitti: geçici olarak kapasiteyi artırdık ve job’u tekrar koşturduk.
Bu yüzden ben hep şunu söylerim: veri modeli kadar kapasite planlaması da önemli. Bilhassa TL bazında bakınca Azure maliyetleri bazı ekiplerde hassas konu oluyor — haklılar da — fakat yanlış planlanmış bir migration’ın operasyon maliyeti çoğu zaman birkaç günlük ekstra kapasiteden pahalıya geliyor.
Maliyet ve risk açısından nasıl okumalı?
Bütçe kısıtlıysa iki yolu karşılaştırırım ben genelde: ya mevcut sistemi olduğu gibi tutup kısa vadeli riskleri kabul edeceksiniz ya da kontrollü biçimde yeniden bölümlendirme yapacaksınız (kendi tecrübem). Birincisi ucuz görünür ama gizli maliyet taşır; ikincisi başlangıçta biraz masraf çıkarır ama uzun vadede nefes aldırır. Daha fazla bilgi için CodeQL 2.25.6 ile Sessiz Ama Güçlü Güvenlik Sıçraması yazımıza bakabilirsiniz.
Türkiye’deki şirketlerde en sık gördüğüm durum şu: performans problemi yaşanana kadar kimse storage veya request cost hesabını ciddiye almıyor. Sonra rapor ekranları ağırlaşınca panik başlıyor. O noktada Change Partition Key özelliği iyi bir çıkış kapısı sağlıyor ama ben yine de önce telemetry toplamanızı öneririm. Azure Monitör metriklerine bakmadan yapılan kararlar çoğu zaman tahmine dayanıyor. .NET 11 Preview 5: Sessiz Gelen Yenilikler, Büyük Etki yazımızda bu konuya da değinmiştik.
Bunu kendi projelerimde nasıl konumlandırıyorum?
AZ-305 sınavına hazırlanırken bile şunu tekrar tekrar görmüştüm: doğru veri yerleşimi sadece teoride değil gerçek mimaride de oyunun kaderini değiştiriyor. Cosmos DB bunun en net örneklerinden biri. AZ-104 tarafında operasyonu öğreniyorsunuz, AZ-500’de güvenlik kısmını oturtuyorsunuz, ama data modeling kısmı ayrı bir kaş istiyor — önü geliştirmeden sağlıklı bulut mimarisi olmuyor. GitHub’ın Unuttuğu Depolar İçin Güvenlik Kontrolü: Bence Asıl Mesaj Bu yazımızda bu konuya da değinmiştik.
Logosoft’ta çalışırken bir telekom müşterisinde benzer şekilde event yoğunluğu yüksek bir yapı analiz etmiştik. Orada asıl problem “veri kötü” değildi; access pattern eski kalmıştı. Bu ayrımı yapmak önemli. Çünkü bazen çözüm servisi değiştirmek değil,anahtarı yeniden düşünmek oluyor — itiraf edeyim, beklentimin üstündeydi —. İşte bu özellik tam o noktada işe yarıyor.
Tavsiyem ne?
- Önce workload’unuzu okuyun: hangi kullanıcı hangi veriye dokunuyor? — ciddi fark yaratıyor
- Kritik sorguları tek tek test edin; tahmin etmeyin.
- Cutover öncesi geri dönüş planı hazırlayın.
- Eğer üretimdeyseniz offline yerine online modu değerlendirin.
- Eski container’ı hemen silmeyin; birkaç gün gözlem bırakın.
Neyse uzatmayayım… Benim görüşüm şu: Microsoft burada gerçekten doğru yönde adım atmış. Ama hâlâ eksik olan şeylerin başında süreç rehberlerinin biraz daha gerçek dünya senaryolarıyla zenginleştirilmesi geliyor. Mesela çok kiracılı SaaS uygulamalarında tenant bazlı geçiş örnekleri ya da yüksek trafik altında throttle davranışı daha açık anlatılabilir.
Sıkça Sorulan Sorular
Azure Cosmos DB’de partition key sonradan değiştirilebilir mi?
Evet, artık Change Partition Key özelliğiyle bu mümkün oluyor. Üstelik online copy desteği sayesinde kaynak container’daki yazmaları tamamen durdurmadan geçiş yapabiliyorsunuz — bence bu gerçekten büyük bir kolaylık.
Online copy ile offline copy arasındaki fark nedir?
Online copy’de kaynak container’a yazmalar devam ederken hedefe kopyalama sürüyor (buna dikkat edin). Offline copy’de işe genelde yazmaları durdurmanız gerekiyor; yanı geçiş penceresi daha belirgin oluyor ve planlama daha kritik hâle geliyor.
Bu özellik her senaryoda risksiz mi?
Kendi deneyimimden konuşuyorum, Hayır, açıkçası değil. Veri modeli uyumsuzsa ya da cutover iyi planlanmadıysa sorun yaşayabilirsiniz. Özellik işi kolaylaştırıyor, ama tasarım hatasını ortadan kaldırmıyor — bunu unutmamak lazım.
Küçük ekipler için uygun mu?
Evet, hatta bazı durumlarda özellikle uygun olabiliyor. Ama tecrübeme göre önce maliyet-fayda hesabını yapmak gerekiyor; çünkü her taşıma operasyonel efor istiyor.
Kaynaklar ve İleri Okuma
Orijinal Microsoft Azure Cosmos DB Blog Yazısı
Azure Cosmos DB Partitioning Overview — Microsoft Learn
Azure Cosmos DB’de GSI: Okuma Yükünü Hafifletmenin Pratik Yolu
Azure Cosmos DB vNext Emülatör: Yerelde Gerçek Gibi Test Etmek
Azure Cosmos DB’de Bölüm Bazlı Otomatik Failover: Sessiz Devrim

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











Yorum gönder