Azure DevOps’tan GitHub’a Kesintisiz Geçiş: ELM ile Yeni Dönem
Asıl mesele repo taşımak değil, işi durdurmamak
Bakın şimdi, repo taşımak deyince çoğu ekip hâlâ aynı şeyi düşünüyor: “Bir gece kapatırız, sabah acariz.” Kağıt üstünde basit. Pratikte işe o kadar da temiz değil. Mesela de yüzlerce pipeline, servis bağlantısı, branch policy, service hook ve birikmiş alışkanlık varsa… is biraz karışıyor. Ben bunu yıllardır görüyorum; hosting tarafında da gördüm, Azure geçişlerinde de gördüm, şimdi DevOps donusumlerinde de görüyorum. Taşıma işi teknikten çok operasyon meselesi oluyor.
İşin garibi, Microsoft’un duyurduğu Enterprise Live Migrations tam da bu can sıkıcı noktaya dokunuyor. Yanı “gelin her şeyi donduralim” demiyor; repo açık kalıyor, sen çalışmaya devam ediyorsun, arka planda değişiklikler GitHub’a akıyor. Açık konuşayım, bu yaklaşım kağıt üstünde fena değil, hatta bayağı iş görüyor. Çünkü büyük kurumlarda asıl kriz teknik değil; kesinti penceresini kim onaylayacak, hangi ekip ne zaman hazır olacak, değişiklik dondurma süresi nasıl yonetilecek… bunlar patlıyor.
Bak şimdi, Geçen yıl İstanbul’da bir finans müşterinde buna benzer bir senaryo yaşadık. Onlar Azure Repos’tan çıkmak istiyordu ama iki günlük freeze window acamiyorlardi; risk komitesi bırakın iki günü, dört saatlik kesintiye bile zor bakıyordu. O gün anladık ki “migration” dediğimiz şey aslında is sürekliliği planı gibi düşünülmeli. Sadece Git komutlarıyla olmuyor.
ELM ne yapıyor, ne yapmıyor?
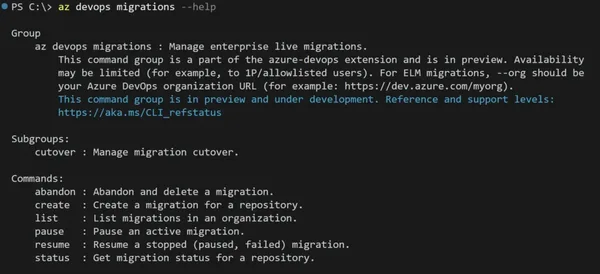
Enterprise Live Migrations’in mantığı basit ama etkisi iyi: önce hazırlık yapıyorsun, sonra sürekli esitleme başlıyor, en son kısa bir cutover ile GitHub’i sistem kaynağına çeviriyorsun. En güzel tarafı su — Azure DevOps reposu süreç boyunca kilitlenmek zorunda değil. Geliştirici kod yazmaya devam ediyor. Tahmin eder mısınız? Bu cümle küçük görünüyor ama enterprise tarafta altın değerinde.
Açıkçası, Şimdi gelelim sinirlarina. ELM su an sınırlı on izlemede ve GitHub Enterprise Cloud with data residency hedefliyor. Yanı her senaryoya uygun değil; özellikle hibrit kurgu kuran ekipler için dikkat etmek lazım (inanın bana). Bir de script tabanlı deneyim var su an; UI geliyor ama henüz masada değil (inanın bana). Bence bu doğru yöne — ki bu tartışılır — atılmış bir adım ama hâlâ biraz ham hissi veriyor (şaşırtıcı ama gerçek). Kurumsal ekiplerde aranan şey sadece çalışması değil; görünürlük ve kontrol de istiyoruz.
2019’da Ankara’da bir üretim firmasında klasik taşıma yöntemiyle uğraşmıştık. O zamanlar kısa pencere yoktu; mecburen gece yarısı kesip geçmiştik ve sabaha karşı bir build tanımı bozulmuştu. Küçük gibi görünür ama sabah 08:30’da onlarca geliştirici aynı anda hata alınca olay büyüyor (bizzat test ettim). Işte ELM’nın vaadi tam burada anlam kazanıyor: daha kontrollü geçiş.
İşte tam da bu noktada devreye giriyor.
Neden klasik yöntemler yoruyor?
Klasik migration yaklaşımı çoğunlukla “big bang” olur: ya hepsi geçer ya hiçbiri geçmez. Bu model küçük ekiplerde bazen idare eder ama enterprise ölçekte riskli (ciddiyim). Çünkü repository sadece kod değildir; commit geçmişi vardır, PR akisleri vardır, policy’ler vardır, release notları vardır… hatta bazı ekiplerde audit izleri bile ayrı kıymetlidir.
Bir de insan faktörü var tabi. Geliştiriciye “bugün öğleden sonra yazmayı bırakıyoruz” dediğinizde verim düşüyor. Iki gün freeze varsa işler Slack’te dönmeye başlıyor; herkes başka yere çekiliyor ve sonradan toparlamak eziyet oluyor.
Süreç nasıl ilerliyor? Adım adım bakınca daha net
Bunu üç aşamalı düşünmek iyi oluyor: hazırlık, esitleme ve cutover. Aslında dur… önce şunu söyleyeyim: hazırlık kısmını hafife alan ekiplerin çoğu sonra duvara tosluyor. Çünkü problem genelde taşıma anında çıkmıyor; öncesinde eksik envanter yüzünden çıkıyor.
- Start and validate: Repo hazır mi? Büyük dosyalar var mi? Branch policy’ler düzgün mu? Bağımlılıklar net mi?
- Continuous sync: Azure DevOps ile GitHub arasında değişiklikler es zamanlı akıyor.
- Cutover: Kısa bir final senkronizasyonu yapılıyor ve sistem kaynağı GitHub oluyor.
Aşağıdaki tabloyu ben müşterilerle konuşurken sık kullanıyorum çünkü karar verdirtiyor:
Bunu biraz açayım.
| Konu | Klasik taşıma | ELM yaklaşımı |
|---|---|---|
| Kesinti süresi | Saatler veya günler | Kısa cutover penceresi, genelde 30 dakikanın altında |
| Geliştirme akışı | Sıklıkla durur | Büyük ölçüde devam eder |
| Risk seviyesi | Daha yüksek | Daha kontrollü |
| Ekip koordinasyonu | Zorlayıcı olabilir | Daha esnek ilerleyebilir |
Peki, açık konuşayım, bu model startup için fazla ritüel gibi gelebilir ama enterprise için oldukça mantıklı. Küçük ekipseniz belki doğrudan planlı bir bakım penceresi açıp bitirirsiniz; büyük kurumsal yapıdaysanız böyle “tek seferde hepsini yakala” tarzı hareketler genelde pahalıya patlar.
Bence Türkiye’de en hayatı konu maliyet değil güven duygusu
Açık konuşayım, Türkiye’deki şirketlerle çalışırken şunu çok net görüyorum: herkes bütçeye bakıyor ama asıl karar güven üzerinden veriliyor (ben de ilk duyduğumda şaşırmıştım). “Bu geçiş yarıda kalır mi?”, “Yarın sabah pipeline’lar bozulur mu?”, “Audit tarafında sorun çıkar mi?” soruları masaya geliyor önce. Maliyet önemli tabi; ama yönetim katinda güven oluşmadan TL hesabı tek başına ikna etmiyor.
Eğer Azure üzerinde işletiyorsanız maliyet tarafını da kaba taslak düşünmek lazım.GitHub Enterprise Cloud with data residency seçeneği her organizasyon için ucuz olmayabilir; özellikle lisans sayısı büyüdükçe toplam sahip olma maliyeti artar (evet, rakamlar bazen can sıkabiliyor). Ama öte yandan (belki yanılıyorum ama) multi-day outage’in bedeli de boş değil: üretim kaybı, destek yükü ve itibar etkisi (yanlış duymadınız). bunları topladiginizda göreceksiniz ki ucuz sandığınız yöntem pahalıya geliyor (inanın bana) Bu konuyla ilgili GPT-5.2’nin Veda Notu: Copilot Ekipleri Şimdi Ne Yapmalı? yazımıza da göz atmanızı tavsiye ederim.
Evet, doğru duydunuz.
Bütçe kisitliyse benim önerim su olur: önce tüm portföyü taşımaya kalkmayın.Ican alıcı olmayan birkaç repo ile pilot yapın,pipeline bağımlılıklarını ölçün ve cutover prosedürünü prova edin (mesela test ortamında). Sonra dalga dalga gidin.Büyük kurumsalda bu yöntem çok daha sağlıklı oluyor çünkü ic paydas sayısı arttıkça sürprizlerin faturası da büyüyor.
Kesintiyi azaltmak tek başına başarı değil; asıl başarı geliştirme akisni bozmadan geçiş yapmak.
Peki ben olsam nasıl yaklaşırım?
AZ-305 sınavına hazirlaniyorken hep aynı prensibi tekrar etmisimd ir: teknoloji seçimi tek başına yetmez, işletim modeliyle uyumlu olmalı.ELM için de aynısını söylüyorum.Eğer organizasyonunuz change management konusunda disiplinliyse bu çözüm çok iyi oturur.Değilse önce süreçleri toparlamak gerekir;yoksa en iyi araç bile sizi kurtarmıyor. Bu konuyla ilgili .NET 11 ve Build 2026: Kaçırmamanız Gereken Oturumlar yazımıza da göz atmanızı tavsiye ederim.
Bunu Logosoft tarafında bir kamu müşterinde yaşadık diye hatırlıyorum.Ankara’da çalışan ekipte repo sayısı az değildi. Ownership dağınıktı.Önce hangi takımın hangi repodan sorumlu olduğunu netlestirdik,s sonra branch koruma kurallarını gözden geçirdik.Tasima sonunda teknik sorunlardan çok iletişim problemi cozdugumuzu fark ettik — enteresan şekilde asıl kazanç oradaydı (ciddiyim)
# Gecis öncesi pratik kontrol listesi
1) Repo envanterini cikar
2) Pipeline bagimliliklarini haritala
3) Service connection / secret / variable group listesini al
4) Branch policy'leri not et
5) Cutover rollback planini yazili hale getir
6) Pilot repo ile prova yap
7) Paydaslara net takvim paylas
Vallahi, Neyse uzatmayalım: ilk işin teknik taşıma aracı seçmek olmamalı.Ilk işin kapsam belirlemek olmalı.Hangi repolar tasinacak? Hangileri read-only kalacak? Hangi ekip cutover sırasında nöbetçi olacak? Bunları netleştirmeden başlayan proje genelde sürpriz verir… Bu konuyla ilgili Kubernetes’te Doğrulama Artık Kod Değil: v1.36’da Ne Değişti? yazımıza da göz atmanızı tavsiye ederim.
Klasik geçişe göre nerede fark yaratıyor?
Klasik yaklasimde çoğunlukla bütün ekip aynı anda beklemeye alinır.Bu da sprint ortasında yapılınca tam bir felaket senaryosu olabilir.ELM işe bunu yumusatmaya çalışıyor.Geliştiriciler işine devam ederken veri arkada kopyalanıyor — hani araba kullanırken bagaj düzenlemek gibi garip. Mantıklı bir his veriyor. Teams’te Çalışan Ajanlar: İşin Olduğu Yerde Başlamak yazımızda bu konuya da değinmiştik.
Gel gelelim her güzel fikrin eksisi olur.Burada da UI deneyimi henüz tamamlanmamış durumda;script tabanlı ilerlemek bazı ekipleri yorabilir.Kurumsal tarafta otomasyon seven biri olarak bana sorun olmaz ama change board sunumu yapacaksanız ekran görüntüsü isteyen yöneticiler çıkacaktır,o başka.Bu yüzden ürün olgunlaşana kadar belgelemeye ekstra önem vermek lazım.
- Pilot kapsamını dar tutun;
- Cutover saatini düşük trafik dönemine koyun; (bence en önemlisi)
- Rollback planını yazılı tutun; — ciddi fark yaratıyor
- Migrasyon sonrası erişimleri tekrar doğrulayın;
- Pipelines için smoke test hazırlayın.
Benim kişisel görüşüm şu: Microsoft burada doğru yere oynuyor. AI desteklı geliştirme dünyasında GitHub artık sadece depo değil,merkezî çalışma alanı hâline geldi.Azure DevOps’taki bazı kurumsal disiplinleri koruyup GitHub’daki hızla buluşturmak kötü fikir değil,aksine gayet makul. Bu konuyla ilgili azure ile ilgili önceki yazımız yazımıza da göz atmanızı tavsiye ederim.
}
Sıkça Sorulan Sorular
Enterprise Live Migrations nedir?
Azure DevOps reposunu GitHub Enterprise Cloud’a taşırken kesintileri minimuma indiren yeni bir migration yaklaşımı. Yanı repo büyük ölçüde kitlenmeden ilerliyorsun ve final geçiş kısa bir cutover penceresiyle tamamlanıyor.
Kod yazmayı tamamen durdurmak gerekiyor mu?
Açıkçası, Hayır, aslında ana fikir tam da bu zaten. Çoğu süreç boyunca Azure DevOps yazılabilir kalıyor ve değişiklikler sürekli eşitleniyor. Sadece final cutover sırasında kısa bir duraklama oluyor, o kadar.
Büyük şirketler için gerçekten uygun mu?
Şöyle ki, Evet, özellikle uzun downtime kaldıramayan kurumlar için daha mantıklı görünüyor. Ama yine de envanter, bağımlılık analizi ve rollback planı şart. Açıkçası hazırlığı zayıf olan bir ekipte mucize beklememek lazım.
Küçük ekipler bunu kullanmalı mı?
Birkaç repoysa klasik planlı geçiş yeterli olabilir. Ama gelecekte ölçeklenecekseniz erken denemek mantıklı, bence. En azından migration kasınızı geliştirirsiniz, fena olmaz.
Migrasyona başlamadan önce ilk ne yapılmalı?
Tüm repo envanterini çıkarın ve kritik pipeline bağımlılıklarını listeleyin. Sonra pilot olarak düşük riskli bir depo seçip prova yapın. Ben olsam üçüncü adımda paydaşlarla kesinti penceresini netleştiririm—aksi hâlde iş uzar gider.
Kaynaklar ve İleri Okuma
Enterprise Live Migrations Resmî Duyuru Yazısı
Azure Repos’tan GitHub’a Taşıma Dokümantasyonu
GitHub Enterprise Cloud Data Residency Belgeleri
Git depolarını GitHub’a taşırken asıl mesele ne?
Şunu fark ettim: Azure DevOps. GitHub: Yapay Zekâ Çağında Nereye Gidiyor? (ki bu çoğu kişinin gözünden kaçıyor)

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.







Yorum gönder