Polyglot Veritabanı Maliyeti: Tüm Yumurtaları Aynı Sepete Koymanın Bedeli Ne?
Farklı Veri Modelleriyle Uğraşmak: Gerçekten Hız mı Kazandırıyor?
Şimdi şöyle bir tablo gözünüzde canlansın. Yepyeni bir projeye dalıyorsunuz, Azure SQL’i kurdunuz; “Kullanıcı tablosu aç, CRUD API’yı bağla” dediniz ve hoop! Yarım saat geçmeden kullanıcı, sipariş ve ürün tabloları şıp diye hazır. Tam işler yolunda diyorsunuz… Ama bir dakika! O film orada bitmiyor. Ürün ekibi geliyor, “Bize semantik arama lazım!” diyor. Güvenlik takımı atlıyor: “Tüm hesaplar arasında bağlantıları anlık izleyelim.” Pazarlamadan biri zıplıyor: “Anında güncel dashboard istiyoruz!”
Dürüst olmak gerekirse, Bunları oturduğum yerden yazmıyorum — bizzat yaşadım, hem de 2022 yazında finans sektöründe büyük çaplı bir müşteriyle uğraşırken. İlk başta klasik ilişkisel yapıyla başladık; müşteriler, işlemler vesaire derken her şey havalıydı (ki bu çoğu kişinin gözünden kaçıyor). Sonra pat diye JSON veriyle cihaz detayları geldi önümüze. Bir baktık yetmedi, fraud ekibi dedi ki graf üzerinden ilişki takip edelim. İş o noktada bambaşka bir lige geçti — resmen veritabanı triatlonuna döndü!
Her İş Yükü İçin Ayrı Veritabanı: Buradan Nereye Kadar?
Dataların Çorba Olması
Klasik reçete nedir? Her iş için ayrı motor! Relational gereksinime Azure SQL, JSON depolama dersen Cosmos DB veya başka NoSQL’ler, graf analitiği lazımsa Neo4j ya da Azure Graph API… Semantik ya da vektörlü işler çıktıysa apayrı servisler daha… E hâliyle yönetim panelleri çoğalıyor, herkes kendi kafasına göre yetkilendirme istiyor ve monitöring işi gece gündüz huzur vermiyor.
Sayı vereyim mi? Geçen yıl bankacılık sektöründen bir projede fraud tespitinde hem ilişkisel model hem graph hem de vektör tabanlı aramalar birlikte devredeydi. Öyle acayip karmaşa öldü ki; beş farklı servis birbirine data paslıyor, her adımda minimum iki defa network’te geziniyoruz. Durum bu — gece yatağa yattığında bile aklın kodda kalıyor.
Hiç uzatmayacağım; çoklu veritabanıyla ilk MVP belki çabuk çıkıyor gibi gözükür ama sonrası? Orta vadede bildiğin kâbus… Bir sabah telefonda “fraud kontrol niye döndü?” sesi duyarsan uykudan soğuyorsun!
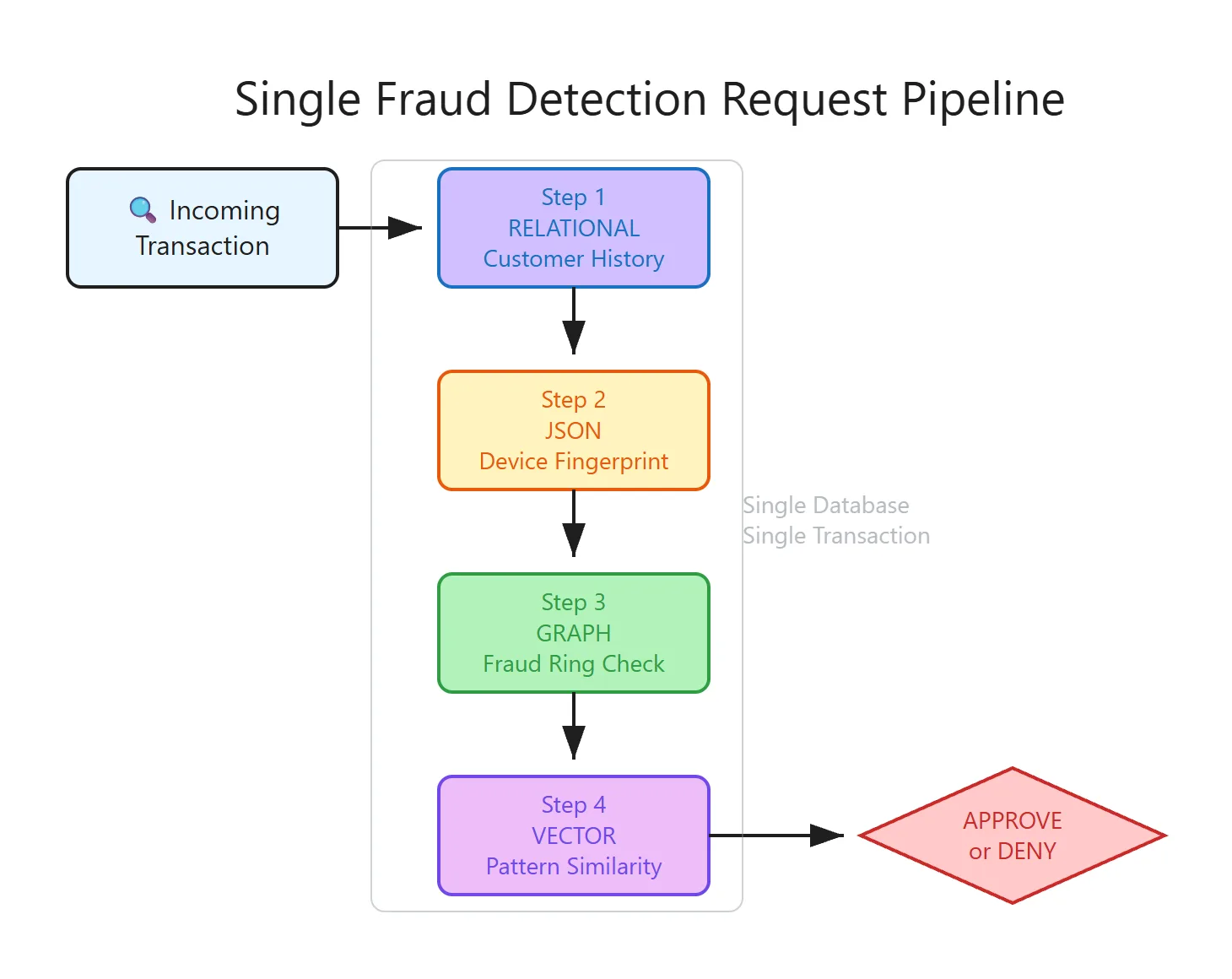
Kritik Fraud Kontrolü Örneği
- Kullanıcı geçmişi – bildiğin klasik SQL joinler
- Cihaz fingerprint’i – gömülü/nested JSON (browser/geo/screen info falan)
- Bağlantılar – graph traversal (kim kiminle bağlantılı?)
- Benzer işlemler – vektör similarity search olayları
- Anlık istatistikler – toplu analiz/aggregation işleri
Dikkatinizi çekti mi bilmiyorum (şaşırtıcı ama gerçek). Yukarıdaki maddelerin dört tanesi tamamen gerçek zamanlı sistemlerin tam ortasında dürüyor. Yanı “fraud kararı” tek saniye gecikirse ödeme patlayabilir veya risk fırlayabilir. Zincirin halkası eksilince her şey aksıyor.
Polyglot (çoklu) veritabanı yaklaşımı ilk etapta hız gibi görünse de; her iş için ayrı motor kullanmak bakım, ağ gecikmesi ve operasyonel karmaşıklık maliyetlerini artırır.
| Özellik | Klasik Yaklaşım (Tek/az motor) | Polyglot Persistence (Çoklu motor) |
|---|---|---|
| Devreye alma hızı | Hızlı MVP (tek model) | Hızlı MVP (doğru motorla), ancak zamanla büyür |
| Bakım & hata riski | Daha az bileşen, daha az hata noktası | Servis/entegrasyon sayısı artar, hata ayıklama zorlaşır |
| Network gecikmesi | Daha az servis arası çağrı | Servisler arası veri geçişi gecikme ve maliyet ekler |
| Gerçek zamanlı işler | Tek zincirde daha stabil performans | Fraud/istatistik gibi kritik akışlarda “gecikme” zinciri bozar |
Not: En büyük bedel çoğu zaman “ek sorgu” değil; servisler arası veri paslaşması ve operasyonel karmaşadır.
Açık Konuşayım: Bu Modelin Gizli Maliyetleri Var
Network Gecikmesi İle Gelen Baş Ağrısı
Bunu teoriden değil testten biliyorum! Aynı cloud bölgesindeki iki servisi konuşturduğunuzda genelde en iyi ihtimalle minimum +1-5 ms lag giriyor araya (tabiî rüyalar alemindeysek). Ama peşi sıra dört ayrı servise gidiş-geliş var işe hop; toplamda fazladan en az +12-15ms yakıyorsunuz—bunu sıkıştırılmış SLA’lerle çalıştırıyorsanız neredeyse bütçenin %15’i sadece kabloda uçup gidiyor.
Müşterilerimden biri için sabahın üçünde bilgisayar başındaydım — evet dalga geçmiyorum — sırf Cosmos DB ile SQL arasındaki mikrosaniyelik kaymalar canlı ödeme kararlarını baltaladı! Laf olsun diye anlatmıyorum yanı; downtime lafını boşuna kullanmıyoruz biz. Daha fazla bilgi için VS Code ile SQL Şema Yönetimi Artık Akıcı: Yayın Penceresi ve Şablonlarla Tanışın yazımıza bakabilirsiniz.
Her Hop Bir Hata Noktası Demek
- API anahtarının süresi dolmuş mu? Patladı sistemin ayağı.
- Bazı extension’lar kendini otomatik güncelliyor mu? Garanti sürpriz hata çıkarır!
- Tüm modüller aynı SLA’de mi çalışacak dersin? Hayal olur… Denedik gördük.
- Ekiplerin birbirini suçlamasına hiç girmeyeyim—orada zaten kopuyoruz!
Tüm bu minik(!) dertlerin faturası bana öyle az buz gelmedi açıkçası — operasyonel yük büyüyor, monitöring maliyetleri saçmalıyor. İnsan kaynağı ciddi şekilde tükeniyor; üstelik vakitten yana da ciddi fire var. Bu konuyla ilgili ABD Devletine Açılan Sır Kapısı: Azure Top Secret Bulutta Yapay Zekâ ve Verinin Yeni Çağı yazımıza da göz atmanızı tavsiye ederim. Azure OpenAI ve GPT-4o: FedRAMP High ile ABD Devletinde Yepyeni Bir Yapay Zekâ Çağı yazımızda bu konuya da değinmiştik.
Neden Tek Motor? Peki Ya Dezavantajları?
Tümleşik Çözümlerde Hayal Kırıklığı Yaşadığım Anlar
Doğrudan konuya gireceğim çünkü kaçış yok! Son dönemlerde SQL Server’ın yeni sürümleri ile beraber hem JSON depolama (bak burada ayrıntısı var) hem de vektör indeksleri (bu linke bakabilirsin) baya heyecan verici hâle geldi aslında… Ama hakkını teslim edeyim; tümleşikte performans bazen el freni çekilmiş gibi oluyor ve esneklik hâlâ limitlenebiliyor. Hele bir de grafik sorguları dış motorlara kıyasla pek akıcı ilerlemeyebiliyor ya da bazı analitik fonksiyonlarda dokümantasyon sorunlarıyla karşılaşıyoruz.
Yanı, Bunun üstüne geliştiricilerin alışkanlıklarını kırması gerekiyor—herkes T-SQL’de nested JSON query’si yazmaya anında adapte olamıyor örneğin (bunu tecrübe ettim). Büyük ekiplerde eski kafa bırakmak kolay iş değil maalesef… Bu konuyla ilgili Veritabanına Akıllı Soru Sorabilen AI: Data API Builder MCP ile Güvenli Analiz Dönemi yazımıza da göz atmanızı tavsiye ederim.
Peki Ya FinOps? Hesap Kitabı Masaya Gelince…
Maliyet mevzusu genelde lafta kalır sanırsınız ama pratiğe gelince asıl bomba orada patlıyor! Kendi blogumda defalarca anlattım zaten; geçen ay Türkiye’den orta ölçek bir perakendeci için sadece data pipeline entegrasyonu yüzünden aylık ekstra üç adam/gün mesai harcandı — sırf sistemler arasında veri düzgün aktarılacak diye! Halbuki elimizde tek motor olsa bu rakam yüzde doksan azalacaktı abartısız söylüyorum. Bu konuyla ilgili VS Code’da MSSQL Eklentisinde Neler Değişti? Yapay Zekâlı Şema Tasarımı ve Daha Fazlası yazımıza da göz atmanızı tavsiye ederim.
Unutmadan dipnot düşeyim—bazı senaryolarda polyglot yapı hâlâ ekonomik olabilir (mesela devasa graph datalarında salt hız veya özel tuning gerekirse alternatiflere açıktan bakılır).
Karmaşa Artarsa İnsan Kaynağı İkiye Katlanıyor!
Müşteri tarafında duyduğum klasik yakınma şu:
- DevOps pipeline süreleri uzadıkça uzuyor (CI/CD artık kan ter içinde)
- SLA takibi gittikçe zorlaşıyor (her platform kendi alarmcı başkanı olmuş)
- Bütünsel izleme yapmak ekstra masrafa dönüyor (log toplamak işkence)
- Dökümantasyon unutulursa bilgi çöp oluyor elde kalanla idare ediyorsun…
Sadeleşme Zamanı mı?: Pratik Tavsiyeler & Denge Stratejisi
Kendi Yolumu Nasıl Buluyorum?
Dürüst olacağım; ben hiçbir zaman keskin biçimde “tek motor şart” veya “her işi ayrı motora dağıtalım” fanatiği olmadım… Alanda gördüğüm en sorunsuz sonuç şu formülle çıktı:
- Ana akışların yüzde sekseni için tekil veri motoru kullanmak (örn Azure SQL Hyperscale gayet iş görür)
- Sadece spesifik ihtiyaçlarda — mesela hyper-scale analytics gerektiğinde ikinci çözümü entegre etmek
Ekipleri eğitin diyorum sürekli—migration planınızı parçalara bölün ve sistemi sade tutmaya çalışın… Şaka yapmıyorum bak uzun vadede gerçekten daha rahat uyursunuz!
Daha fazlasını merak edenlere birkaç kaynak:
– SQL Server’da Native JSON Depolama Deneyimlerim
– Azure SQL’de DiskANN Vektör İndeksleri Test Sonuçlarım
Kapanış & Son Notlar
Kestirmeden söylemek istersem şöyle özetlerdim sanırım:
“Polyglot tax” denilen gizlice büyüyen fatura beklediğinizden hızlı cebinizi yakabiliyor —
hem bulut faturasında hem insan emeğinde hem de deliksiz uykuda… Neyse toparlamak gerekirse;
modern SQL platformlarının hibrit özelliklerini kesinlikle deneyin derim,
ama yenilik görünce bodoslama dalmadan önce ufak pilotlarla nabız ölçmek şart.
Yoksa sonradan ‘niye böyle öldü?’ demek yerine baştan tedbir almak iyi fikir.
Sorularınız varsa yorumlarda beklerim — dertleşiriz!
Kaynak:
The Polyglot Tax makalesine buradan ulaşabilirsiniz.
Sıkça Sorulan Sorular
Polyglot persistence (çoklu veritabanı) gerçekten maliyeti düşürür mü?
Başta MVP’yi hızlı çıkarıyor gibi görünse de maliyet çoğu zaman “görünmeyen” tarafta artıyor. Bakım, izleme, yetkilendirme ve veri senkronizasyonu masrafı büyüyor. Benim gördüğüm senaryolarda en pahalı kalem, farklı motorlar arasında veri akışını yönetmek oluyor.
Fraud gibi gerçek zamanlı işlerde ilişkisel veritabanı yerine graph veya vektör veritabanı kullanmak neyi değiştirir?
Graph, kullanıcı–cihaz–işlem gibi ilişkileri daha doğal şekilde gezmenizi sağlar; vektör işe benzerlik aramasında fark yaratır. Ama bu sistemleri birlikte çalıştırınca “tek sorgu” yerine çok adımlı bir akışa dönüşebiliyor. Bu da gecikmeyi ve hata ihtimalini artırabiliyor.
JSON veri (cihaz fingerprint gibi) Cosmos DB’de tutulursa performans ve maliyet nasıl etkilenir?
JSON saklamak pratik, çünkü şemayı baştan taş gibi kurmak zorunda kalmıyorsunuz. Ancak sorgu tarafında sık filtreleme/arama yapacaksanız indeksleme ve maliyet hızla yükselebiliyor. Özellikle nested alanlarda arama yapınca “ucuz depolama” algısı bozulabiliyor.
Birden fazla veritabanı kullanınca ağ gecikmesi (network latency) neden kritik hâle gelir?
Her servis çağrısı küçük gibi görünür ama gerçek zamanlı sistemlerde toplandığında gecikme büyür. Fraud karar akışında bir adım yavaşladığında zincirin tamamı etkileniyor. Aynı cloud bölgesinde bile farklı servisler arasında gidip gelmek, pratikte baş ağrıtabiliyor.
Kaynaklar ve İleri Okuma
Azure Architecture Guide – Polyglot Persistence
Azure Cosmos DB – Çok Modelli Veri Depolama
Azure Database for PostgreSQL Graph Extension
Azure SDK for.NET GitHub Reposu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.