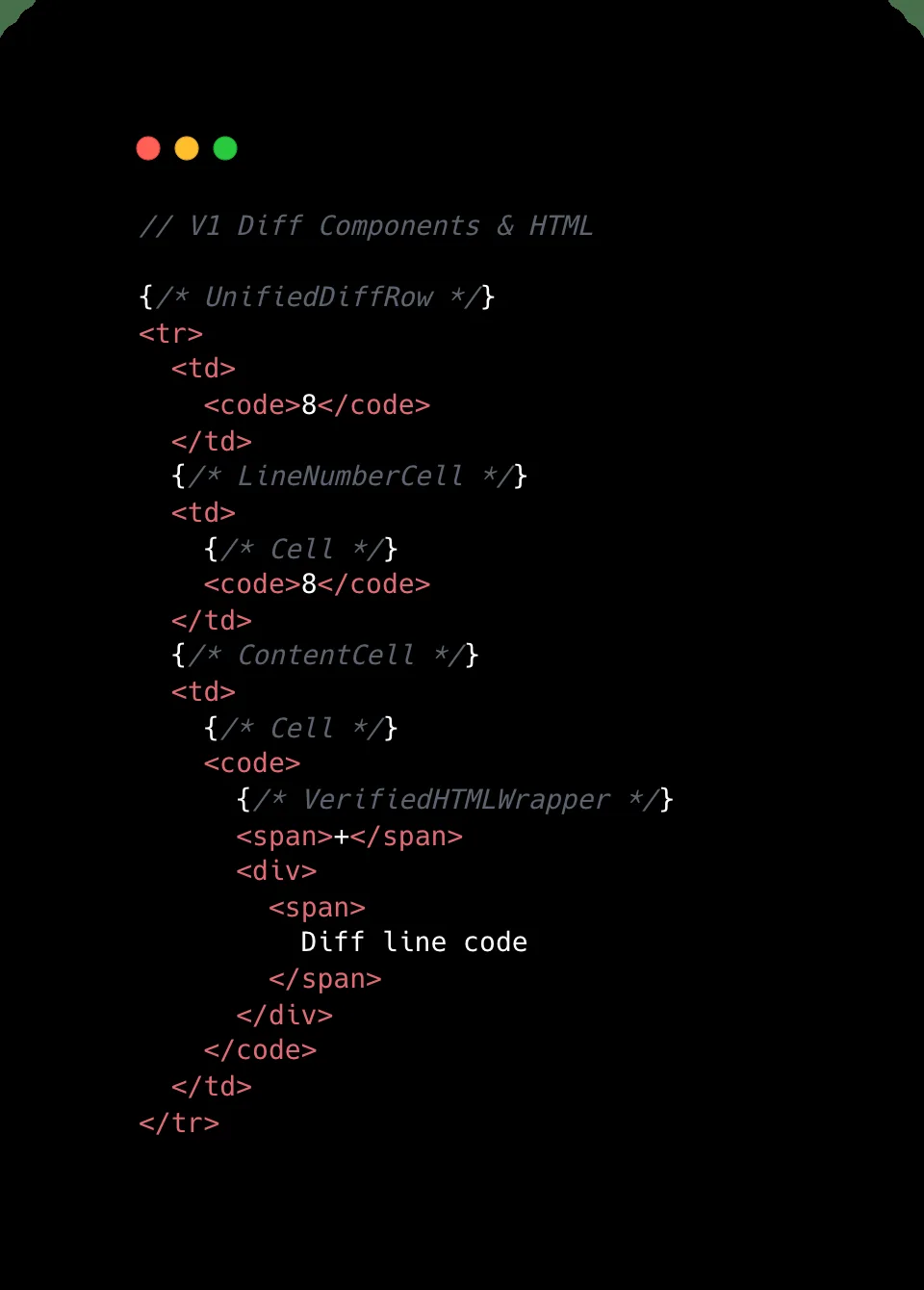
Pull request ekranı, açık konuşayım, GitHub’ın kalbi gibi. Kodun konuştuğu yer orası. Ben de yıllardır hem (söylemesi ayıp) hosting tarafında hem Azure danışmanlığında şunu defalarca gördüm: küçük bir diff akıp giderken kimse ses etmez, ama iş binlerce dosyaya ve yüzbinlerce satıra gelince tarayıcı bir anda nefes nefese kalıyor. İşte mesele tam burada başlıyor (en azından benim deneyimim böyle)
Dürüst olmak gerekirse, Bu yazıda GitHub’ın diff satırlarını performanslı hâle getirirken neden tek bir “sihirli çözüm”e abanmadığını kendi gözümden anlatacağım. Çünkü sahada da öyle oluyor; bir bankacılık projesinde, 2024 sonbaharında İstanbul’daki ekiplerle çalışırken bunu birebir gördük. Her şeyi aynı anda düzeltmeye kalkınca başka yerden patlıyor. Hani klasik hikâye: performansı iyileştiriyorsun, bu sefer native arama bozuluyor… olmuyor.
Büyük pull request’lerde asıl dert sadece “hız” değil; hızla birlikte hafıza kullanımı, etkileşim gecikmesi ve kullanıcıya hissettirmeden yükü yönetmek. Kâğıt üstünde kolay, pratikte biraz inatçı.
Neden büyük diff’ler ayrı bir problem?
Küçük değişikliklerde sistem zaten işini görüyor (ben de ilk duyduğumda şaşırmıştım). Ama on binlerce satırlık bir PR açıldığında olay değişiyor; DOM düğümleri şişiyor, JavaScript heap büyüyor, etkileşim gecikiyor ve kullanıcı “neden tıklayınca geç açılıyor?” diye düşünmeye başlıyor. GitHub tarafında ölçülen bazı uç örneklerde heap’in 1 GB’ı aştığı, DOM node sayısının 400 bini geçtiği söyleniyor. Bu rakamları okuyunca insanın içinden “tamam ya, burası artık normal web sayfası değil” demesi geliyor.
Benzerini ben 2019’da kendi lab ortamımda yaşamıştım; Azure üzerinde çalışan iç araçlarımızda çok satırlı log gösterimi yaparken ekranlar tatlı tatlı ağırlaşmıştı. İlk bakışta her şey düzgün görünüyordu ama birkaç büyük kayıt açınca tarayıcı sanki çay molasına çıkıyordu. O gün şunu net anladım: performans sorunları genelde günlük kullanımda bağırmaz, köşeye sıkışınca ortaya çıkar.
Bunu biraz açayım. Visual Studio’da Copilot Mart 2026: Ajan Devrimi yazımızda bu konuya da değinmiştik.
GitHub’ın Files changed sekmesini React tabanlı yeni deneyime taşıması da aslında bu yüzden önemliydi. Yeni yapı modern bir zemin sağlıyor ama zeminin modern olması yetmiyor; üstüne koyduğun bileşenlerin de hafif olması gerekiyor. AZ-305’e hazırlanırken mimarı kararların birbirine zincirleme etkisini çok çalışmıştım — burada da mantık aynı. Bir yerde yaptığın seçim başka yerde maliyet çıkarıyor (ciddiyim)
Tek çözüm yoksa ne var?
Bakın, İşin aslı şu ki, büyük PR problemini çözmek için üç ayrı cephe açmak daha mantıklı görünüyor: ana diff deneyimini hızlandırmak, en büyük pull request’lerde kontrollü biçimde sadeleşmek ve altyapıyı herkes için güçlendirmek. Yani bütün kullanıcıları aynı torbaya atıp “alın size hız” demek yerine, senaryoya göre farklı taktik kullanmak gerekiyor.
Çok konuştum, örnekle göstereyim.
Mesela küçük bir startup düşünün. Orada ekip daha az dosyayla çalışıyor olabilir; native find-in-page davranışı onlar için kritik olur çünkü geliştirici akışı doğrudan ona bağlıdır. Enterprise tarafta işe durum bambaşka… Bir telekom müşterimizde 2023 yazında buna benzer bir şey yaşamıştık; inceleme yapılan change set o kadar büyüktü ki asıl öncelik “kusursuz davranış” değil “kullanılabilirlik” olmuştu.
| Yaklaşım | Ne işe yarıyor? | Taviz |
|---|---|---|
| Hedefli diff-line iyileştirmeu | Çoğu PR’da akıcı deneyim verir | Bazı karmaşık edge-case’ler kalabilir |
| Sanallaştırma | Aşırı büyük PR’larda sistemi ayakta tutar | Tam doğal tarayıcı davranışı azalabilir |
| Temel rendering iyileştirmeleri | Tüm deneyime yayılır | Etkisi dolaylı gelir, hemen görünmeyebilir |
Neyse uzatmayalım; burada en sevdiğim nokta şu oldu: yaklaşım katmanlı kurulduğunda ürün ekibi gerçekten rahat ediyor. Çünkü orta ölçekli PR’da gereksiz taviz vermiyorsun, devasa PR’da işe uygulama çökmüyor. Bence fena değil, hatta baya işe yarayan denge bu.
Düğümü nerede sıkıştırmışlar?
Render yükünü azaltmak
Bunu yaşayan biri olarak söyleyeyim, Büyük listeler ya da yoğun diff blokları render edilirken en çok yoran şeylerden biri gereksiz yeniden çizimler oluyor. Bu bazen göze görünmüyor ama tarayıcının içinde küçük küçük borçlar birikiyor gibi düşünün; sonunda ödeme günü geliyor. Sayfa takılıyor.
Şunu söyleyeyim, Ben Logosoft’ta 2025 başında yaptığımız bir kurumsal portal revizyonunda benzer mantığı kullandık (bu beni çok şaşırttı). O ekranda kart sayısı arttıkça kullanıcı tepkisi kötüleşiyordu; biz bileşenleri parçalara ayırıp sadece görünen alanları optimize edince hissedilir rahatlama oldu. Buradaki ders netti: her şeyi aynı anda boyamak zorunda değilsin (ben de ilk duyduğumda şaşırmıştım)
Bunu biraz açayım. Bu konuyla ilgili C# 15’te Union Types: Eksik Parça Nihayet Geldi yazımıza da göz atmanızı tavsiye ederim.
Etkileşim gecikmesini düşürmek
INP gibi metrikler laf olsun diye konulmuyor. Kullanıcı tıklıyor mu? Klavyeye basıyor mu? Sayfa bunu ne kadar hızlı karşılıyor? Asıl his burada yatıyor işte… GitHub’ın yaptığı işlerden biri de tam olarak bu duyumu iyileştirmek olmuş görünüyor.
Açık söyleyeyim, birçok ekip önce FPS konuşur sonra uzun uzun tartışır. Gerçek hayatta geliştirici için en can sıkıcı olan şey çoğu zaman “klikledim ama tepki geç geldi” hissi oluyor (yanlış duymadınız). Bu konuda %100 emin değilim ama sanırım insan beyni gecikmeyi mükemmel yakalıyor; milisaniyelik fark bile moral bozabiliyor! Bu konuyla ilgili Gemini API’de Maliyet ve Hız Dengesi: Flex ile Priority yazımıza da göz atmanızı tavsiye ederim.
Bellek baskısını yönetmek
Bellek konusu çoğu zaman ikinci planda kalıyor çünkü ilk bakışta görünmez. Fakat heap büyüdüğünde tablo — ki bu tartışılır — değişiyor; sistem hâlâ çalışıyor gibi görünürken arkada yavaş yavaş hava kaçırmaya başlıyor gibi oluyor (evet biraz mecazi anlattım. Sahada tam da böyle).
// Basit düşünce modeli
if (prSize < medium) {
usePrimaryDiffExperience();
} else if (prSize < huge) {
optimizeRenderingAndKeepNativeBehavior();
} else {
gracefullyDegradeWithVirtualization();
}Küçük ekip mi, enterprise mı?
Küçük ekiplerde beklenti genelde nettir: mümkün olduğunca doğal davranış, mümkün olduğunca az sürpriz! Dosya içi arama düzgün çalışsın, kod inceleme akışı bölünmesin yeterli çoğu zaman.
Şahsen, Enterprise tarafında işe denge değişiyor. Bir finans kuruluşunda geçen yıl yaptığımız değerlendirmede tek pull request içinde hem güvenlik hem altyapı hem uygulama katmanı değişmişti; inceleme süresi uzadıkça kullanıcı memnuniyeti değil sabrı düşüyordu — dürüst olayım, biraz hayal kırıklığı —. Böyle durumlarda kapsamlı ama kontrollü sadeleşme hayat kurtarıyor. GPT-5.1 Codex Modelleri Emekli Oldu: Ne Yapmalısınız? yazımızda bu konuya da değinmiştik.
- Küçük startup: Tam özellik seti ve doğal kullanım daha değerli olabilir.
- Büyüyen ürün ekibi: Orta seviye iyileştirmelar şart olur.
- Kurumsal ölçek: En kötü senaryoyu ayakta tutacak emniyet kemeri gerekir.
- Aşırı büyük PR: Sanallaştırma bazen kaçınılmaz hâle gelir.
E tabii burada güzel olan şu: iyi tasarlanmış temel iyileştirmeler herkese yarar sağlıyor. Ben buna hep altyapının sessiz kazancı diyorum; kimse alkışlamaz ama herkes faydasını hisseder.
Peki sahada ne öğreniyoruz?
Bence en önemli ders şu oldu: performans projelerinde erken ölçüm şarttır ama tek başına yetmez… Sonra tekrar ölçersin çünkü ilk ölçüm seni yanıltabilir! En çok da de arayüzde gözle görülmeyen darboğazlar varsa metrikler ile gerçek his arasında fark olabiliyor. Bu konuyla ilgili Copilot Cloud Agent İçin Kurumsal Firewall: Kontrol Sizde yazımıza da göz atmanızı tavsiye ederim.
Aslında, Copilot Cloud Agent ve GitHub Codespaces tarafında kurumsal müşterilerle konuşurken de aynı şeyi görüyorum aslında; kontrol mekanizmaları arttıkça deneyim biraz karmaşıklaşıyor ama doğru kurgulanırsa güven kazanıyorsun. Performansta da durum benzer — hızlı olmak güzel, fakat sürdürülebilir hızlı olmak daha kıymetli.
Bir arkadaşım Ankara’da bulunan ekibinde geçen sene benzer bir diffs problemi yaşadı; ilk etapta sadece virtualization düşündüler ama sonra native find davranışını korumak isteyen geliştiricilerden itiraz geldiğini anlattı bana telefonla… Sonunda hibrit model kurdular ve üç hafta sonra herkes biraz daha sakinledi. Beklediğim kadar değildi dedikleri nokta şuydu: bazı kullanıcılarda algılanan hız teknik metrikten daha önemli çıkmıştı.
Performans işi yalnızca benchmark grafiği değildir; kullanıcı “takıldı mı takılmadı mı?” diye bakar, gerisi ikinci perde gelir.
Sahadan çıkan kısa notlar
– Önce en yaygın senaryoyu hızlandır.
– Sonra aşırı uçları koruma altına al.
– Temel bileşeni iyileştirirsen etkisi her yere yayılır.
– Her tavizin bedeli olduğunu unutma.
– Ölçmeden yaptığın optimize etme biraz kumar gibidir;
Sıkça Sorulan Sorular
Büyük pull request neden yavaşlıyor?
Daha fazla satır render edildiği için DOM ve bellek yükü artıyor. Bu da etkileşim gecikmesine yol açabiliyor.
Sanallaştırma her durumda doğru çözüm mü?
Hayır, değil! Çok büyük PR’larda işe yarar ama günlük kullanımda doğal davranışlardan ödün verebilir.
Neden tek bir optimizasyon yeterli olmuyor?
Çünkü sorun genelde render, bellek ve etkileşim tarafına yayılıyor. Bir noktayı düzeltince diğer dar boğaz ortaya çıkabiliyor…
Küçük ekipler bu tip iyileştirmelerden nasıl etkilenir?
İlginç olan şu ki, Küçük ekipler genelde doğal tarayıcı davranışını önemsediği için dikkatli denge gerekir. Hız kadar alışkanlıkların bozulmaması da önemlidir.
Kaynaklar ve İleri Okuma
Şahsen, Orijinal GitHub mühendislik yazısı
MDN — Intersection Observer API
web.dev — Interaction to Next Paint (INP)
İçeriği paylaş:
İlgili Yazılar


📬 Bu yazıyı faydalı buldunuz mu?
Azure, DevOps ve bulut teknolojileri hakkında güncel içerikler için beni takip edin!


Gamze E.
5000 satır diff açtığımda tarayıcının neden donduğunu hiç bu kadar net anlamamıştım. Sanal listeleme kısmı özellikle ilgimi çekti, bunu kendi araçlarımda da deneyebilirim. Bu arada şu yazınız da güzeldi: OpenAI Neden Bir Medya Şirketi Satın Aldı: TBPN — https://www.askinkilic.com.tr/openai-neden-bir-medya-sirketi-satin-aldi-tbpn/










1 yorum