AI Agent’larda Sohbet Geçmişi: Nerede Saklamalı?
Herkes AI agent deyince modelden, prompt’tan, araç entegrasyonlarından bahsediyor. Hani şöyle bir şey — modelin ne kadar zeki olduğu, hangi tool’ları çağırdığı, system prompt’un ne kadar iyi yazıldığı… Bunlar önemli tabi. Ama açık konuşayım, kurumsal projelerde benim en kilit mimarı kararlarımdan biri, kimsenin pek havalı bulmadığı şu mesele: sohbet geçmişi nerede duracak?
📋 İçindekiler
-
Şimdi gelelim işin can alıcı noktasına.
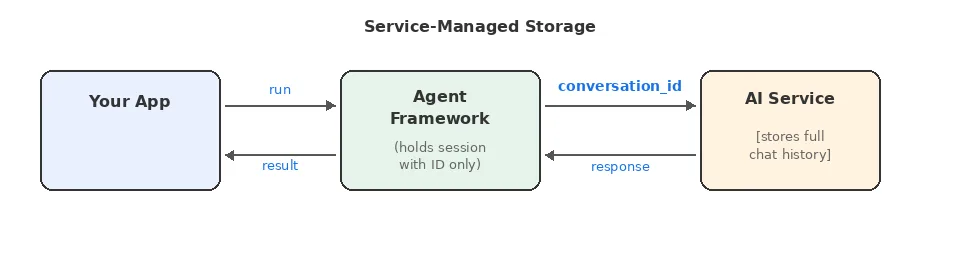
Azure AI Foundry Agent Service
Dürüst olmak gerekirse, Burası direkt servis yönetimli tarafta dürüyor. Konuşmalar thread olarak sunucu tarafında saklanıyor, Agent Framework de bir
thread_idtutup yeni mesajları oraya ekliyor; ilk bakışta sade görünüyor ama asıl olay detaylarda başlıyor, çünkü dosya arama ve kod yorumlama gibi yetenekler bu thread bağlamına yaslanarak çalışıyor.Kötü tarafı da var tabi: veriler Azure’da kalıyor. Bakın,. Dur bir saniye — Türkiye’deki bazı müşteriler için bu aslında avantaj bile olabiliyor, çünkü Azure’un Türkiye bölgesi var. Veri yerelliği konusu rahatlıyor; yine de compaction kararını Microsoft verdiği için sizin eliniz o kadar uzun olmuyor (yanlış duymadınız)
Evet.
Ha bu arada, Foundry Agent’a MCP ile Özel Araç Bağlamak yazımda bu servisin MCP entegrasyonundan bahsetmiştim. O konu da ayrı önemli, çünkü sohbet geçmişiyle araç çağrılarını birlikte düşünmezseniz sonra küçük görünen şeyler büyüyebiliyor.
Anthropic Claude
Claude’un Messages API’si tamamen istemci yönetimli çalışıyor (şaşırtıcı ama gerçek). Her istekte konuşmanın tamamını tekrar gönderiyorsunuz, sunucuda hiçbir şey tutulmuyor; yanı yaklaşım net, temiz ve gizlilik açısından da anlaşılır bir çizgide ilerliyor (ben de ilk duyduğumda şaşırmıştım)
Açıkçası, Ama işte bir yerde bedel çıkıyor: konuşma uzadıkça token maliyeti artıyor, bazen de gereksiz şişiyor gibi hissediyorsunuz; kısa senaryolarda idare ederken uzun oturumlarda “hmm, bunu biraz daha akıllıca kesmek lazımdı” dedirtiyor insana.
Microsoft Agent Framework Bunu Nasıl Çözüyor?
Açık konuşayım, Burada iş biraz rahatlıyor, hatta beklediğimden az uğraştırıyor (inanın bana). Microsoft Agent Framework, farklı sağlayıcıların değişik depolama modellerini tek bir soyutlama katmanında topluyor; AgentSession da hem servis yönetimli hem istemci yönetimli depolamayı destekliyor,. Kodu bir kere yazıp alttaki sağlayıcıyı değiştirdiğinizde sohbet geçmişi tarafı kendi kendine uyum sağlıyor.
Bunu kodla gösterince daha net oluyor. Mesela istemci yönetimli bir yapıda geçmişi böyle tutarsınız:
# Microsoft Agent Framework ile basit bir sohbet gecmisi yönetimi from agent_framework import AgentSession, ChatHistory session = AgentSession(provider="openai", storage="client") # Gecmis mesajlari ekle session.history.add_user_message("Azure'da maliyet nasıl dusurulur?") session.history.add_assistant_message("Ilk olarak reserved instances...") # Compaction stratejisi tanimla session.set_compaction( strategy="sliding_window", max_messages=20, summarize_older=True ) # Istek gonder — framework gecmisi otomatik yonetir response = session.send("Peki spot VM'ler ne kadar tasarruf sağlar?")Şöyle söyleyeyim, Bu örnek biraz sade tutulmuş, ama olay tam olarak bu. Framework, hangi sağlayıcıyı kullanırsanız kullanın aynı arayüzü veriyor; güzeli de şu ki, compaction stratejisini değiştirmek istediğinizde bazen tek yaptığınız şey bir parametreyi oynatmak oluyor, başka bir yere dokunmadan ilerleyebiliyorsunuz.
💡 Bilgi: Microsoft Agent Framework’te compaction stratejileri arasında sliding window (kayan pencere), summarization (özetleme), truncation (kirpma) ve tool-call collapse (araç çağrısını daraltma) seçenekleri var. Hangisini seçeceğiniz konuşmanın türüne ve token butcenize bağlı.Türkiye’deki Kurumsal Gerçeklik
Hmm, bir düşüneyim… Türkiye’de bu konuyu biraz farklı yapan birkaç şey var.
Kısa bir not düşeyim buraya.
Birincisi KVKK. Kişisel veriler yurt dışına çıkacaksa açık rıza ya da yeterli koruma kararı gerekiyor. Bir müşteri destek chatbot’u düşünün; kullanıcılar TC kimlik numarası, adres, telefon gibi bilgileri rahatça yazabiliyor, sonra o verilerin OpenAI’ın ABD sunucularında durduğunu fark edince işler bir anda hassaslaşıyor. Bu yüzden Türkiye’deki çoğu kurumsal projede istemci yönetimli depolama tercih ediliyor, veriler Azure Turkey West ya da on-premise sistemlerde tutuluyor.
İkincisi maliyet tarafı. TL bazında bakınca her istekte binlerce token göndermek açık konuşayım can sıkıyor. Geçen ay bir e-ticaret firmasının chatbot’ünü incelerken ortalama konuşmanın 45 mesaj sürdüğünü gördük. Compaction yapılmadığı için her istekte 8000+ token gidiyordu; küçük gibi duran bu detayın faturaya nasıl yansıdığını görünce ekip de şaşırdı. Sadece sliding window compaction ekleyerek token maliyetini %60 düşürdük, aylıkta da kabaca 12.000 TL tasarruf çıktı. AI Maliyet Optimizasyonu: ROI’yi Gerçekten Artırmanın Yolu yazımda buna benzer iyileştirmelardan. Bahsetmiştim.
Üçüncüsü multi-model stratejisi. Türkiye’deki büyük şirketler tek sağlayıcıya bağlanıp kalmak istemiyor, haklılar da; bugün OpenAI kullanırsınız, yarın Anthropic’e geçersiniz ya da yerel bir modeli denersiniz (bazı senaryolarda bu geçiş beklediğinizden daha hızlı oluyor). Tahmin eder mısınız? İstemci yönetimli depolama burada esneklik sağlıyor, servis yönetimli yapıda işe geçmişiniz bir sağlayıcıya kilitlenebiliyor ve işin aslı geçiş maliyeti baya yükseliyor (bu konuda ikircikliyim)
Ve işler burada ilginçleşiyor.
Peki Hangisini Seçmeliyim?
Bence olaya şöyle bakın:
Yanı, Küçük bir ekipseniz, hızlıca prototip çıkarıyorsanız: Servis yönetimli tarafla başlayın. OpenAI Responses API’deki
store: truemodu ya da Azure AI Foundry Agent Service burada baya iş görüyor. Compaction, kalıcılık, bağlamı toparlama gibi dertleri servis üstleniyor, sız de ürünü biraz daha rahat kurcalıyorsunuz.Bir şey dikkatimi çekti: Enterprise seviyede, regülasyona takılan bir iş yapıyorsanız: İstemci yönetimli depolama daha mantıklı. Nokta. Verinin nerede durduğunu bilmek istiyorsunuz, compaction stratejisini sız kontrol etmek istiyorsunuz, bir de sağlayıcıya fazla bağlı kalmak istemiyorsunuz. Evet, işi artırıyor. Bakın, ama açık konuşayım, bunu başta yapmazsanız sonra çok daha pahalıya patlıyor.
İkisinin ortasındaysanız: Hibrit yaklaşımı deneyin. Microsoft Agent Framework bunu destekliyor — bazı agent’lar servis yönetimli çalışırken bazıları istemci yönetimli gidebiliyor. Mesela dahili test ortamında servis yönetimli kullanıp production’da istemci yönetimli seçmek fena fikir değil.
Ne yalan söyleyeyim, Az önce “servis yönetimli kolay” dedim. Dur bir saniye — kolay olması her zaman doğru olduğu anlamına gelmiyor. Bir arkadaşım startup’ında öyle başladı, sonra 6 ay sonra SOC 2 sertifikasyonuna koşarken bütün mimariyi elden geçirmek zorunda kaldı; 3 haftalık geliştirme süresi resmen buhar öldü.
Bu arada Cosmos DB’de AI Maliyet Optimizasyonu: 7 Pratik İpucu yazım da işinize yarayabilir — özellikle sohbet geçmişini Cosmos DB’de tutacaksanız, orada maliyeti biraz aşağı çekebileceğiniz taktikler var.
Evet.
Pratik Önerilerim
Lafı gevelemeden, ben olsam şöyle ilerlerdim:
- İlk gün veri lokasyonu kararını verin. Bu işin başında alınan karar, bütün mimariyi etkiliyor; sonradan “aa burayı başka yerde tutsak mıydık” demek baya can sıkıyor.
- Compaction stratejinizi erken tasarlayın. Sliding window çoğu senaryoda fena başlamıyor, ama konuşmalar uzuyorsa bir noktada summarization eklemek gerekiyor, yoksa bağlam şişiyor ve sistem garip davranmaya başlıyor. (bu kritik)
- Token bütçesi hesaplayın. Ortalama konuşma uzunluğunu kabaca çıkarın, context window sınırını net bilin, sonra da aylık maliyeti hesaplarken biraz pay bırakın; çünkü şey, gerçek kullanım kağıttaki gibi gitmiyor. — bunu es geçmeyin
- Sağlayıcı bağımsızlığını test edin. En az 2 sağlayıcıyla aynı akışı döndürebildiğinizi doğrulayın, yoksa bir gün tek bir servise fazla yaslandığınızı fark edince iş zorlaşıyor; Microsoft Agent Framework bu tarafta işi epey kolaylaştırıyor.
- Branching ihtiyacını değerlendirin. Kullanıcılarınız “geri al ve tekrar dene” diyorsa, geçmişi ağaç yapısında tutmayı düşünün; bu arada bu sadece istemci yönetimli modelde mümkün oluyor, yanı sunucu tarafında her şeyi sihirli biçimde çözeyim beklentisi pek işlemiyor. — ciddi fark yaratıyor
Evet.
Neyse uzatmayayım, yukarıdaki beş maddeyi ilk günden masaya koyarsanız sonradan daha az sürpriz yaşıyorsunuz. Sız ne dersiniz?
Sıkça Sorulan Sorular
Servis yönetimli sohbet geçmişi KVKK’ya uygun mu?
Açıkçası, doğrudan “uygun” demek pek mümkün değil. Veriler genellikle yurt dışındaki sunucularda dürüyor. Yanı kişisel veri içeren konuşmalar söz konusuysa, istemci yönetimli depolama ve Türkiye’deki Azure bölgesini kullanmak çok daha güvenli bir yol (buna dikkat edin). Bence bu konuyu mutlaka hukuk ekibinize sorun — sonradan baş ağrısı yaşamak istemezsiniz.
Compaction stratejisi ne demek, neden önemli?
Kısaca şöyle açıklayayım: uzun sohbet geçmişlerini bağlam penceresi limitine sığdırmak için kullanılan teknikler bunlar. Sliding window hani son N mesajı tutar, summarization eski mesajları özetler, truncation işe belirli bir noktadan öncesini kesip atar. Tecrübeme göre doğru stratejiyi seçmek hem maliyeti ciddi oranda düşürüyor hem de model performansını artırıyor — ikisi birden, yanı fena bir anlaşma değil.
Microsoft Agent Framework hangi sağlayıcıları destekliyor?
OpenAI (Chat Completions ve Responses API), Azure AI Foundry Agent Service, Anthropic Claude ve Azure AI Inference gibi büyük oyuncuları destekliyor. Aslında framework’ün güzel tarafı şu: her sağlayıcının farklı depolama modelini tek bir soyutlama altında topluyor, yanı sız çok fazla detayla uğraşmak zorunda kalmıyorsunuz.
Küçük bir proje için ne önerirsiniz?
Hızlıca bir şeyler çıkarmak istiyorsanız servis yönetimli depolamayla başlayın. Ama projenin büyüme ihtimali varsa — ki bence çoğu projede bu ihtimal göz ardı ediliyor — baştan istemci yönetimli altyapıyı kurmanızı tavsiye ederim. Bir bakıma, microsoft Agent Framework ile geçiş nispeten kolay, ancak sohbet verilerinin göçü her zaman biraz sıkıntılı oluyor. Sonradan “keşke baştan yapsaydım” dedirtiyor.
Token maliyetini nasıl düşürebilirim?
İlk adım compaction. Sliding window ile eski mesajları kırpın. İkinci adım tool-call collapse — yanı araç çağrısı detaylarını olabildiğince daraltın. Üçüncü adım işe aslında en basiti: gerçekten gerekmedikçe tüm geçmişi göndermeyin. Bu üç şeyi yaparsanız %40-60 arası token tasarrufu pekâlâ mümkün — mesela büyük ölçekli projelerde bu ciddi bir rakama karşılık geliyor.
Kaynaklar ve İleri Okuma
Chat History Storage Patterns in Microsoft Agent Framework — Microsoft DevBlogs
Azure AI Agent Service Resmî Dokümantasyonu
OpenAI Responses API Dokümantasyonu
Aşkın KILIÇYazar20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
AZ-305AZ-104AZ-500AZ-400DP-203AI-102İlgili Yazılar




İlginizi Çekebilir


Fatma B.
Biz de şu sıralar bir agent projesi geliştiriyoruz, sohbet geçmişi için Redis mi yoksa veritabanı mı tartışması hala çözümsüz. KVKK kısmına özellikle dikkat etmek gerekiyor, çoğu ekip bunu atlıyor ve sonradan başı büyük derde giriyor. Bu arada şu yazınız da güzeldi: Azure MCP Server .mcpb Paketi: Kurulum Artık Çocuk Oyuncağı — https://www.askinkilic.com.tr/azure-mcp-server-mcpb-paketi-kurulum-artik-cocuk-oyuncagi/
Deniz R.
KVKK kısmı çok kritik, şirketlerin büyük çoğunluğu bunu göz ardı edip sonradan başı derde giriyor. Siz yazıda hangi saklama yöntemini daha çok öneriyorsunuz, vektör DB mi yoksa klasik ilişkisel DB mi?
Barış U.
Sohbet geçmişini in-memory tutmakla başlamıştık ama scale olunca neler çektiğimizi bir bilseydiniz… KVKK kısmını özellikle merak ettim, agent’larda kullanıcı verisinin nerede tutulacağına dair net bir rehber bulmak gerçekten zor. Retention policy konusuna da değindiniz mi yazıda?
Yorumlar kapalı.











3 comments