OmniVec ile Vektör Borusunu Kurmak: Azure’da Sessiz Güç
Yapay zekâ projelerinde insanı en çok yoran şey çoğu zaman modelin kendisi olmuyor. Etrafındaki o görünmez boru hattı yoruyor. Hani kimsenin afişe etmeye pek hevesli olmadığı işler var ya, veri değişti mi, embedding yeniden üretildi mi, eski kayıtlar güncellendi mi, kuyruk şişti mi, hata alan kayıtlar nereye gitti mi… işte asıl bela orada çıkıyor. OmniVec de tam bu dağınık tarafı toparlamaya geliyor.
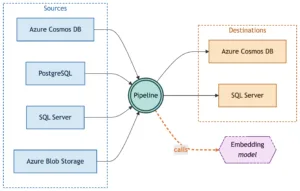
Açık konuşayım, ilk duyunca “embedding platformu” lafı biraz süslü geliyor. Ama sahada durum başka. 2024’ün son çeyreğinde bir finans müşterisinde benzer bir yapı kurarken, sadece change tracking için üç ayrı servis kullandığımızı fark ettik; bir yanda SQL tarafında CDC vardı, öbür tarafta embedding üreten worker’lar çalışıyordu, arkada da dead-letter kuyruğu dolup boşalıyordu… Sistem ayaktaydı ama bakım maliyeti can sıkıyordu. OmniVec’in anlattığı şey burada anlam kazanıyor: bu karmaşayı dört parçaya indiriyor — kaynak, model, hedef ve pipeline (ben de ilk duyduğumda şaşırmıştım)
Hmm, bunu nasıl anlatsamdı…
İnanın, Benim hoşuma giden taraf şu öldü: platform “al bunu, gerisini unut” demiyor. Tersine, senin Azure aboneliğine kuruluyor ve kontrolü sende bırakıyor. Bu bence kurumsal ekipler için baya önemli. Çünkü veri nerede dürüyor, hangi model çağrılıyor, hangi kaynak ne sıklıkla taranıyor; bunların hepsi görülebilmeli. En çok da KVKK ve iç denetim baskısı olan yapılarda bu detaylar hiç küçük değil.
Neden Böyle Bir Platforma İhtiyaç Var?
RAG kuran herkes aynı duvara tosluyor aslında. İlk demo hızlı çıkıyor ama canlıya geçince veri tazeliği dert olmaya başlıyor. Bir müşteri kaydı güncelleniyor, ürün açıklaması değişiyor ya da blob storage’a yeni dosya düşüyor; sız bunu yakalayamazsanız arama sonuçları eski kalıyor. Kullanıcı “bu sistem yanlış cevap veriyor” diyor ama sorun çoğu zaman modelde değil, veri senkronunda oluyor.
Hmm, bunu nasıl anlatsamdı…
Geçen yıl Eylül 2024’te bir e-ticaret firmasına danışmanlık verirken bunu birebir yaşadık. Arama katmanı gayet iyi görünüyordu ama (söylemesi ayıp) stok bilgisi ile katalog açıklamaları farklı hızlarda güncellendiği için öneriler saçmalamaya başlamıştı (buna dikkat edin). Sonra işin aslı çıktı: embedding pipeline’ın backfill mantığı zayıftı. OmniVec’in otomatik backfill ve change tracking yaklaşımı burada ciddi rahatlık sağlıyor.
Bir de şu var: çoğu ekip kendi mini orkestratörünü yazıyor ve sonra önü unutuyor. İlk ay güzel gidiyor, üçüncü ayda retry sayıları artıyor, altıncı ayda biri izinli olduğu için sistemin nasıl çalıştığını kimse bilmiyor. Kağıt üstünde basit görünen bu işler pratikte operasyon yüküne dönüşüyor… işte OmniVec o yükü azaltmayı hedefliyor.
Dört Parça ile Düşünmek
OmniVec’in modeli aslında sade: source, model, destination ve pipeline. Bu kadar. Ama sadelik aldatmasın; doğru kurgulanmazsa küçük bir eksik bile zinciri kırabiliyor. Source tarafında değişimi nasıl izleyeceğiniz önemli; Cosmos DB’de change feed başka şey söylüyor, PostgreSQL’de CDC başka ritimde çalışıyor.
Model tarafında işe seçim doğrudan maliyete dokunuyor. Azure OpenAI gibi yönetilen bir model kullanırsanız operasyon kolaylaşıyor; kendi GPU modelinizi koşturursanız esneklik artıyor. Bakım yükü de artar. Startup iseniz genelde yönetilen servis daha mantıklı olur. Enterprise tarafta işe bazen veri egemenliği yüzünden self-hosted seçenek ağır basabiliyor.
OmniVec’in dayanıklı yanı “embedding üretmek” değil; o üretimi sürekli ve düzenli tutmakta yatıyor.
Mimariyi Sahada Nasıl Okurum?
OmniVec AKS üzerinde çalışıyor; API katmanı FastAPI ile geliyor, ingestion bileşeni kaynakları izliyor, worker havuzu da işi çekip çeviriyor. Burada AKS seçimi tesadüf değil tabi — yatay ölçekleme ihtiyacı olan bu tip işlerde container tabanlı mimarı baya uygun oluyor (bizzat test ettim) Daha fazla bilgi için
Bununla birlikte her şey güllük gülistanlık değil! AKS + Cosmos DB + ACR üçlüsü küçük ekipler için biraz ağır gelebilir. Yanı evet güzel çözüm ama “ben tek kişiyim ve hafta sonu POC çıkaracağım” diyorsanız fazlasıyla kapsamlı kalabilir. Küçük ekiplerde daha hafif bir queue + function yaklaşımı hâlâ iş görüyor.
| Konu | Startup | Kurumsal Yapı |
|---|---|---|
| Maliyet hassasiyeti | Daha yüksek öncelik | Dengeli / kontrollü büyüme |
| Operasyon yükü | Mümkün olduğunca düşük olmalı | SLA ve denetim nedeniyle kabul edilebilir |
| Model seçimi | Ağır basan çoğunlukla managed servis | Bazen self-hosted GPU gerekir |
| Veri yönetişimi | Kritik ama basit tutulur | Daha sıkı politika ister |
Türkiye’de Bunu Nerede Görürüz?
Bunu Türkiye’deki şirketler açısından düşününce tablo biraz değişiyor.
Maliyet baskısı daha sert hissediliyor.
Birçok kurum PoC yapmayı seviyor ama canlıya geçince “bu aylık fatura neden böyle geldi?” sorusu hemen masaya düşüyor.
Bu yüzden OmniVec gibi çözümler sadece teknik değil finansal karar da oluyor.
Geçen mart ayında İstanbul Ataşehir’de bir perakende grubuyla yaptığımız görüşmede tam buna takıldık.
Veri kaynağı SQL Server’dı ve içerik güncellemeleri yoğun geliyordu.
Ekibin beklentisi basitti:
“Bir kere bağlayalım yeter.”
Ama iş öyle yürümüyor.
Embedding yeniden üretimi için batching stratejisi lazım,
retry politikası lazım,
bir de hangi kayıtların geri kaldığını görebileceğiniz düzgün gözlemleme lazım.
Bakın şimdi…
Eğer elinizde zaten güçlü bir platform ekibi varsa OmniVec tarzı çözüm sizi hızlandırır.
Ama küçük ya da orta ölçekli firmalarda önce ihtiyaç analizi yapmak gerekiyor:
gerçekten sürekli taze vektör mü lazım,
yoksa günlük batch yeterli mi?
Bu ayrım yapılmadan kurulan sistemler sonra gereksiz pahalı hâle geliyor.
Bir de maliyet tarafını TL bazında düşününce insanın gözü açılıyor.
Azure OpenAI çağrıları,
AKS node’ları,
Cosmos DB throughput’u…
Hepsi birleşince bütçe sessizce büyüyor.
O yüzden ben genelde şunu öneriyorum:
önce küçük başlayın,
sonra ölçün,
ondan sonra genişletin.
İlk günden büyük mimarı çizmek çoğu zaman ego tatmini oluyor… pratik fayda değil.
Ha bu arada;
2019’da Ankara’daki bir hosting migrasyon projesinde benzer şekilde aşırı mühendislik yapıp işi gereksiz karmaşıklaştırmıştık.
Sonra geri dönüp sadeleştirdik ve performans düzelmişti.
Demek istediğim şu:
iyi mimarı her zaman büyük mimarı değildir.
Dikkat Edilmesi Gereken Noktalar
OmniVec’in hoş taraflarından biri açık kaynak olması; yanı inceleyebilir, uyarlayabilir ve gerektiğinde katkı verebilirsiniz.
Ama açık kaynak demek otomatik olarak düşük risk demek değil!
Tam tersine bazı parçaları sizin sahiplenmeniz gerekiyor.
Mesela embedding modeli seçerken kalite-maliyet dengesi kritik olur.
Daha ucuz model bazen işinizi görür ama semantik doğruluk beklediğiniz seviyede olmayabilir.
Bir müşteri destek botunda kısa cevaplar için idare eder;
hukukî doküman aramasında işe hayal kırıklığı yaratabilir.
Benim ilk denememde aldığım sorunlardan biri de erişim izinleriydi;
AKS’den Cosmos DB’ye bağlanırken managed identity kurgusunda ufak bir RBAC hatası yüzünden ingest akışı başlamadı.
Hata mesajı kaba saba değildi ama ipucu vardı:
yetki yoktu!
Çözüm şu öldü:
kimlik atamasını düzelttik ve gerekli rol atamalarını verdik,
sonra pipeline ayağa kalktı.
Pratikte ilk adım olarak şunları öneririm:
- Önce tek bir veri kaynağıyla başlayın.
- Sadece bir embedding modeli seçin.
- Kuyruğu ve retry politikasını gözlemleyin.
- Sonra ikinci kaynağı ekleyin.
- Metrikleri takip etmeden ölçeklemeyin.
Kimin İçin Uygun?
İlginç olan şu ki, Eğer kurumsal ölçekte AI uygulaması geliştiriyorsanız OmniVec baya anlamlı olabilir.
Hele bir de veri kaynaklarınız sık değişiyorsa çok işe yarar.
Küçük startup’larda işe önce hafif çözümlerle başlamak daha mantıklı olabilir;
mesela Azure Functions + Queue + basit batch job kombinasyonu çoğu erken aşama üründe yeterli.
Yanı illâ büyük platform kuracaksınız diye bir kaide yok.
Bence en doğru kullanım alanı şu:
birden fazla kaynaktan gelen veriyi sürekli vektör dünyasında güncel tutmanız gerekiyorsa…
orada OmniVec gerçekten parlıyor.
Sıkça Sorulan Sorular
OmniVec ne iş yapıyor?
Bakın, Aslında çok net bir görevi var: veri kaynaklarını izliyor, değişen kayıtlar için embedding üretiyor. Bunları hedef vektör deposuna yazıyor. Yanı hani manuel pipeline kurma derdinden kurtuluyorsunuz.
Sadece Azure’da mı çalışır?
Evet, temel olarak Azure subscription içine kurulacak şekilde tasarlanmış. Cosmos DB, PostgreSQL, SQL Server ve Blob Storage desteği öne çıkıyor — bence bu liste çoğu proje için yeterli.
Küçük ekipler de kullanabilir mi?
Kullanabilir, ama açıkçası AKS gibi bileşenler nedeniyle başlangıç maliyeti biraz ağır gelebilir. Tecrübeme göre ihtiyacınız basitse önce daha hafif alternatiflerle başlamak daha mantıklı.
Peki en büyük artısı ne?
Tutarlı sync sorunuyla uğraşmıyorsunuz — bu gerçekten büyük bir rahatlama! Embedding pipeline’ını sıfırdan yazmak yerine her şeyi yönetilebilir parçalara ayırıyorsunuz ve operasyon yükünüz ciddi ölçüde azalıyor.
Kaynaklar ve İleri Okuma
Orijinal duyuru yazısı — Introducing OmniVec: An Open-Source Embedding Platform for AI Apps on Azure
Şöyle ki, Azure Cosmos DB Change Feed resmî dokümantasyonu
Bunu yaşayan biri olarak söyleyeyim, Azure Architecture Center — güvenilir uygulama desenleri (ciddiyim)
Azure OpenAI Servisi resmî dokümantasyonu

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.











3 comments