
Bir fraud senaryosu düşünün. Kart geliyor, cihaz geliyor, konum geliyor, geçmiş davranış geliyor… ve sizden tek bir şey bekleniyor: “Bu işlem geçsin mi, geçmesin mi?” İşin aslı şu ki, bu karar çoğu zaman sadece bir SELECT sorgusuyla çıkmıyor. Ben yıllardır Azure — ki bu tartışılır — tarafında, özellikle kurumsal yapılarda bunu çok gördüm; veriyi parça parça başka yerlere taşıyınca iş büyüyor, gecikme artıyor, güvenlik ekibi ayrı konuşuyor, veri ekibi ayrı konuşuyor (kendi tecrübem). sonra herkes birbirine bakıyor.
Araya gireyim: Aditya’nın yazısındaki ana fikir bana çok tanıdık geldi: vektör araması da analitik de illâ ayrı sistemlerde yaşamak zorunda değil. Hatta açık konuşayım, bazı ekipler bunu gereksiz yere fazla dağıtıyor. 2024’te bir finans müşterisinde benzer bir mimarı tartışmasında tam bunu yaşamıştık; fraud ekibi “ben similarity search istiyorum” dedi, BI tarafı “biz de anlık baseline istiyoruz” dedi. İlk refleks yine klasik oldu: bir vektör veritabanı kuralım, üstüne data warehouse’a akıtacak ETL basalım. Sonra durduk ve şunu sorduk: Bunu tek yerde daha temiz yapabiliyor muyuz?
Neden Aynı Motor Meselesi Bu Kadar Önemli?
Bilmem anlatabiliyor muyum, Polyglot yaklaşımı ilk bakışta cazip görünüyor. Her iş için en uygun aracı seçiyorsunuz gibi duruyor; kağıt üstünde süper. Ama pratikte biraz yorucu oluyor. Kimlik doğrulama ayrı, ağ katmanı ayrı, izleme ayrı… en sonunda küçük görünen bir fraud kontrolü bile üç servisin kapısını çalıyor.
Ben bunu 2023’te İstanbul’da bir e-ticaret platformunda net gördüm. Takım önce ilişkiseli tutmuştu ama device fingerprint için JSON store açtı, ilişkiler için graph denedi, benzer işlem bulmak için de ayrı bir vector service düşündü. Üç ay sonra operasyon tarafı “bir işlem neden gecikiyor?” sorusuna cevap veremez hâle geldi. Çünkü problem kodda değilmiş gibi görünüyordu; problem dağılımın kendisindeydi.
Hmm, bunu nasıl anlatsamdı…
Aynı motor yaklaşımının güzel yani şu: transaction akışı tek plan içinde kalıyor. Bir yandan transactional veriyle uğraşıyorsunuz, öbür yandan benzerlik arıyorsunuz ya da milyonlarca satır üzerinden baseline hesaplıyorsunuz… ama veri başka kıtaya kaçmıyor. E tabii bunun bedeli de var; her şeyi tek yere koyunca motorun kabiliyeti gerçekten güçlü olmalı.
Vektör araması neden sıradan filtrelerden farklı?
Şunu söyleyeyim, Mesela “amount between 8000 and 10000” yazmak kolaydır ama hayat o kadar düzgün değil. Fraud işlemlerinin çoğu net kutulara sığmaz. Benzer cihaz parmak izi vardır ama miktar değişmiştir; şehir değişmiştir ama saat penceresi aynıdır; kart yeni açılmıştır ama davranış paterni eski dolandırıcılığa çok benzer (şaşırtıcı ama gerçek)
Bak şimdi, Vektör burada devreye giriyor. Veriyi sayılara döküyorsunuz ve geometrik yakınlıkla anlam yakalıyorsunuz. Yani kaba anlatımla iki işlem birbirine ne kadar yakınsa model önü o kadar benzer görüyor. Bu bana bazen insan ilişkisi gibi geliyor; kelime kelime aynı olmayabilirler ama his olarak çok benzeyebilirler.
Açık konuşayım: vektör arama sihir değil. Kötü hazırlanmış feature set ile mucize beklemek boşuna olur.
Analitik Tarafı Neden ETL’siz Düşünmek Gerekiyor?
Neyse, bilmem anlatabiliyor muyum, Ha bu arada ikinci büyük mesele de analitik tarafı. Anti-fraud ekipleri çoğu zaman “anlık baseline” ister ama teknik tarafta ilk tepki genelde şu olur: tamam bunu data warehouse’a basalım, orada hesaplarız! Güzel fikir gibi görünür… ta ki veri tazeliği bozulana kadar.
Şimdi gelelim işin can alıcı noktasına. Entra External ID’de Sosyal Giriş: Native Auth GA Oldu yazımızda bu konuya da değinmiştik.
Bende en çok iz bırakan örneklerden biri 2022’de Ankara’da çalıştığım bir telekom projesiydi. Orada müşteri davranışlarını saatlik izliyorduk. Ekip güncel trendi birkaç dakika geriden görmek istemiyordu; çünkü kampanya suistimali hızlı gelişiyordu (işte tam o can sıkıcı an). ETL hattı kurulunca raporlar güzel görünüyordu ama karar anında veri artık eskiydi. Daha fazla bilgi için OpenAI Neden Bir Medya Şirketi Satın Aldı: TBPN yazımıza bakabilirsiniz.
Mesele şu: analitik sadece rapor almak değil, karar vermek için de lazım olabilir. En çok da risk skoru üretirken ortalama işlem tutarı nedir, son 30 dakikadaki sapma ne durumda, bu kullanıcı segmenti bugün normalden ne kadar uzaklaştı gibi soruların cevabı canlı gelmeli.
| Yaklaşım | Artısı | Eksiği | Kime uygun? |
|---|---|---|---|
| Ayrı Vektör DB + ETL Warehouse | İş yüklerini ayırır | Senkron kaybı ve operasyon yükü yaratır | Karmaşık ama olgun platformlar |
| Tek Motor İçinde SQL + Analitik + Vektör | Daha az hareketli parça | Kapasite planlaması dikkat ister | Kurum içi sadeleşme isteyen ekipler |
| Sadece klasik RDBMS + batch raporlama | Anlamak kolaydır | Zamanlama yüzünden gecikir | Küçük hacimli sistemler |
Küçük Startup ile Enterprise Aynı Şeyi Yapmaz!
Küçük bir startup iseniz dürüst olayım; bazen fazla mimarı kurmaya hiç gerek yoktur. Ürün-pazar uyumu peşindesinizdir ve hızlı deneme yapmak istersiniz. Hani ne farkı var diyorsunuz, değil mi? Böyle yerlerde tek motor yaklaşımı size hız kazandırır çünkü az kişiyle daha az servis yönetirsiniz.
Enterprise tarafta işe resim değişiyor tabii. Orada mesele yalnızca performans değil; denetim izi var mı, yetkilendirme nasıl ayrılmış, veri bölgesi nerede tutuluyor (EU mu TR mi), maliyet nasıl ölçülüyor… hepsi masaya geliyor. AZ-305’e hazırlanırken not aldığım şeylerden biri buydu zaten: doğru mimarı sadece teknolojik değil, organizasyonel karardır da.
Bakın, burayı atlarsanız yazının kalanı anlamsız kalır. Daha fazla bilgi için GitHub’da Güvenlik Sekmesi Değişti: Kalite de Eklendi yazımıza bakabilirsiniz.
Bazı kurumlarda polyglot neredeyse tamamen yanlış demiyorum ha — yanlış anlaşılmasın — fakat her yeni ihtiyaçta yeni platform açmak bana artık eskisi kadar mantıklı gelmiyor.
Bir dakika,
şunu da ekleyeyim:
tek motor her derde deva değildir.
Mesela aşırı özel gereksinimlerde bağımsız servis hâlâ daha doğru olabilir.
Ama sırf alışkanlıktan dolayı ETL kuruyorsanız orada durup düşünmek lazım.
Neyse uzatmayalım…
Sahada gördüğüm üç pratik sonuç
- Daha az gecikme: Veri taşınmadığı için karar süresi düşüyor. (bu kritik)
- Daha az kırılganlık: Pipeline sayısı azalınca hata noktaları da azalıyor. — ciddi fark yaratıyor
- Daha iyi güvenlik hikâyesi: Yetki modeli tek yerde toparlanabiliyor.
Peki Performans? Burada İş Ciddi Oluyor!
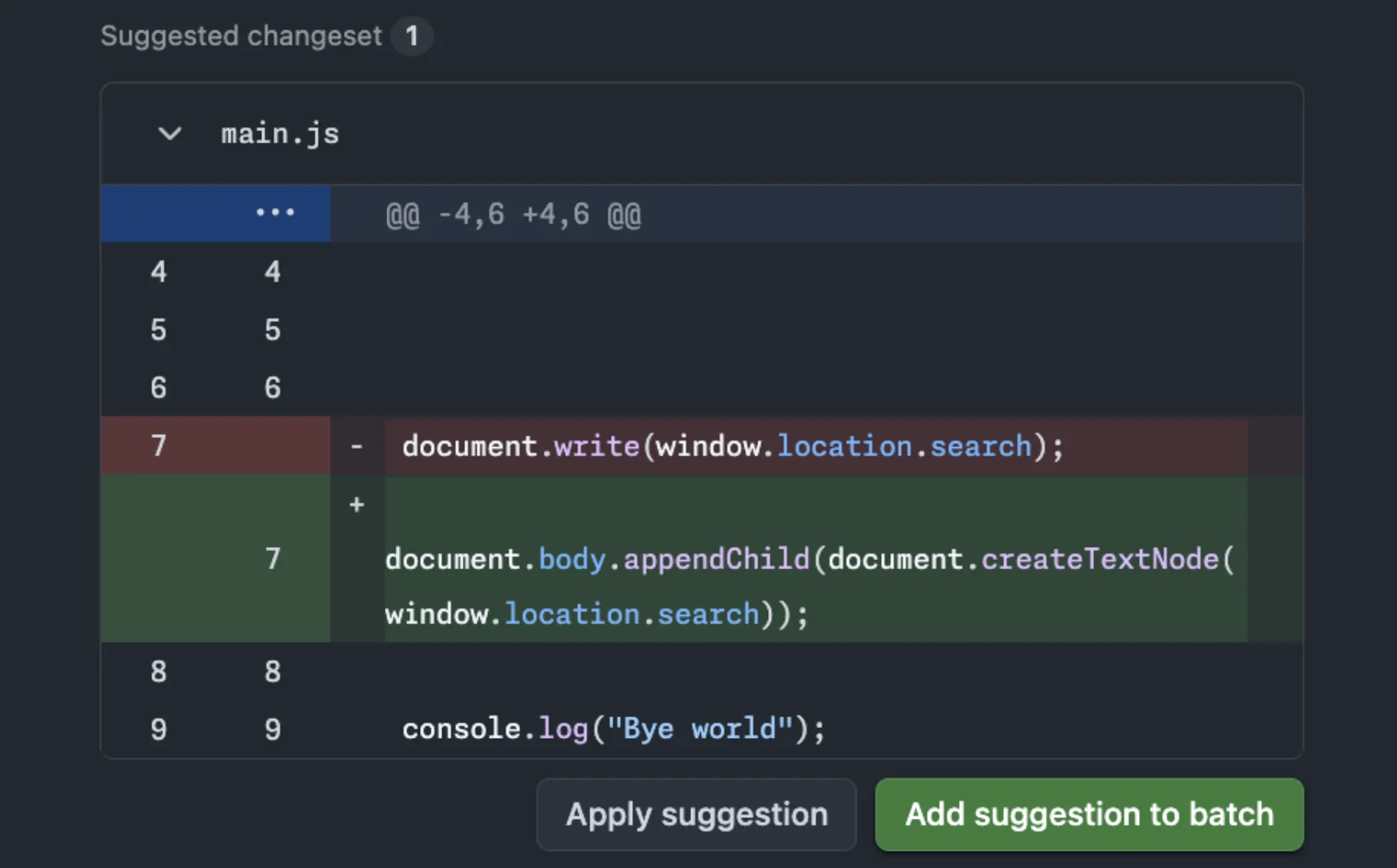
Ne yalan söyleyeyim, Bazen insanlar “tamam da bütün bunlar güzel de performans?” diye soruyor (ciddiyim). Haklılar da! Çünkü vektör araması deyince herkesin kafasında milyon satır arasında brute-force dolaşan ağır bir yapı canlanıyor fena halde yorucu yani… Bu konuyla ilgili Azure Boards’ta Markdown Düzenleyici Neden Daha Sakin Oldu? yazımıza da göz atmanızı tavsiye ederim.
Ama modern engine’lerde olay biraz farklı ilerliyor.: indeksleme teknikleriyle yaklaşık komşuluk araması yapılıyor,. yani pek çok tabloyu didik didik etmek yerine aday kümesi daraltılıyor., Bu detay önemli çünkü aksi hâlde maliyet patlıyor.. Benim geçen yıl EMEA bölgesindeki bir üretim müşterisinde gördüğüm senaryoda bu konu kritik olmuştu.; test ortamında iyi çalışan şey prod ortamda tokat gibi geri dönebiliyor!
-- Basit düşünce örneği
SELECT TOP (10)
t.TransactionId,
t.Amount,
VECTOR_DISTANCE(t.TransactionEmbeddingVector,
@IncomingTransactionVector) AS SimilarityScore
FROM dbo.Transactions AS t
ORDER BY SimilarityScore ASC;Şöyle söyleyeyim, Böyle bir sorgu kulağa basit geliyor ama perde arkasında indeksleme stratejisi yoksa iş uzar gider.
Aslında — dur bir saniye — burada asıl mesele sorgunun kısa olması değil;
motorun o sorguyu akıllıca çözebilmesi.
Bu yüzden Azure SQL tarafındaki gelişmeleri okurken hep aynı yere bakıyorum:
“Gerçek kullanımda bu ne kadar stabil?” Eğer cevap sisliyse biraz temkinli olmak lazım.
Beklediğim kadar cilalı olmayan özellikleri hemen överek anlatmayı sevmem açıkçası. Codex’te Fiyat Meselesi Değişti: Takımlar İçin Ne Anlama Geliyor? yazımızda bu konuya da değinmiştik.
Bana Göre Asıl Kazanç Nerede?
Eh, Bence en büyük kazanç mimarı sadelikte yatıyor.
Teknoloji sayısını azaltınca ekiplerin nefesi açılıyor.
Gözlemleme kolaylaşıyor,
güvenlik politikaları sadeleşiyor,
hatta FinOps tarafında bile daha net tablo çıkıyor.
2025 başında Logosoft’ta yürüttüğümüz bir Azure danışmanlığında tam bunu konuştuk;
“her şeyin kendi servisi olsun” fikri yerine
“işe yarayan parçaları aynı zeminde tutalım” dedik ve karmaşa belirgin biçimde azaldı.
E tabii her şey pembe değil.
Bazı özellikler hâlâ ham hissediyor;
özellikle dokümantasyon ile gerçek kullanım arasındaki mesafe bazen insanın canını sıkabiliyor.
Ama dürüst olayım,
bu alan baya hızlı olgunlaşıyor.
Bakın, en çok da Microsoft’un multimodal veriye yaklaşımı,
sanki yıllardır dağıttığımız işleri tekrar merkeze çekmeye çalışıyor gibi.
Nerede kullanırım?
- Liveness fraud kontrolü: Canlı işlemde hem benzerlik hem baseline bakarsınız. (bence en önemlisi)
- Müşteri segmentasyonu: Davranış kümeleri ile anomaliyi birlikte takip edersiniz.
- Sahtecilik sonrası inceleme: Operasyon ekibi geçmiş örneklerle eşleştirme yapar.
Sıkça Sorulan Sorular
Azure SQL içinde vektör arama ne işe yarar?
Aynı veya benzer kayıtları semantik olarak bulmanızı sağlar. Mesela fraud detection,, öneri sistemi ve doküman eşleştirme gibi işlerde işe yarar.. Klasik filtrelerin kaçırdığı desenleri yakalamak için kullanılır..
Ayrı vector database kullanmak mı daha iyi?
Aynı veya benzer kayıtları semantik olarak bulmanızı sağlar. Mesela fraud detection,, öneri sistemi ve doküman eşleştirme gibi işlerde işe yarar.. Klasik filtrelerin kaçırdığı desenleri yakalamak için kullanılır..
Bazen evet,, özellikle çok özel iyileştirme gerekiyorsa.. Ama kurumsal tarafta ekstra entegrasyon,, yetkilendirme ve gecikme maliyeti getirir… Tek motorda çözmek çoğu zaman operasyonu rahatlatır..
Anlık analitik için ETL şart mı?
Tartışmalı konu burası.. Eğer birkaç dakika geriden gelmek sorun değilse batch yeterli.. Ama karar anında güncel sayı gerekiyorsa ETL zinciri genelde fazla yavaş kalır..
Küçük ekipler bu yaklaşımı kullanmalı mı?
Evet,, özellikle platform sayısını azaltmak istiyorlarsa mantıklı olabilir.. Küçük ekiplerde bakım yükü büyük fark yaratır. Daha az servis = daha az gece alarmı demek bazen doğrudan huzur demek!
Kaynaklar ve İleri Okuma
Evet,, özellikle platform sayısını azaltmak istiyorlarsa mantıklı olabilir.. Küçük ekiplerde bakım yükü büyük fark yaratır. Daha az servis = daha az gece alarmı demek bazen doğrudan huzur demek!
Kaynaklar ve İleri Okuma
Azure SQL Resmî Dokümantasyonu
Azure SQL Vector Search Genel Bakış — Microsoft Learn
Microsoft Azure Blog — Azure SQL Yazıları
“Veriyi gerçekten taşımam gerekiyor mu?”
Çoğu zaman cevap hayır oluyor…
ve işte tam orada mimarı sadeleşmeye başlıyor.`
Bunun küçük versiyonunu geçen ay Bursa’daki bir üretim firmasına anlattığımda,
ekip önce şüpheyle baktı ama sonra tabloyu görünce ikna oldu.;
bazen en iyi optimizasyon yeni araç eklemek değil,. eldeki araçları doğru kullanmaktır.
İçeriği paylaş:
İlgili Yazılar




📬 Bu yazıyı faydalı buldunuz mu?
Azure, DevOps ve bulut teknolojileri hakkında güncel içerikler için beni takip edin!



Mehmet K.
Fraud tespitinde her milisaniye önemli olduğu düşünülünce ETL’nin yarattığı gecikme gerçekten kabul edilemez bir hale geliyor. Biz de benzer bir senaryoda veriyi taşıma yerine yerinde işleme geçince ne kadar fark yarattığını gördük. Bu arada şu yazınız da güzeldi: Codex’te Fiyat Meselesi Değişti: Takımlar İçin Ne Anlama Geliyor? https://www.askinkilic.com.tr/codexte-fiyat-meselesi-degisti-takimlar-icin-ne-anlama-geliy/
Burak S.
Fraud detection tarafında ETL gecikmesinin ne kadar can sıkıcı olduğunu yaşadık, pipeline beklerken karar penceresi kapanıyor. Vektör aramayı aynı katmanda tutmak mantıklı ama Azure SQL’in bu yoğun analitik yükte nasıl davrandığını merak ediyorum, gerçek dünya rakamları var mı elinizde? Bu arada şu yazınız da güzeldi: Codex’te Fiyat Meselesi Değişti: Takımlar İçin Ne Anlama Geliyor? — https://www.askinkilic.com.tr/codexte-fiyat-meselesi-degisti-takimlar-icin-ne-anlama-








2 comments