Azure Cosmos DB’de Vektörler Kendini Güncelliyor: AI Uygulamalarda Yeni Dönem

Bir şeyi kovalamayi bırakınca is kolaylaşıyor
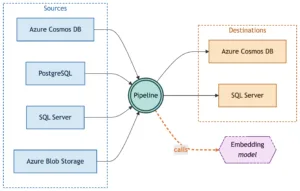
Aslında, AI uygulamalarında en yorucu kısım çoğu zaman model seçmek değil, veriyi diri tutmak oluyor. Yanı arama tarafı için embedding üretiyorsun, sonra veri değişiyor, embedding eski kalıyor, bir boru kuruyorsun, o boru bir yerde tıkanıyor… işte asıl dert orada başlıyor. Azure Cosmos DB’nın Integrated Embeddings on izlemesi tam da bu yükü hafifletmeye oynuyor.
Açık konuşayım, ben bu senaryoyu yıllardır farklı şekillerde gördüm. 2023’un sonlarında İstanbul’daki (söylemesi ayıp) bir e-ticaret müşterinde ürün açıklamaları için ayrı bir vektör işleme hattı kurmuştuk; her gün binlerce kayıt değişiyordu ve küçük görünen gecikmeler bile arama kalitesini bozuyordu. Sonra aynı sorunu 2024’te Ankara’da bir SaaS ekibinde yine yaşadık: veri başka yerde, embedding başka yerde, senkron bambaşka yerde… hani insan “bu kadar mi zor?” diyor.
Peki neden?
Bak şimdi, Bu yeni yaklaşımın güzel yanı su: item yazilirken ya da güncellenirken embedding de yanında doğuyor (ciddiyim). Yanı “önce veriyi kaydet, sonra kuyruk bir düşüneyim… çalışsın, sonra model cagrisin” gibi katmanlar azalıyor. Kağıt üstünde basit dürüyor ama pratikte bayağı iş görüyor.
Vallahi, Tabi her parlak şey gibi bunun da sınırı var. Public Preview olduğu için bazı yerlerde hâlâ ham hissi veriyor; özellikle auth tarafında yalnızca Entra desteği olması bazı ekiplerde ilk gün biraz sürpriz yaratabilir. Ama genel yön doğru. Bence iyi yönde atılmış bir adım (evet, doğru duydunuz)
Neyi çözüyor, neyi cozmunuyor?
Klasik mimaride embedding üretimi ayrı bir servis gibi düşünülür: değişiklikleri yakalarsin, modele gonderirsin, sonucu geri yazarsın ve üstüne retry-throttle-monitoring ucclusunu orersin. Küçük ekip için bu idare eder; iki kişiyle cikarsan olur. Ama enterprise tarafında işler büyüyünce bu yapı sessizce şişer. Bir noktadan sonra kim neyi üretiyor, hangi sürüm hangi dokümanda kullanılıyor… takip etmek can sıkıyor.
Bence, Integrated Embeddings, bunu Cosmos DB seviyesine indiriyor. Container policy içinde tanımlıyorsun; kaynak alanları söylüyorsun; hangi modeli kullanacağını belirliyorsun; çıktı nereye yazilacak diyorsun ve gerisini platform hallediyor. Benim gözüme göre asıl kıymet burada: operasyonel yük azalıyor.
Doğrusu, Bir de şu var: veri ile vektör arasında kopukluk azalınca RAG sonuçları daha güvenilir oluyor. Çünkü sistem eski metni değil, güncel kaydı baz alıyor. Özellikle ürün kataloğu, doküman yönetimi veya müşteri destek içerikleri gibi alanlarda bu çok kritik.
Mimarı nasıl çalışıyor?
Sistem aslında çok karmaşık görünmüyor ama detay önemli (bizzat test ettim). Container vector policy içine yeni bir embeddingSource bloğu ekliyorsun. Bu blok üç şeyi anlatıyor: ne embed edilecek, hangi model kullanılacak ve nasıl kimlik dogrulanacak.
sourcetPaths içine tek alan da koyabilirsin birkaç alan da. Birden fazla alan verdiğinde bunlar tek giriş olarak birleşiyor; yanı başlık + açıklama + kategori gibi parçalar aynı embeddingle temsil edilebiliyor. Bu pratikte işe yarıyor çünkü arama bağlamı daha zengin oluyor.
Kullandığım örneklerden biri şöyleydi: teknik dokümanlarda sadece özet alanı embed etmek yetmediği için baslikla birlikte ilk paragrafi da aldık (evet biraz uzun öldü), sonuçlar bariz şekilde toparlandı. 2019’da kendi lab ortamımda buna benzer denemelerde hep aynı sonuca gelmiştim: bağlam azsa sonuç zayıf kalıyor (kendi tecrübem)
{
"vectorEmbeddings": [
{
"path": "/embedding",
"dataType": "float32",
"dimensions": 1536,
"distanceFunction": "cosine",
"embeddingSource": {
"sourcePaths": ["/text"],
"deploymentName": "text-embedding-3-small",
"modelName": "text-embedding-3-small",
"endpoint": "https://<foundry-resource-name>.openai.azure.com/",
"authType": "Entra"
}
}
]
}Neden bu yapı mantıklı?
Lafı gevelemeden söyleyeyim: çünkü veri akışını sadeleştiriyor.
Ayrı bir worker servisi yoksa bakım yüzeyi de küçülüyor.
Büyük kurumda küçük görünen her servis zamanla maliyet çıkarır; loglama ayrı derttir, ölçekleme ayrı derttir, hata yönetimi ayrı derttir…
Peki neden?
Küçük startup tarafında işe mesele başka: ekip. Azsa herkes hem backend hem AI pipeline’a bakmak zorunda kalır. Işte böyle durumlarda embedded senkronizasyonu platforma bırakmak baya rahatlatıcı olabilir.
Bunu Türkiye’deki şirketler açısından düşününce…
Bunu yaşayan biri olarak söyleyeyim, Bence Türkiye’de benimsenme hızını en çok etkileyen şey teknik değil; bütçe ve operasyon kültürü oluyor.
Kurumsal müşterilerimde gördüğüm kadarıyla ekipler önce “bu gerçekten gerekli mi?” diye soruyor.
Haklılar da… Çünkü her yeni yapay zekâ özelliği otomatik olarak değer üretmiyor.
Ankara’daki bir finans kurulushunda geçen sene yaptığımız PoC’de en büyük sorun model değildi mesela; veri guncelligiydi.
Dokümanlar sık değişiyordu. Arama katmanı haftada bir yenileniyordu — saçma görünüyor ama gerçek hayatta böyle şeyler olabiliyor.
Cosmos DB’nın verinin yanına embedding tasiması burada ciddi avantaj sağlıyor.
E tabi maliyet boyutunu da unutmayalım.
TL bazında düşündüğünüzde sadece model cagrisı değil, o modeli cagiran ara servislerin Azure faturası da büyüyor.
App Service mi kullanacaksınız? Function mu? Queue mu? Monitör mu? Hepsi ufak ufak toplanip can sıkabiliyor…
| Senaryo | Klasik yol | Tavsiye edilen yaklaşım |
|---|---|---|
| Küçük startup | Ayrı worker + queue + retry mekanizması | Daha hızlı çıkış için Integrated Embeddings dene |
| Büyük enterprise | Ayrıntılı kontrol isteyen özel pipeline | Pilot ile başla, uyumluluk ve maliyeti ölçerek ilerle |
| Düşük bütçe / PoC | Aynı anda birkaç servis işletmek zorunda kalırsın | Cosmos DB içinde sade akış daha mantıklı olabilir |
| Sık veri değişimi olan kataloglar | Senkron kaçırma riski yüksek olur | Anlık embedding üretimi ciddi rahatlatır |
Peki nerede dikkatli olmak lazım?
Burası önemli: preview özelliklerini görünce hemen prod’a kosmayın.
Ben bunu 2024’te İzmir’deki bir perakende projesinde yaşadım; ekip heyecanlandı ama test ortamındaki başarı prod beklentisini birebir karşılamadı.
Neden? Çünkü gerçek trafik altında throttling davranışı. Model yanıt süreleri başka türlü hissediliyor.
- Erişim modeli şu an sınırlıysa bunu tasarımınıza açıkça yazın. — bunu es geçmeyin
- Maliyet hesabını sadece storage üzerinden yapmayın; model çağrısı kısmını da koyun.
- Düşük gecikme istiyorsanız document boyutlarını gereksiz şişirmeyin. (bu kritik)
- Pilot ortamda change rate yüksek birkaç koleksiyonla test yapın.
- Error handling’i göz ardı etmeyin; preview olsa bile fallback planınız olsun.
Benim görüşüm şu: Integrated Embeddings tam üretim silahı olmadan önce bile pilot projelerde çok değerli olabilir ama körlemesine güvenilirse hayal kırıklığı yaratabilir.
Kendi pratiğimde nerede işe yarar?
İtiraf edeyim, Aslında — dur bir saniye, önce şunu söyleyeyim : ben bu tarz özellikleri genelde “operasyonel borcu azaltan araç” olarak görüyorum. Yanı sadece AI yeteneği vermiyor ; aynı zamanda bakım yükünü aşağı çekiyor. Bu fark, özellikle orta ölçekten yukarı çıkan yapılarda hissediliyor (bu beni çok şaşırttı)
Evet, doğru duydunuz.
Mesela Azure Cosmos DB üzerinde çalışan bilgi tabanı, ürün kataloğu ya da müşteri etkileşim geçmişi olan sistemlerde, embeddingle verinin beraber yaşaması baya temiz çözüm. Bir arkadaşım geçen ay Nisan 2026’da Berlin’deki fintech ekibine bunu anlattığında ilk tepki “güzel ama pahalı mı?” olmuştu ; dürüst cevap evet, bazen olacak. Ama ayrı pipeline kurmanın gizli maliyetini sayınca tablo değişebiliyor (inanın bana)
Hani, AZ -305 sınavına hazırlanırken de benzer kafa yapısını sürekli tekrar ederim : mimariyi yalnızca çalışır hâlde değil, sürdürülebilir hâlde tasarlamak gerekir. Burada da olay aynı. İşleyen sistem kurmak kolay ; önü düzgün işletmek esas marifet. Hatta bazen iyi mimarı, hiç konuşulmayan mimaridir — çünkü problem çıkarmıyordur !
Bütçesi kısıtlı olan ne yapsın?
Eğer bütçe dar işe önce PoC ile başlayın. Tek container, tek embedding modeli, sınırlı veri kümesi… yeterince net sinyal verir. Üretime geçmeden önce performans ölçün ; latency, write amplification ve retrieval kalitesine bakın.
Azıcık sabırlı olun yanı ; yoksa yanlış karar verme ihtimali artar.
Bunu biraz açayım.
Büyük kurumdaysanız işe governance tarafını erkenden düşünün : Entra erişimleri, rol ayrımları, izleme panoları ve veri sınıflandırması işin içine girsin.
Aksi hâlde teknik olarak harika görünen şey organizasyonel kaosa dönebilir.
Buyurun.
Tatlı vaat mi, sağlam kazanım mı ? İkisi de biraz var
Bu özelliğin en güçlü tarafı bence “senkronizasyonu görünmez hâle getirmesi”.
Yazılım dünyasında görünmeyen işler genelde ya çok iyidir ya da çok tehlikelidir ; burada ikisinin ortası gibi dürüyor.
Doğru kurgulanırsa gayet iş görür.
Yanlış kurgulanırsa sessizce masraf çıkarır.
Ben kendi adıma bunun özellikle RAG projelerinde parlayacağını düşünüyorum.
Çünkü RAG’in ruhu güncel bilgiye dayanmak zaten.
Embedding eskiyse cevaplar hafif yamulur — kullanıcı belki anlamaz. Kalite düşer.
Ha bu arada,
veri şemasının sade tutulması burada kritik ;
gereksiz alanları embed etmeye kalkarsanız sonuç bulanıklaşabilir.
Sıkça Sorulan Sorular
Integrated Embeddings nedir?
Aslında oldukça kullanışlı bir özellik: Cosmos DB’ye item yazarken ya da güncellerken otomatik olarak embedding üretiyor. Yanı ayrı bir vektör pipeline’ı kurmanıza gerek kalmıyor, veri hep senkron kalıyor.
Bunu hemen production’da kullanmalı mıyım?
Eh, Açıkçası hayır, acele etmemek daha mantıklı. Hâlâ Public Preview aşamasında olduğu için kapsam, performans ve operasyon detaylarını kendi iş yükünüzle pilot ortamda test etmenizi öneririm.
Hangi modeller destekleniyor?
Şu an public preview kapsamında text-embedding-3-small, text-embedding-large ve text-embedding-ada-002 destekleniyor. Bence model seçerken maliyet ile kalite dengesini birlikte iyi düşünmek gerekiyor, ikisini ayrı ayrı ele almak doğru olmaz.
Maliyet avantajı sağlar mı?
Evet, sağlıyor. Bilhassa de de ayrı bir ingestion servisi, queue yapısı, retry mekanizmaları ve bunların bakım yükü düşünüldüğünde toplam sahip olma bedeli gerçekten düşebiliyor. Ama şunu da söyleyeyim: yoğun kullanımda model çağrıları yine fatura kesiyor, hani hesabı iyi yapmak lazım.
Kaynaklar ve İleri Okuma
Orijinal Microsoft Cosmos DB Blog Yazısı
Bence, Azure Cosmos DB Vector Search Resmî Dokümantasyonu
Integrated Vectorization in Azure Cosmos DB Docs
Azure Cosmos DB’de GSI: Okuma Yükünü Hafifletmenin Pratik Yolu
Tuhaf ama, SQL + AI: Elinizdeki Veriyi Bozmadan Akıllı Uygulama Kurmak

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.





Yorum gönder