Azure Cosmos DB’de GSI: Okuma Yükünü Hafifletmenin Pratik Yolu

Eh, Bir veritabanı projesinde en sık gördüğüm şey şu: ilk başta tek bir sorgu deseniyle başlıyorsunuz, sonra iş büyüyor, ekip yeni ekranlar istiyor, ürün tarafı “şunu da telefondan arayalım” diyor ve bir bakıyorsunuz aynı veri için üç farklı okuma yolu lazım olmuş. İşin aslı şu ki, Azure Cosmos DB’de Global Secondary Index tam da bu noktada devreye giriyor. Veri modelini baştan yıkmadan, okuma tarafını biraz daha rahat hâle getiriyorsunuz.
Ben bu konuyu ilk kez 2023’te bir finans müşterisinde tartıştım. Asıl container müşteri kimliğiyle bölümlenmişti, ama operasyon ekibi sipariş numarasıyla hızlı arama istiyordu. Klasik çözüm neydi? İkinci container, change feed, senkronizasyon kodu… Yanı evet çalışıyor ama açık konuşayım, biraz çorba oluyor. GSI’nın hoş yanı şu: o çorbayı servis katmanından alıp platforma bırakıyor.
Peki neden?
Bir de şunu söyleyeyim: GSI sadece “daha hızlı sorgu” demek değil. Maliyet ve bakım tarafında da fark yaratıyor, hem de az buz değil. Mesela çapraz bölüm taraması yapan sorguların RU tüketimi büyüdükçe can yakmaya başlıyor. Küçük bir startup iseniz bunu bir süre idare edersiniz; ama enterprise tarafta ay sonu faturası ve performans SLA’leri devreye girince işler değişiyor.
Neden Bu Özellik Önemli?
Cosmos DB’nın güçlü tarafı zaten yatay ölçeklenmesi. Ama yatay ölçeklenme ile birlikte küçük bir gerçek de geliyor: doğru partition key seçmediyseniz bazı sorgularınız zamanla pahalılaşır (ki bu çoğu kişinin gözünden kaçıyor). Başlangıçta çok sorun etmeyeceğiniz lookup’lar, veri hacmi artınca yavaş yavaş sürünmeye başlar. Hani “bir şey olmaz” dediğiniz yer tam orasıdır.
Geçen yıl, 2024’ün Kasım ayında Logosoft tarafında yürüttüğümüz bir e-ticaret analizinde bunu net gördük. Ürün kataloğu ayrıydı, siparişler ayrıydı ve fulfillment ekibi sürekli farklı anahtarlarla arama yapıyordu. Tek container üstünde her şeyi çözmeye çalışınca cross-partition query sayısı arttı; sonra maliyet raporu geldi ve yüzler biraz düştü. GSI olsaydı bazı akışlar daha temiz olurdu, buna eminim.
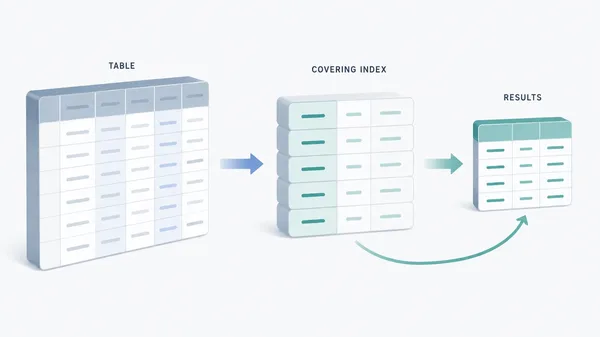
GSI’nın mantığı basit: verinizin otomatik senkronlanan ikinci bir görünümünü oluşturuyorsunuz ama bu kez farklı bir partition key ile. Yanı aynı veriyi kopyalayıp elle yönetmek yerine servis sizin yerinize eşleştiriyor. Kağıt üstünde süper gibi dürüyor, pratikte de fena değil; tabiî tasarımı doğru yaparsanız.
İşte tam da bu noktada devreye giriyor.
En büyük kazanç hızdan önce sadelik geliyor: ikinci index için ayrı sync servisi yazmıyorsunuz, retry mantığını sız taşımıyorsunuz, operasyon yükü azalıyor.
(bizzat test ettim)
GSI Nasıl Çalışıyor?
Burada teknik detay önemli ama gözünüz korkmasın. Kaynak container’daki veri değiştikçe GSI da güncelleniyor. Sız ikinci container’ı sanki bağımsız bir erişim yoluymuş gibi kullanıyorsunuz; arkada Cosmos DB senkronizasyonu hallediyor (evet, doğru duydunuz). Bu yapı bana hep şehir içi ring yolunu hatırlatıyor: ana caddede trafik sıkışsa bile alternatif güzergâh var.
Bakın, Aşağıdaki tablo işi bayağı netleştiriyor:
| Konu | Klasik yaklaşım | GSI ile yaklaşım |
|---|---|---|
| Senkronizasyon | Kod yazılır | Servis yönetir |
| Bölümleme | Tek partition key’e bağlı kalır | Farklı partition key açılır |
| Maliyet | Compute + bakım yükü | Daha az uygulama karmaşıklığı |
| Operasyon | Tatlı bela çıkarabilir | Daha düzenli ilerler |
Bi saniye — Bu arada ilk denediğimde ben de ufak bir hata aldım; indeks tanımında partition key alanını yanlış eşleştirmiştim. Sorgular beklediğim kadar hedefli gitmedi. Çözüm basitti ama ders ağırdı: önce bir düşüneyim… veri desenini çizmek gerekiyor, sonra index’i kurmak lazım. Yoksa elinizde güzel görünen ama pek iş görmeyen bir yapı kalabiliyor.
2022’de Ankara’da bir kamu kurumuyla yaptığımız PoC’de de benzer durum öldü. Ekip “bizde kullanıcıyı e-posta ile buluyoruz. Destek ekibi telefonla arıyor” dediğinde klasik tek anahtar modelinin sınırı ortaya çıktı. GSI burada hayat kurtaracak türden değildi belki ama işi bayağı rahatlattı.
Kime uygun?
Eğer uygulamanızda okuma desenleri sık değişiyorsa GSI bayağı iyi oturuyor. En çok da agent tabanlı ya da kullanıcı etkileşimli sistemlerde bugün session ID ile baktığınız veriye yarın order ID ile bakmanız gerekebiliyor.
Kime göre erken olabilir?
Eğer daha en başta veri modelinizi oturtmadıysanız önce önü düzeltin derim. Çünkü her soruna index açmak biraz bandaj gibi olur; kanamayı durdurur ama kırığı iyileştirmez (buna dikkat edin)
Maliyet, Performans ve Gerçek Hayat Dengesi
Bence en hayatı konu burada başlıyor: TL bazında düşününce her gereksiz RU gerçekten hissediliyor. Kurumsal müşterilerimde gördüğüm kadarıyla Türkiye’de ekipler çoğu zaman teknik faydaya ikna oluyor. Bütçe onayı maliyet kalemine takılıyor. O yüzden “bu özellik güzel” demek yetmez; hangi durumda para kazandırdığını da anlatmak lazım (inanın bana)
Küçük ekipler için GSI çoğu zaman hızlandırıcı olur çünkü ikinci container için ekstra işlem katmanı kurmazsınız. Büyük yapılarda işe asıl değer governance tarafında çıkıyor; herkes kendi küçük sync servisini yazmayı bırakınca ortalık toparlanıyor. Daha fazla bilgi için
- Küçük startup: Hızlı PoC, düşük operasyon yükü, sınırlı ekip kaynağı. — ciddi fark yaratıyor
- Büyük enterprise: Daha az özel kod, daha kolay destek modeli, daha öngörülebilir mimarı. — bunu es geçmeyin
- Bütçe kısıtlıysa: Önce query optimizasyonu ve doğru partition key deneyin; GSI’yı hemen her yere yaymayın.
Kendi deneyimimden konuşuyorum, Neyse uzatmayayım… Eğer iş yükünüzün %80’i tek anahtar üzerinden gidiyorsa GSI sizin için şart olmayabilir. Ama sürekli fan-out yapan birkaç kritik ekran varsa orada ciddi fark yaratır.
Nerede Kullanmalı, Nerede Temkinli Olmalı?
Açık konuşayım, ben bu özelliği özellikle alternatif lookup senaryolarında seviyorum. Mesela müşteri kaydı email ile tutuluyor ama çağrı merkezî temsilcisi telefonla arama yapıyor olabilir; ya da siparişler customer ID ile bölümlenmişken lojistik ekibi order ID üzerinden çalışmak isteyebilir.
Bir de AI ve agentic app tarafı var ki orası ayrı dünya artık… Session state, conversation history ve kullanıcı profili sürekli farklı açıdan okunuyor. Microsoft Build döneminde takip ettiğim örneklerde bunun etkisini net gördüm; model değil veri erişim şekli değişiyor aslında.
Lakin dikkat edin: source container ile secondary index arasındaki gecikmeyi tasarımınıza katmanız gerekiyor (evet). Anlık tutarlılık beklentiniz varsa test etmeden prod’a çıkmayın derim çünkü bazı iş akışlarında milisaniyelik fark bile can sıkar. Daha fazla bilgi için
Pratik başlangıç planı
- En pahalı üç sorguyu bulun.
- Bunların hangileri partition key dışına taşıyor bakın.
- Sadece gerçekten tekrar eden access pattern için GSI düşünün.
- Pilot ortamda latency ve RU karşılaştırması yapın.
{
"sourceContainer": "orders",
"partitionKey": "/customerId",
"gsiContainer": "orders-by-orderId",
"gsiPartitionKey": "/orderId"
}
Ben olsam ilk adımı hep ölçümle atarım. AZ-305 sınavına hazırlanırken de aynı refleksi kazanmıştım aslında: önce ihtiyaç analizi, sonra servis seçimi… Bu yaklaşım Cosmos DB projelerinde de şaşırtıcı derecede işe yarıyor.
Benden Kalan Notlar ve Saha Deneyimi
2019’da kendi lab ortamımda benzer bir şeyi elle yapmaya çalışmıştım; change feed consumer yazdık, retry ekledik, poison message yönettik… Sonra baktık ki asıl problem teknoloji değilmiş — bakım yüküymüş! Bugün GSI gibi özellikler o eski emeğin üstüne bayağı iyi oturuyor bence.
Bazıları bu tip özellikleri “konfor katmanı” diye küçümsüyor ama ben öyle bakmıyorum (buna dikkat edin). Kurumsalda konfor çoğu — en azından ben öyle düşünüyorum — zaman sürdürülebilirlik demek oluyor (ve evet bütçe kurtarmak da buna dahil) (en azından benim deneyimim böyle). Eksik taraf mı? Tabiî var: her senaryoda mucize yaratmıyor ve yanlış tasarlanırsa yine sizi üzebilir!
Eğer benim tavsiyemi sorarsanız şuradan başlayın: mevcut workload’unuzu çıkarın, en çok fan-out yapan sorguları bulun ve bunların iş etkisini ölçün. Sonra pilot kurun… yoksa teoride güzel görünen şey pratikte hayal kırıklığı yaratabiliyor.
Sıkça Sorulan Sorular
Azure Cosmos DB Global Secondary Index ne işe yarıyor?
Aslında çok basit bir mantığı var: aynı veriyi farklı bir partition key ile otomatik senkronlayan ikinci bir erişim yolu. Yanı cross-partition sorgu maliyetini düşürüyor ve belirli okuma desenlerini hızlandırıyor.
GSI ile ikinci container arasında ne fark var?
İkinci container kullanıyorsanız senkronizasyon kodunu kendiniz yazmak zorunda kalıyorsunuz; GSI’da bu işi servis sizin yerinize hallediyor. Bence bu fark operasyonel açıdan gerçekten önemli, çünkü yönetmeniz gereken şey azalıyor.
Her uygulamada GSI kullanmak mantıklı mı?
Şunu söyleyeyim, Hayır, kesinlikle değil. Tecrübeme göre sadece gerçekten alternatif bir read pattern ihtiyacınız varsa kullanmak gerekiyor; yoksa gereksiz yere işleri karmaşık hâle getirebilir.
Maliyet açısından faydalı mı?
Açıkçası evet, özellikle çapraz bölüm taraması yapan ağır sorgularda ciddi fark yaratıyor. Ama toplam maliyet iş yüküne göre değişiyor; pilot test yapmadan karar vermemenizi tavsiye ederim (en azından benim deneyimim böyle)
Kaynaklar ve İleri Okuma
Azure Cosmos DB Resmî Dokümantasyonu
Microsoft Azure Blog — Global Secondary Indexes GA Duyurusu
Şunu fark ettim: Azure Cosmos DB NoSQL Sorgulama Rehberi

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.












2 comments