




.NET ile Vektör Veri: Yapay Zekâda Anlamı Gerçekten Nasıl Yakalarız?
Vektör Veri Nedir, Arkasında Ne Dönüyor?
Bazı şeyleri öğrenmenin tek yolu var: Kendini direkt olayın içine atmak. Geçen yıl şöyle bir şeye denk geldim: Bir müşterimizin ekibi, belgeler içinde “doğal dil” ile arama yapmak istiyordu. Hani şu klasik anahtar kelimeyle tarayıp bulduklarını önüne yığan sistemler yok mu… Açıkçası kimse mutlu olmuyordu bundan (evet, doğru duydunuz). O gün dedim ki, tamam kardeşim – demek ki bu işte bambaşka bir çözüm lazım. İlk defa vektör tabanlı aramanın neden heyecan verici olduğunu canlı kanlı gördüm.
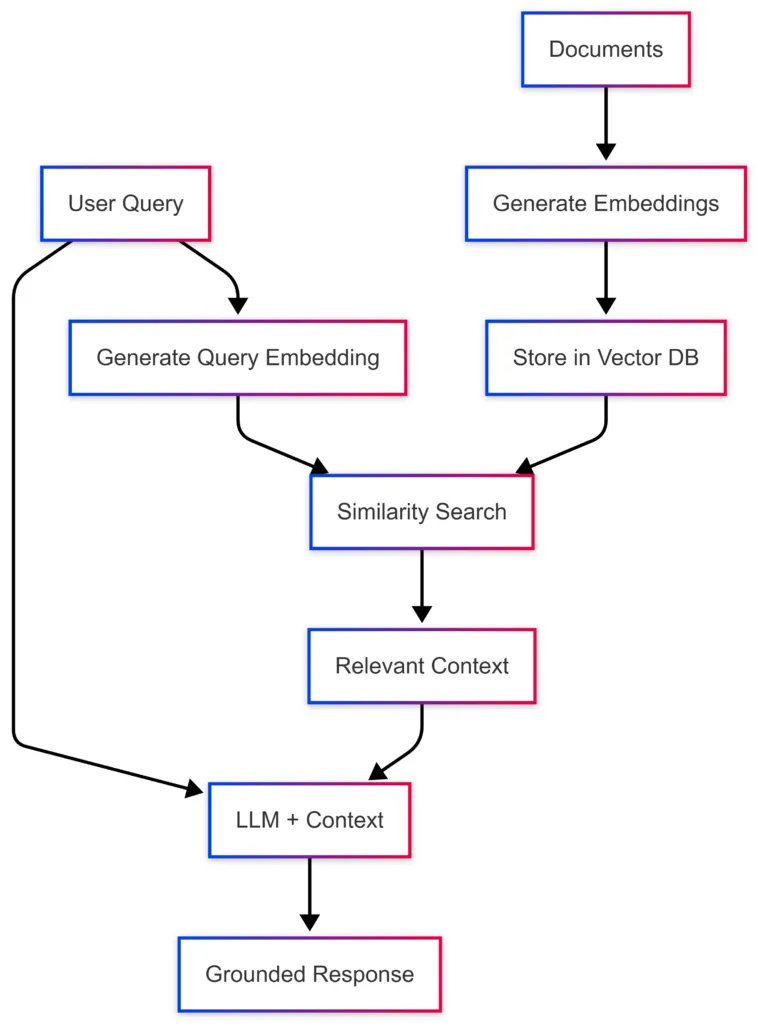
Peki vektör deyince ne anlamak lazım? Bak özet geçiyorum: Metni rakamlara döküyorsun;. Öyle harf harf değil — tüm cümlenin anlamını taşıyan bir sayı listesi olarak düşün. Yani artık yalnızca “elma”yı buldu diye göstermiyor, cümlenin bağlamına. Derinine de bakabiliyor; hislere bile matematikle dokunuyor biraz (evet, doğru duydunuz)
💡 Bilgi: Embedding, metinleri sayısal vektöre çeviren özel yapay zekâ modellerinin çıktısıdır. Anlamca yakın iki farklı ifade çok benzer vektör üretir—daha havalı anlatmaya gerek yok!
Hani, .NET’çiler için olayı daha pratik hale getiren yeni bir oyuncu çıktı ortaya: Microsoft.Extensions.VectorData. Kod karmaşasına takılmadan hem sadeleşiyorsun hem de hangi vektör veri tabanını seçersen seç, kodun fazla değişmiyor — aynı yerden devam edebiliyorsun yani! (Bu noktada parantez açıp şunu söyleyeyim; çoklu ajan senaryolarında da bu yaklaşım hayat kurtarıcı oldu bana göre. Merak eden varsa buradan örneklerini okuyabilir. Valla pişman olmazsınız.)
Anlamsal Arama Gerçekten İşe Yarıyor mu?
Sana komik gelecek ama “pass” örneğini duymuşsundur belki; yine de buraya bırakıyorum çünkü konuya cuk oturuyor. Şimdi üç kayıt olsun elinde — “Hall pass”, “Mountain pass”, “Pass (verb)”. Kullanıcı biri çıkıp sorsa “How do I get over the pass?” veya “Where do I pick up my pass?” diye… Eski usul sistemlerin ikisinde de “pass” geçen her şeyi tokatlar gibi karşına getiriyorlar. Hiçbir mantık yok, dümdüz geliyor hepsi.
Günlük hayatta insanlar satır arasını okur da makineyi anlatamazsın… En azından eskiden öyleydi.
Şimdi embedding sayesinde işler değişti bence! Sorguyu da kendi diliyle vektöre çeviriyorsun, kayıtları zaten önceden çevirmişsin — iki tarafta da saf anlam bazında karşılaştırma yapıyorsun yani (en azından benim deneyimim böyle). Sonuçta? “How do I get over the pass?” sorusu otomatik olarak “Mountain pass”i bulurken, diğeri de doğru şekilde “Hall pass”i yakalıyor mesela! Hem deneyimi hem algoritmayı başka boyuta taşıdı diyebilirim.
Kendim yıllar önce Python & Elasticsearch ile oynarken böyle sonuçlara rastladığımda hafiften içimde kelebekler uçmuştu; şimdi .NET dünyasında bunu neredeyse ezbere kodlamak açıkçası şaşırtıcı rahatlık sunuyor bana göre (yanlış duymadınız)
Vector Database Olmadan Olmaz mı?
Açık konuşacağım – burada sihrin asıl kısmı embed edilmiş datanın hızlı tutulmasında yatıyor! Her seferinde sıfırdan embedding oluşturmak resmen kaynak israfı olurdu; onun yerine doğrudan saklayan özel veritabanları var şimdi piyasada – Qdrant desen orada, Redis bile olaya el attı, SQL Server’ın yeni nesil sürümleri cabası (Cosmos DB ise apayrı dünya).
Peki niye vector database lazım?
- Sorgular saniyede yıldırım hızıyla geliyor çünkü embedding’ler önceden hazır bekliyor.
- Anlam kıyaslamasını ekstra yazılımla uğraşmadan alıyorsun – hem zamandan kazanıyorsun hem hata riskin azalıyor.
- Büyük hacimli uygulamalarda latency epey düşük oluyor (ve müşteri daha az homurdanıyor!)
- Kendi algoritmanı elle yazmana lüzum kalmıyor; aşağıda örneğine geçeceğim…
Tamam ama masallara inanmayalım… Yoğun trafik altında Redis ciddi RAM yiyebiliyor ya da Qdrant tarafında bazen index güncellenirken query performansı düşüyor (ben yaşadım). SQL Server derseniz hala ağırlığı klasik sorguda ama vector işlerinde birkaç versiyon sonrası tam istediğimiz noktaya gelir gibime geliyor—bunu not edin!
Nerede Kullandım? Bir Deneyimden Bahsedelim…
Bundan birkaç ay önce bankacılık için hazırladığımız chatbot projesini hatırladım hemen — çalışanların sıkça ihtiyaç duyduğu evrakların aramasında Azure OpenAI’dan gelen embedding’leri Redis Vector Store’da tuttuk. Fena sonuç olmadı; yanlış belge önerileri yüzde otuz civarında azaldı, memnuniyet puanı gözle görülür şekilde yükseldi! Tabi ilk başlarda tuhaf eşleşmeler yüzünden gülüp geçtiğimiz anlar oldu (“izin formu” arayan adama sistemin ‘istifa prosedürü’ önermesi gibi trajikomik durumlar), sonradan model iyileştirmeleri ile bunları minimize ettik zaten.
.NET ve Microsoft.Extensions.VectorData Kullanmanın Tadını Nerede Alıyoruz?
Dostum burada mesele sadece teknik basitlik değil aslında… Gerçek bir standartlaşma söz konusu oldu resmen! Eskiden ayrı servislerin SDK’sını kurcalamakla uğraşıyorduk ve inanın ciğerimiz soluyordu—şimdi ise tek interface ile ister Qdrant’a git ister Cosmos DB’ye yol al… Ayarı tek yerden çekip arkayı değiştirmek mümkün hale geldi! Gece Yarısı Çöken Donanım: WinForms ve AI Bir Anneye Nasıl Can Simidi Oldu? yazımızda da bu konuya değinmiştik.
- Kod bağımsızlığı: İstediğin platforma taşırken kırılan kodlarla boğuşmuyorsun; migrasyon kolaylaşıyor mis gibi oluyor yani.
- Daha temiz kod: Merkezi yapı ve kontrolle kafanı karıştıran bin tane config dosyasından kurtuluyorsun—özellikle microservice yapanlara ilaç!
- Sürekli gelişme: Açık kaynak topluluğu sayesinde yenilikler ardı ardına geliyor ve sen hiç beklemeden faydalanabiliyorsun.
💡 Bilgi: VectorData Extensions sandığınızdan daha esnek—arama dışında tavsiye motorundan otomatik etiketlemeye kadar türlü projede kullanılabiliyor!
Kodu Göstersem Daha Net Olur Değil mi?
// Basit repository örneği
var service = new MyVectorService();
var result = await service.SearchAsync("Azure güvenlik ipuçları");
foreach(var item in result)
{
Console.WriteLine(item.Title + ": " + item.Score);
}
Beni en çok etkileyen yanlarından biri ise şu oldu; altyapıyı değiştirdikçe serviste hiçbir şey bozmadım! Kod taşındığında sabit kalan kısımlar insanın içini rahatlatıyor vallahi — kaç kere farklı sisteme göç etmiş adam olarak söylüyorum bunu… :)
Anlamsal Aramanın Can Sıkıcı Tarafları Bitmedi Mi?
Bence, Tamam iyi hoş diyerek abartmak istemiyorum… Çünkü hâlâ bazı engeller boy gösteriyor:
- Büyük data setlerinde embedding işlemi bütçe olarak can yakabiliyor.
- Türkçe gibi nüans dolu dillerde hata payı İngilizce’den yüksek çıkabiliyor (net bilgi!).
- Eşiği fazla gevşek bırakırsanız absürt öneriler patlıyor – kullanıcı siniri tavan!
En ilginci neydi biliyor musunuz? Biri çıktı “mesai izni nasıl alınır?” dedi, bizim sistem salladı tuttu başka bi’ belgeyi gösterdi — o an hafif sinirlendim açıkçası… Model update şart!
Neyse ki Microsoft’un aktif tuttuğu açık kaynak camiasının katkıları sayesinde adaptasyon hızımız fena halde arttı ve problemler kısa sürede dönüp çözülüyor çoğunlukla. Benzer krizlerden bolca bahsettim blogumda (göz atabilirsiniz burada detaylar var) özellikle geliştirici tecrübesinden merak edenlere duyurulur! (ben de ilk duyduğumda şaşırmıştım)
Peki Sonrası Ne Olacak? Vektör Veri ve Pratik İpuçlarımla Kapanış…
Kaba tabirle toparlayacak olursam… Artık .NET tarafındaki yapay zekâ projelerinde semantik search neredeyse default hal aldı sayılır—direkt kullanmak isteyen korkmasın bence! Bilhassa LLM temelli özellik düşünüyorsanız mutlaka Microsoft.Extensions.VectorData’yı bir denemenizi tavsiye ederim — başta basit durur ama proje büyüdükçe avantajlarını göreceksiniz.
- Küçük datasetlerde disk üzerinde idare edersiniz ama ölçek artınca vector database’e geçiş şart!
- Dilinize uygun embedding modeli tercih edin (Türkçe işi özellikle zorlayabilir.)
- Eşik değerlerini kesin test edin; düz bırakırsanız kullanıcı küser gider valla!
- Düzenli model update’i alışkanlık yapmalı yoksa hatalar üst üste biner sonra başınız ağrır.
(evet, doğru duydunuz)
Evet dostlar… Bugünlük bu kadar diyelim mi? Aklınıza takılan veya kendi başınıza yaşadığınız ilginç vakaları yorumlarda duymak isterim doğrusu (yanlış duymadınız). Ha unutmadan; haftaya .NET modernizasyonunda Copilot işlerine dalacağız beraber! Takipte kalmayı unutmayın 😉 (evet, doğru duydunuz)
Kaynak: [Vector Data in .NET – Building Blocks for AI Part 2](https://devblogs.microsoft.com/dotnet/vector-data-in-dotnet-building-blocks-for-ai-part-2/)
Kaynaklar ve İleri Okuma
Vector Representations in .NET ML
Embeddings – Azure OpenAI Service
Microsoft.Extensions on GitHub
Semantic Search and Vector Databases in Azure Cognitive Search
İçeriği paylaş:
İlgili Yazılar
.NET 10.0.5 ile macOS Debugger Çökmesine Son: Saha Notları ve Pratik Tüyolar21 Mar 2026Mart 2026 Azure SDK Güncellemeleri: Sürprizler, Detaylar ve Gerçek Hayat Yansımaları27 Mar 2026Merge Çakışmalarında Copilot Devrimi: Gerçekten Zahmetsiz mi?28 Mar 2026Azure SDK Kasım 2025: Gerçekten Fark Yaratan Neler Geldi?17 Mar 2026












Yorum gönder