Azure Kubernetes Fleet Manager’da Ağ Sınırı Kalkıyor: Benim Notlarım
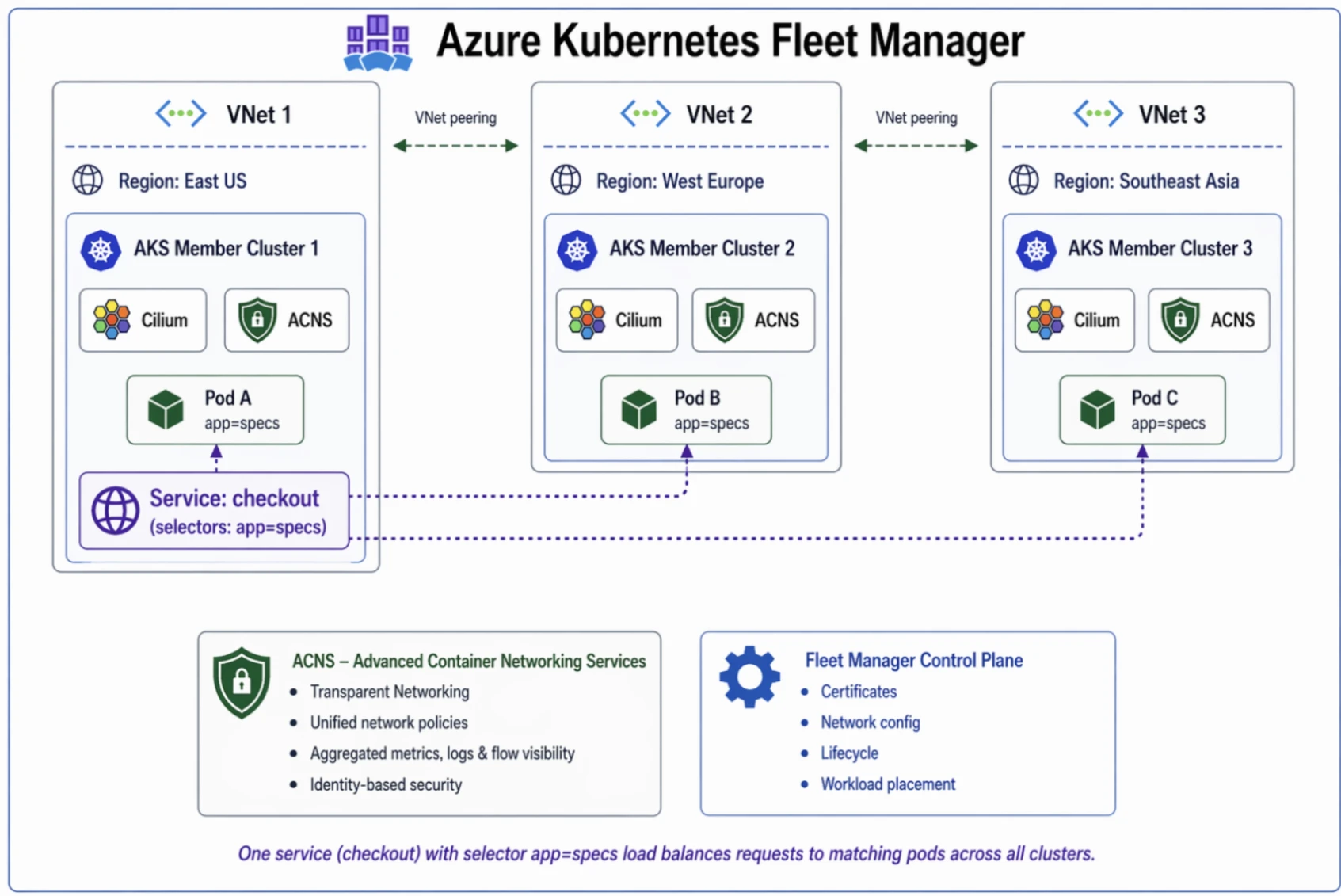
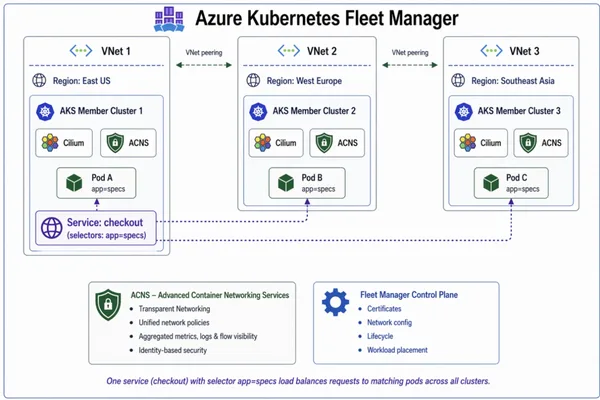
Şimdi dürüst olalım: çoklu küme işi ağda başlıyor
Bir Kubernetes kümesini ayağa kaldırmak zaten kendi başına uğraştırıyor. İki, üç, beş küme deyince işin tonu değişiyor. Bakın şimdi, asıl mesele çoğu zaman uygulama değil; uygulamanın birbirini nasıl bulacağı, trafik nereye akacak, failover olunca kim kimi görecek… İşte tam orada “networking tax” dediğimiz o görünmez yük çıkıyor ortaya.
Ben bunu ilk kez 2018’de bir finans müşterisinde net gördüm. İstanbul ve Frankfurt arasında çalışan iki AKS benzeri yapıda servis keşfi için VPN, özel route’lar ve bolca manuel ayar vardı. Kâğıt üstünde fena değildi ama pratikte her değişiklik küçük bir maceraya dönüyordu. Bir DNS kaydı yanlış güncellendiğinde bütün akşamı çöpe atmışlığımız var… Maalesef.
Durun, bir saniye.
Yanı, Azure Kubernetes Fleet Manager’ın cross-cluster networking yaklaşımı tam da bu yüzden dikkat çekici. Çünkü burada amaç sadece kümeleri yönetmek değil; kümeler arasındaki iletişimi de daha doğal hâle getirmek. Yanı “bu servis hangi cluster’da?” sorusunu biraz geri plana itip “uygulama çalışsın yeter” noktasına yaklaşmaya çalışıyor (bizzat test ettim)
Tuhaf ama, Aslında — dur bir saniye, önce şunu söyleyeyim: bu tür yenilikleri duyunca herkes hemen üretime koşmamalı. Kağıt üstünde süper görünen şeyler bazen gerçek (söylemesi ayıp) hayatta henüz ham kalabiliyor. Ama yine de bu özellik baya iş görüyor; özellikle çok bölgesel mimarı kuran ekipler için — valla güzel iş çıkarmışlar —
Bunu biraz açayım.
Cross-cluster networking neden bu kadar kritik?
Doğrusu, Klasik modelde her küme kendi adasında yaşıyor. Bu güvenlik açısından iyi gibi görünür ama işletme tarafında yorar. Servisler arası bağlantı için gateway zinciri kurarsınız, sonra gözünüz loglarda kalır, sonra biri “niye latency arttı?” diye sorar… Cevap çoğu zaman ağ katmanında saklıdır.
Geçen yıl Ankara’daki bir e-ticaret ekibiyle yaptığımız çalışmada benzer bir tablo vardı. Bölgesel dağıtım istiyorlardı ama ekip küçük olduğu için iki ayrı operasyon modeli taşımak istemediler. Orada net gördüm: startup ölçeğinde bile çoklu küme büyümeden geliyor; enterprise’da işe neredeyse kaçınılmaz oluyor.
Durun, bir saniye.
Multi-cluster dünyasında asıl ihtiyaç şudur: kapsayıcılık değil süreklilik. Uygulama gerektiğinde başka kümeye kayabilsin, shared service’ler düzgün konuşsun, platform ekibi de her seferinde elle müdahale etmek zorunda kalmasın. Bu kadar basit gibi görünüyor ama işin aslı biraz çetin.
Cilium ve Kubefleet neden önemli?
Burada Microsoft’un seçtiği açık kaynak temel baya anlamlı: dataplane tarafında Cilium, orchestration tarafında işe Kubefleet. Ben açık konuşayım, — ki bu tartışılır — CNCF tabanlı bileşenlerin arkasına yaslanmak bana daha güvenli geliyor;. Kilitlenmiş kapalı mimariler yerine ekosistemi geniş olan yapılarda nefes almak daha kolay oluyor.
Bunu yaşayan biri olarak söyleyeyim, 2019’da kendi lab ortamımda farklı CNI senaryolarını test ederken en büyük sorun gözlemlenebilirlikti (buna dikkat edin). Trafik gidiyor mu gitmiyor mu belli olmuyordu. Cilium’un eBPF temelli yaklaşımı burada işin tadını değiştiriyor diyebilirim — hem performans hem görünürlük tarafında eli güçlü.
İşte tam da bu noktada devreye giriyor.
E tabi kusursuz değil. Bu tip modern ağ katmanları öğrenme eğrisi getiriyor. En çok da klasik network mantığıyla yetişmiş ekiplerde ilk bakışta biraz kafa karıştırabiliyor; policy yazımı, identity bazlı kontrol ve observability birleşince konu derinleşiyor (şaşırtıcı ama gerçek)
Mimarı tarafta ne değişiyor?
Eh, Açıkçası en sevdiğim kısım şu: uygulama geliştiriciye “hangi cluster’a deploy oldun?” diye sürekli sordurmak yerine altyapıyı onun yerine soyutlamaya çalışıyorlar. Böylece servis keşfi ve doğrudan cluster içi/cluster dışı iletişim ayrımı daha az hissedilir hâle geliyor (bizzat test ettim)
| Konu | Klasik yaklaşım | Cross-cluster networking |
|---|---|---|
| Trafik yönlendirme | VPN / gateway / manuel route | Daha doğal servis-temelli erişim |
| Sorun giderme | Zor ve parçalı | Daha merkezî gözlem imkânı |
| Büyüme | Kümede sıkışır | Kümeler arasında yayılır |
| Operasyon yükü | Yüksek | Daha yönetilebilir olabilir |
Buna rağmen hayatı soru şu: gerçekten büyük çoğunluk iş yükleri buna uygun mu? Hayır. Mesela düşük gecikmeli tek bölge çalışan monolitik sistemlerde bu kadar karmaşık federasyon ihtiyacı olmayabilir. Ama regülasyon nedeniyle veri ayrıştırması yapan kurumlarda ya da aktif-aktif bölgesel tasarım isteyenlerde bu model baya işe yarıyor.
Bir de şu var: Azure’dan çıkan her yeni preview özelliğini üretime koymadan önce benim kafamda üç filtre olur — stabilite, işletilebilirlik ve maliyet çarpanı. AZ-305 sınavına hazırlanırken de aynı refleksi geliştirmiştim aslında; güzel teknoloji ile doğru teknoloji aynı şey değil!
Çoklu kümede kazanç sadece teknik değildir; doğru kurgulanırsa operasyon ekibinin akşam saatlerinde aldığı telefon sayısını da azaltır.
İşin tatlı tarafı burada.
Ama yanlış tasarlanırsa tam tersi olur.
Sonra herkes birbirine bakar…
ve suç ağda kalır.
Türkiye’de bunun karşılığı ne olur?
Bence Türkiye’de bu tip teknolojilerin benimsenmesi biraz daha temkinli ilerliyor çünkü şirketlerin önemli kısmı hâlâ hibrit yapılarla yaşıyor; bazı sistemler veri merkezinde, bazıları Azure’da, bazıları da hâlâ “dokunmayalım bozulmasın” modunda dürüyor. Bu yüzden cross-cluster networking gibi bir özellik bizde sadece teknik değil, kültürel dönüşüm konusu da oluyor.
Lafı gevelemeden söyleyeyim: enterprise müşteride karar verme süresi uzun ama etki alanı büyük oluyor.
Startup tarafında işe hız baskısı yüzünden çoğu ekip önce basit çözümü seçip sonra duvara tosluyor.
Örneğin geçtiğimiz mart ayında Gebze’de bir üretim firmasında konuştuğumuz yapı tam böyleydi; iki bölgede AKS planlıyorlardı ama ekip küçük olduğu için merkezî yönetim şarttı.
Onlara önerim şuydu:
- Eğer 3–4 servisten oluşan küçük bir yapı varsa önce standart ingress + service discovery ile başlayın.
- Eğer bölgeler arası failover gerçekten kritikse Fleet Manager tabanlı çözümü değerlendirin.
- Ağ karmaşıklığını gizlemek istiyorsanız platform standardizasyonu yapmadan ilerlemeyin. — bunu es geçmeyin
Maliyet nerede patlıyor?
Maliyet hesabını sadece Azure faturası sanmayın; asıl para insan saatinde gidiyor. VPN tünelleri kırıldı mı? Birinin gece çağrılması lazım mı? Route table güncellemesi sonrası test gerekiyor mu? Bunların hepsi dolaylı maliyet.TL bazında düşününce bazen orta ölçekli bir kuruma birkaç ekstra managed servis kullanımı pahalı görünebilir. Elle operasyonun bedeli daha ağır çıkabiliyor.”
Bütçesi sınırlı olan müşterilere genelde şöyle diyorum: önce kontrol düzlemini sadeleştirin, sonra network federation düşünün.
Eğer workload gerçekten dağıtık değilse sırf yeni çıktı diye kullanmayın.
Ama kapasite kaydırma, DR veya coğrafi yakınlık sizin işinizse pilot açıp ölçmek mantıklı olur.
Mesela latency testiyle başlayın: (şaşırtıcı ama gerçek)
- iki bölge seçin,
- trafik desenini simüle edin, (bence en önemlisi)
- failover süresini ölçün,
- operasyona kaç dakika harcadığınızı not edin…
Nerede güçlü, nerede zayıf?
Şöyle ki, Bence güçlü yanı açık: kümeler arası iletişimi normalleştiriyor. Platform takımının sırtından ciddi yük alabiliyor.. Zayıf yanıysa şu — böyle özellikler iyi dokümante edilmezse kurum içinde sadece birkaç kişinin bildiği sihirbazlık aracına dönüşüyor. Geçen sene bir telekom projesinde bunu başka ürünlerle yaşamıştık ; bilgi tek elde toplanınca sürdürülebilirlik düşüyor (şaşırtıcı ama gerçek). Sonra biri izin alınca sistem ortada kalıyor. Bir hayli can sıkıcı.
Bir diğer mesele de observability. Network soyutlandığında kullanıcı deneyimi iyileşebilir, fakat debug katmanı büyür. Hangi node, hangi pod, hangi endpoint… Bunları görmek için log, metrik ve trace zincirinin düzgün kurulması lazım. Yoksa problem çözmek yerine tahmin yürütmeye başlarsınız ; ben buna pek sıcak bakmam.
Hani derler ya “soyutlama rahatlatır”, evet doğru ; fakat fazla soyutlama da ipuçlarını saklayabilir. O yüzden ben genelde müşteriye şöyle söylerim : pilot aşamada genelde kısa ömürlü hatalar, bağlantı kesilmeleri ve yeniden yönlendirme senaryolarını simüle edin.
Bu servisi ilk denediğimde bana beklediğimden farklı şekilde policy uyumsuzluğu hatası gelmişti ; çözüm tarafında namespace etiketlerini yeniden düzenlemek gerekmişti. Küçük detay gibi görünüyor ama tam orada duvara çarpıyorsunuz.
Kimin için uygun?
>
Küçük ekipseniz : yalnızca gerçekten çoklu bölge ihtiyacınız varsa girin.
⠀
Ha unuttum neredeyse: Kubernetes’te ExternalIPs Neden Gidiyor: içindeki güvenlik geçiş notları da buraya iyi oturuyor.Siz olsanız nasıl başlardınız?
Biz Logosoft’ta genelde üç adımla ilerliyoruz:
- Önce topolojiyi çiziyoruz;
- Sonra gerçek trafik desenini çıkarıyoruz;
- En son preview özelliğini kontrollü pilotta açıyoruz.
Basit görünüyor ama işe yarıyor.
Bi saniye — Bazen müşteri “hemen prod” istiyor (tabiî), ben de “bir dakika” diyorum.
Neden? Çünkü multi-cluster işlerindeki en pahalı hata config hatası değil; yanlış varsayım oluyor.
Sıkça Sorulan Sorular
Azure Kubernetes Fleet Manager cross-cluster networking nedir?
Garip gelecek ama, Yanı kümeler arasında servislerin birbirini daha doğal bir şekilde görebilmesini sağlayan yönetilen bir ağ yeteneği diyebilirsiniz. Aslında tam da eksik hissedilen bir şeydi bu.
Bu özellik production için hazır mı?
Public preview aşamasındaki özellikleri üretime almadan önce mutlaka pilotlamak gerekiyor. Bence az riskliyse denenebilir, ama kritik sistemlerde temkinli olmak şart.
Çok küme mi yoksa tek büyük küme mi daha iyi?
Açıkçası tek doğru yoktur. Hani kümelenmenin amacı dayanıklılıksa çok küme mantıklı oluyor. Yoksa gereksiz karmaşa yaratabilirsiniz.
Maliyeti yüksek mi?
Yönetilen yapıların lisans ve servis maliyeti var tabiî, ama elle operasyonla kıyaslayınca toplam sahip olma maliyeti çoğu zaman dengeleniyor. Tecrübeme göre uzun vadede genelde kazançlı çıkıyorsunuz (evet, doğru duydunuz)
Kaynaklar ve İleri Okuma

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar



Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.






Yorum gönder