Microsoft 365 Copilot Agent Evaluations: Ajan Kalitesi Ölçümü
Açık konuşayım: Son bir yıldır müşterilerime Copilot ajanı kurarken en çok zorlandığım konu, demoda iyi görünen bir ajanın production’a çıkınca neden saçmaladığını anlatmaktı (ilk duyduğumda inanamadım). “Hocam, geçen hafta düzgün cevap veriyordu, bugün niye uydurmaya başladı?” sorusuna elimde sağlam bir cevap yoktu. Vardı da, ölçemiyordum işte. Şimdi Microsoft, Microsoft 365 Copilot Agent Evaluations aracını public preview’a açtı. Bu boşluğu kapatmaya çalışıyor.
📋 İçindekiler
- Neden tam da şimdi bir evaluation aracına ihtiyacımız vardı?
- Public preview’da ne var, ne yok?
- Türkiye’deki ekipler için bu ne anlama geliyor?
- Kurulum ve ilk çalıştırma
- Ilk denemede karşılaştığım sorun
- Vibe-coding ve coding agent’larla entegrasyon
- Önerim: Nasıl başlamalısınız?
- Eksik gördüğüm taraflar
- Sıkça Sorulan Sorular
- Kaynaklar ve İleri Okuma
Bence, Lafı gevelemeden söyleyeyim: bu araç, ajanlarınızın kalitesini sayısal olarak ölçmenizi, regression testleri yazmanızı ve CI/CD hattınıza koymanızı sağlayan bir CLI (en azından benim deneyimim böyle). Yanı artık “iyi çalışıyor sanırım” demek — kendi adıma konuşayım — yerine, “Coherence skoru 4.2, Groundedness 4.5” diyebileceksiniz. Fark var arada.
Evet, doğru duydunuz.
Neden tam da şimdi bir evaluation aracına ihtiyacımız vardı?
Bir buçuk yıl önce ilk declarative agent demolarını gördüğümde içimden “tamam, bu bir oyuncak” diye geçirmiştim. Yanılmışım. Mantıklı değil mi? Bugün Logosoft’ta birkaç müşterimizde Copilot ajanları ciddi iş süreçlerinin içine girmiş durumda; bir bankacılık müşterimizde kredi başvuru ön-değerlendirmesinde, bir lojistik firmasında sevkiyat sorgularında kullanılıyorlar.
İşin can sıkıcı tarafı şu: ajanların yaptığı iş kritikleştikçe, “demo kalitesi” yetmemeye başladı. Manuel test yapıyorsunuz, 20-30 prompt deniyorsunuz, “tamam yayınlayalım” diyorsunuz. Üç hafta sonra kullanıcı geliyor: “Ben şunu sordum, alakasız cevap verdi.” Tabiî. Çünkü sız 20 prompt denediniz, kullanıcılar 2000 farklı şekilde soruyor (ciddiyim)
İşte tam burada Agent Evaluations devreye giriyor. Az önce dokümana tekrar baktım — araç sizin önceden hazırladığınız test setini ajana gönderiyor, cevapları topluyor. Azure OpenAI tabanlı LLM-judge modelleriyle puanlıyor. Sonuç? HTML formatında bir scorecard. Paylaşılabilir, versiyonlanabilir, takip edilebilir.
“Ölçemediğin şeyi yönetemezsin” lafını mühendislik camiasında yıllardır duyarız. AI ajanları için de aynı şey geçerli. Hatta daha kritik — çünkü non-deterministic bir sistemden bahsediyoruz.
Public preview’da ne var, ne yok?
Şunu fark ettim: Şimdi teknik tarafa geçelim. Araç bir CLI olarak geliyor ve Microsoft 365 Agents Toolkit içine bütünleşik çalışıyor. Yanı VS Code’da ajan geliştiriyorsanız, ortamdan çıkmadan evaluation çalıştırabiliyorsunuz. Bu detay önemli aslında — geliştirici deneyimi açısından inner loop’tan kopmamak baya işe yarıyor.
Single-turn ve multi-turn desteği
Bence en değerli özelliklerden biri bu. Tek soru-tek cevap testi yapmak kolay. Ama gerçek kullanıcı şöyle konuşuyor: “Bana satış raporlarını göster” → “Sadece bu çeyreği” → “Şimdi bunları İstanbul ofisiyle filtrele” (kendi tecrübem). Bu üç adım boyunca ajanın bağlamı koruyup korumadığını ölçmek lazım. Multi-turn evaluation tam bunu yapıyor.
Çok konuştum, örnekle göstereyim.
Açık konuşayım, Geçen ay bir müşterinin ajanında tam bu sorun çıktı. İlk turn’de doğru cevap veriyor, ikinci turn’de bağlamı kaybediyordu. Manuel debug yaptık, üç gün gitti. Eğer bu araç o zaman elimde olsaydı, regression testte yakalardım muhtemelen.
Hangi metriklerle puanlanıyor?
Birkaç farklı evaluator var ve bence bunları anlamak şart:
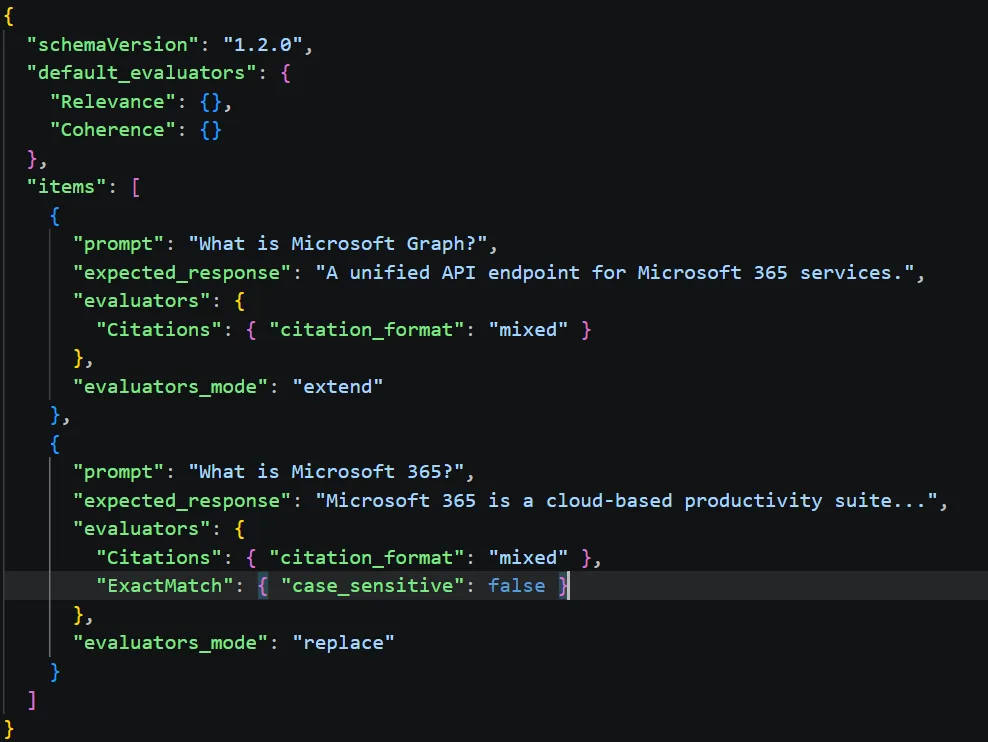
| Evaluator | Türü | Ne Ölçer? |
|---|---|---|
| Coherence | LLM-based | Cevap mantıklı ve tutarlı mı? |
| Groundedness | LLM-based | Cevap kaynak veriye dayanıyor mu, uyduruyor mu? |
| ExactMatch | Code-based | Beklenen cevapla birebir aynı mı? |
| PartialMatch | Code-based | Beklenen anahtar kelimeleri içeriyor mu? |
Burada gözden kaçırılmaması gereken şey şu: LLM-judge metrikleri (Coherence, Groundedness) için Azure OpenAI endpoint’i gerekiyor. Yanı ücretsiz değil. Aracın kendisi preview döneminde free ama altta dönen LLM çağrıları cebinizden çıkıyor. Bunu baştan söyleyeyim de sürpriz olmasın.
Türkiye’deki ekipler için bu ne anlama geliyor?
Vallahi, Kurumsal müşterilerimde gördüğüm kadarıyla Türkiye’de Copilot ajanı geliştirme süreci biraz farklı ilerliyor. Çoğu şirket hâlâ POC aşamasında; yanı “Bir tane ajan kuralım, görelim nasıl olacak” mantığı baskın. Bu aşamada evaluation tool kullanmak biraz lüks gibi görünebilir — haklı bir bakış açısı da. copilot ile ilgili önceki yazımız yazımızda bu konuya da değinmiştik.
Evet, doğru duydunuz.
Ama ben tersini düşünüyorum açıkçası. POC aşamasında bu aracı kullanmaya başlamak, ileride çekeceğiniz acıyı şimdiden hafifletiyor. Çünkü production’a giderken “kalite ne durumda?” sorusunun cevabı sayısal olarak elinizde oluyor. Yöneticinize gidip “evaluation skorlarımız şu, baseline’dan %15 iyiyiz” diyebiliyorsunuz. Bu küçük gibi dürüyor ama değil. Daha fazla bilgi için Yaş Doğrulama Yasaları: Geliştiriciler Neden Dikkat Etmeli? yazımıza bakabilirsiniz.
Küçük ekip mi, büyük kurumsal yapı mı?
Burada ayrımı net yapayım:
- Küçük ekipseniz (2-5 geliştirici): Önce 30-50 promptluk bir test seti hazırlayın. Manuel olarak bekleneni yazın. Haftada bir evaluation çalıştırın. CI/CD’ye dahil etmek için acele etmeyin.
- Orta ölçekli ekipseniz (5-20 geliştirici): Test setini 200+ prompt’a çıkarın. Her PR’da otomatik evaluation çalışsın. Skor düşüşünü merge engeli olarak kullanın.
- Enterprise yapıdaysanız: Test setlerini farklı persona/rol bazında bölün. Compliance gereksinimleriniz için ayrı evaluator’lar yazın. Scorecard’ları audit log gibi saklayın.
Peki neden bunu söylüyorum? Geçen ay bir finans müşterimizde buna yakın bir senaryo kurduk; KVKK uyumu için “PII leakage” diye custom bir evaluator yazdık. Ajan kullanıcının kişisel bilgisini cevapta tekrar etmeye kalkarsa skor düşüyor hâle getirdik.
Bu tür özelleştirmeler aracı gerçekten işe yarar kılıyor.
Kurulum ve ilk çalıştırma
Tuhaf ama, Tamam, pratik kısma gelelim şimdi.
Aracı denemek için elinizde olması gerekenler şunlar: (evet, doğru duydunuz)
- Microsoft 365 Copilot lisansı (kullanıcınız için)
- Tenant’ınıza deploy edilmiş bir declarative agent (bence en önemlisi)
- Node.js 24.12.0 veya üzeri — bunu es geçmeyin
- Tenant admin’den araç için onay (admin consent) — ciddi fark yaratıyor
- Azure OpenAI endpoint (LLM-judge için)
Şahsen, Dördüncü madde Türkiye’de bayağı problem oluyor — söyleyeyim.
Çünkü çoğu şirkette tenant admin ile geliştirici arasında ciddi mesafe var; “Bir aracı tenant’a bağlamak için onay isteyeceğim” demek bazen iki haftalık bekleme süresi anlamına geliyor.
Bu yüzden işe başlamadan admin’le konuşun, takım önceden hazır olsun.
Beşinci madde için Azure OpenAI’ın Türkiye’den erişilebilir bölgelerde (Sweden Central, West Europe) deploy edilmiş bir endpoint’i lazım. Maliyet tarafında düşününce de fena değil: GPT-4o-mini ile evaluator çalıştırırsanız 1000 prompt’lük test seti aşağı yukarı 2-3 dolar civarına oturuyor. Yanı ayda birkaç bin promptluk evaluation kurumsal bütçede gözükmeyecek kadar küçük kalıyor. Azure Cosmos DB ile Kurumsal Yapay Zekâ: Ölçek Meselesi yazımızda bu konuya da değinmiştik.
# Örnek bir CLI çağrısı (preview komutları değişebilir)
m365agents eval run \
--agent-id "your-agent-id" \
--test-set./tests/sales-queries.json \
--evaluators coherence,groundedness,partialmatch \
--output./reports/scorecard.html
Bu yaklaşım evaluation’ı code review sürecinin parçası yapmanın en kolay yolu.
PR’da yeni bir test eklenmesi, ajanın o senaryoyu desteklemesi gerektiği anlamına gelir.
Ilk denemede karşılaştığım sorun
Size bir şey söyleyeyim, Açık konuşayım, ilk denediğimde hata aldım.
Tenant’ta declarative agent picker’da görünmüyordu.
Yarım saat uğraştım.
Sonra fark ettim ki — agent’ı Copilot Studio’da değil, Agents Toolkit ile deploy etmişim ama publish etmemişim; yanı sadece local’de duruyordu.
Publish ettikten sonra picker’da göründü ve evaluation çalıştı.
Garip gelecek ama, Böyle küçük detaylar aslında önemli şeyler söylüyor: araç hâlâ ham.
Hata mesajları yeterince açıklayıcı değil.
“Agent not found” yerine “Agent is not published, please publish it first” deseydi otuz dakikam gitmezdi.
Preview olduğu için bunu fazla eleştirmek istemiyorum. GA olana kadar bu tür UX iyileştirmelerini bekliyorum. Azure SQL’de AI_GENERATE_EMBEDDINGS GA: T-SQL ile Vektör Devri yazımızda bu konuya da değinmiştik.
Bakın, burayı atlarsanız yazının kalanı anlamsız kalır.
Bir de şunu söyleyeyim
Şunu söyleyeyim, Sadece HTML scorecard güzel. Ben CSV/JSON çıktı da isterdim.
Çünkü uzun vadede skor trendlerini grafikte görmek istiyorum; Power BI’a bağlamak istiyorum.
Şu an HTML rapor güzel görünüyor ama başka sistemlere veri akıtmak için ekstra parsing yapmak gerekiyor.
Microsoft ekibi bunu duyarsa JSON export şart derim ben.
Vibe-coding ve coding agent’larla entegrasyon
Dikkatimi çeken başka bir nokta daha var: araç “vibe-code” ettiğiniz coding agent’ların içinden de çağrılabiliyor. Yanı Claude Code, GitHub Copilot Workspace veya benzer bir agent’la kod yazıyorsanız o agent sizin için evaluation tetikleyebiliyor. Bu baya ilginç bir döngü açıyor aslında (yanlış duymadınız) Daha fazla bilgi için Mailbox Import/Export Graph API’leri GA: EWS’in Sonu Geldi yazımıza bakabilirsiniz.
Bakın, şunu fark ettim: Düşünsenize: Copilot ajanı geliştiren bir coding agent’ın gidip ajanın kalitesini ölçen evaluation agent’ını çağırması… AI’ın AI’ı denetlediği bir dünya yanı.
Durable Workflows ile Microsoft Agent Framework: Gerçek Hayatta Ne İşe Yarıyor? yazımda bu tür agent-to-agent senaryolarını biraz daha detaylı ele almıştım.
Karmaşık. Kaçınılmaz gibi dürüyor.
Önerim: Nasıl başlamalısınız?
Doğrusu, Tamam diyelim ki aracı denemek istiyorsunuz.
Şu sırayla gidin: (ciddiyim)
- Önce test seti hazırlayın. Aracı kurmadan önce yapın bunu.
Test setiniz yoksa araç da pek işe yaramaz.
Kullanıcılarınızdan gerçek prompt örnekleri toplayın.
20 tane bile yeter başlangıçta. - Beklenen çıktıları yazın.
Her prompt için “ajan ne demeli?” sorusunun cevabını yazın.
Bu kısım sıkıcı ama atlamayın. - Baseline alın.
Mevcut ajanınızı çalıştırın ve skoru kaydedin.
Bu sizin “0.günkü” referansınız olur. - Iyileştirmeleri ölçün.
Her sistem prompt değişikliğinde ya da knowledge ekleme/çıkarma yaptığınızda tekrar çalıştırın.
Skor yukarı çıktı mı? - CICD’ye dahil edin.
Bu en son adım.
Acele etmeyin.
Neyse uzatmayayım; bu konuda Microsoft Agent Framework ile.NET’te Ajan Kurmanın Incelikleri yazımdaki yaklaşımla paralel düşünebilirsiniz — ölçmeden iyileştirme yapmak körlemesine ilerlemektir.
Eksik gördüğüm taraflar
- Suan sadece declarative agent destekliyor.
Custom engine agent’lar için yok. - Türkçe değerlendirme kalitesi henüz net değil.
Coherence ve Groundedness Ingilizce optimize edilmiş gibi dürüyor. -
Evet.
- A/B testing native değil.
Iki farklı versiyon ajanı karşılaştırmak için manuel uğraşmak lazım.Bu eksiklerin GA sürecinde kapanacağını umuyorum.
Ama su hâliyle bile hiç olmamasindan çok daha iyi.
Sıkça Sorulan Sorular
Microsoft 365 Copilot Agent Evaluations aracı ücretli mi?
Aracın kendisi public preview sürecinde ücretsiz. Ama hani LLM-judge evaluator’ları için (Coherence, Groundedness) kullanılan Azure OpenAI çağrıları sizin Azure aboneliğinizden kesiliyor. GPT-4o-mini ile bin promptluk bir evaluation, aslında yaklaşık 2-3 dolar falan yapıyor.
Hangi tür ajanları değerlendirebilirim?
Şu an public preview’da yalnızca tenant’ınıza deploy ettiğiniz declarative agent’ları test edebiliyorsunuz. Custom engine agent ya da Copilot Studio’daki gelişmiş senaryolar için destek henüz gelmiş değil. Bence roadmap’te bunlar da eklenecek, ama ne zaman bilinmez.
CI/CD pipeline’a nasıl entegre ederim?
CLI tabanlı olduğu için Azure DevOps veya GitHub Actions içinde bir step olarak kolayca çalıştırabilirsiniz. Yanı test setini repo’nuzda tutun, her PR’da CLI’yı tetikleyin, scorecard’ı artifact olarak saklayın (eh, fena değil). Skor belirli bir eşiğin altına düşerse PR’ı engellemek için de exit code kontrolü yapabilirsiniz — tecrübeme göre bu kısım gerçekten işe yarıyor.
Türkçe promptlar için skorlar güvenilir mi?
Açıkçası, henüz net değil. LLM-judge modelleri çok dilli ama İngilizce için daha iyi ayarlı. Türkçe test setlerinizde skorların biraz daha gürültülü çıkmasını bekleyebilirsiniz. Bence birkaç pilot çalıştırma yapıp önce baseline’ınızı oluşturmanız şart, yoksa sayılara güvenmek zor.
ExactMatch ve PartialMatch ne zaman kullanılır?
Deterministik çıktılar beklediğiniz durumlarda işe yarıyor. Mesela ajan bir form doldurma asistanıysa ve “tutar: 1500 TL” gibi spesifik bir formatı koruması gerekiyorsa ExactMatch mantıklı. Daha esnek senaryolarda işe PartialMatch ile anahtar kelime varlığını kontrol edebilirsiniz.
Kaynaklar ve İleri Okuma
- A/B testing native değil.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar


Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











2 comments