Azure Cosmos DB ile Kurumsal Yapay Zekâ: Ölçek Meselesi
Kurumsal yapay zekâ projelerinde en sık duyduğum cümle şu: “Model tamam da, veriyi ne yapacağız?” İşin aslı, çoğu ekip modeli konuşuyor; ama belge akışını, arama katmanını, güvenliği. Ölçek tarafını sonra düşünüyor. Sonra proje güzel başlıyor, birkaç pilot geçiyor, bir yerde takılıyor. Hani o meşhur “demo’da uçuyordu” hikâyesi var ya… işte tam orası.
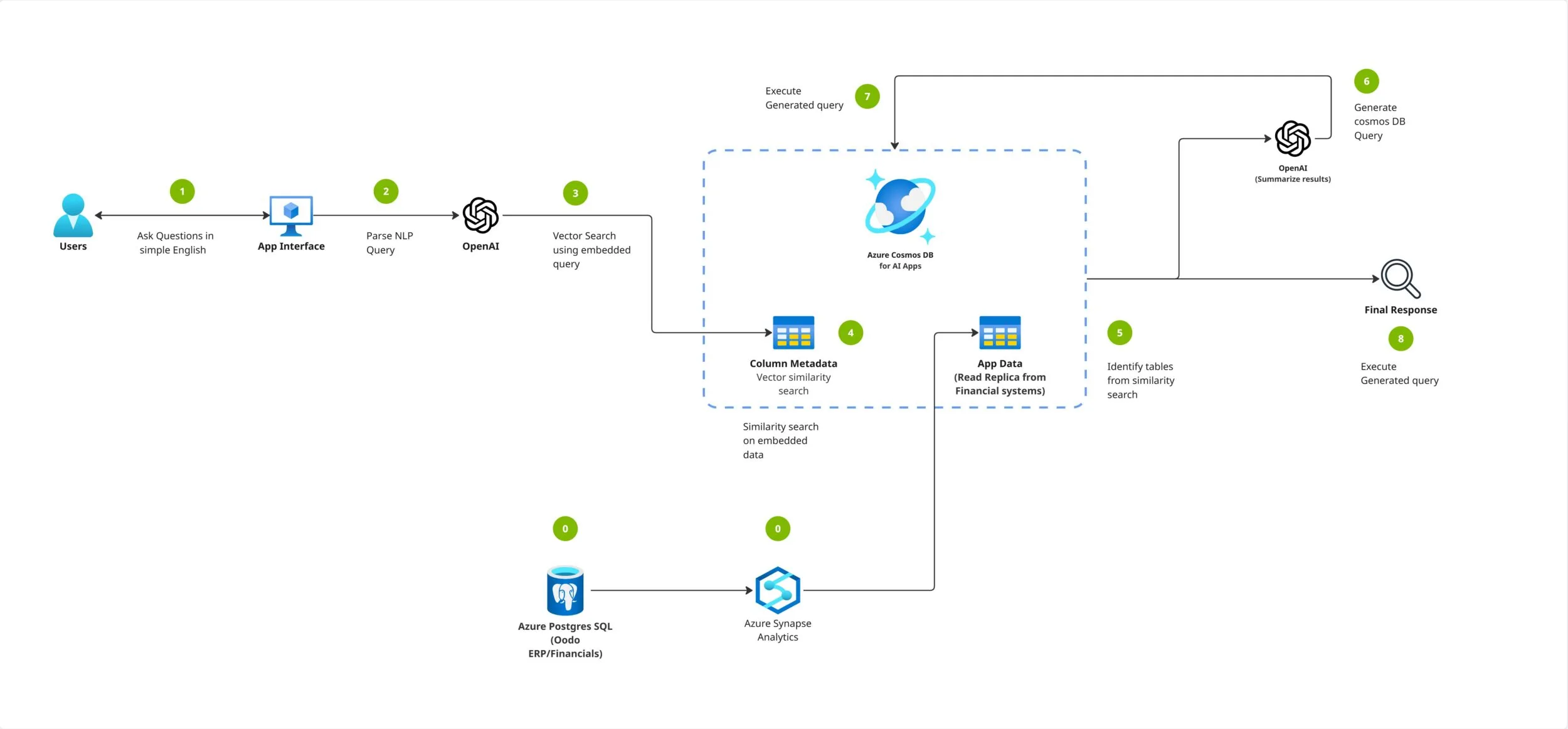
Microsoft’un Azure Cosmos DB etrafında anlattığı bu senaryo bana önemli geliyor,. Mesele sadece vektör arama ya da RAG değil. Mesele, kurumsal ölçekte dağınık veriyi tek bir omurgada tutup AI’a düzgün yedirmek. Ben bunu yıllardır hosting’den buluta taşınan yapılarda da gördüm; veri parçalıysa, AI projesi de biraz yamalı bohça gibi kalıyor.
Açıkçası, Geçen yıl Mart 2025’te bir finans müşterisinde buna çok benzer bir tabloyla karşılaştık. Belgeler SharePoint’te ayrı, operasyon kayıtları SQL’de ayrı, görseller başka yerdeydi. İlk denemede retrieval kalitesi fena değildi ama latency can sıkıyordu. Bir de embedding tarafı büyüyünce maliyetler hafiften şişmeye başladı. Neden önemli bu? O gün şunu net gördüm: doğru veri platformu seçilmezse GenAI projesi yarım kalıyor.
Evet, doğru duydunuz.
Neden mesele model değil, veri omurgası?
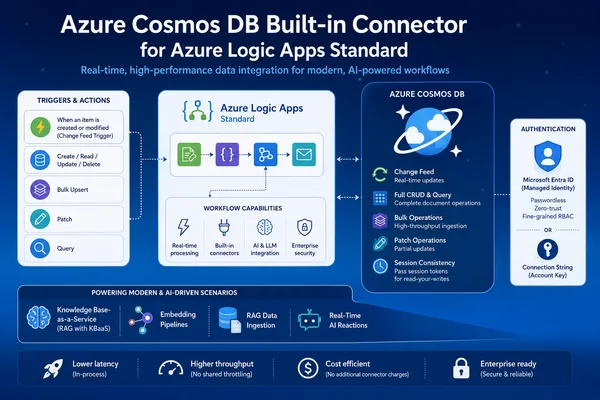
AVASOFT’un anlattığı çözümde beni en çok çeken nokta bu öldü. İnsanlar genelde LLM tarafına takılıyor; — kendi adıma konuşayım — oysa üretimde asıl yükü taşıyan katman çoğu zaman veri katmanı oluyor. Azure Cosmos DB burada sadece kayıt tutan bir veritabanı gibi davranmıyor; düşük gecikme, küresel dağıtım ve esnek şema yaklaşımıyla AI uygulamasının sırtını dayadığı zemin oluyor.
İşin garibi, Kurumsal tarafta belge işleme dediğiniz şey basit değil. Sözleşmeler var, uyumluluk dokümanları var, saha fotoğrafları var, eski PDF’ler var… Üstelik bunların hepsi farklı formatta geliyor. Klasik ilişkisel model bazen yetiyor ama her şeyi aynı sepete koymaya çalışınca ekibin işi uzuyor. Bu yüzden ben özellikle büyük yapılarda “önce kullanım senaryosunu netleştir, sonra veri modelini kur” diyorum.
2019’da kendi sunucu tarafı mimarilerimde benzer bir hata yapmıştım; her şeyi tek SQL şemasında toplamaya çalışmıştık. Başta mantıklı görünüyordu. Sonra arama ihtiyaçları arttı, yarı yapılandırılmış içerik geldi ve sistem ağırlaştı. Açık konuşayım, o proje bize iyi ders verdi: AI için uygun olan veri zemini ile klasik operasyonel veritabanı ihtiyacı aynı şey değil.
Cosmos DB neden öne çıkıyor?
Cosmos DB’nın burada dayanıklı tarafı esneklik ve ölçek hissini birlikte vermesi. Dokümanlar farklı biçimde gelebiliyor; metadata değişebiliyor; yeni alan eklemek için bütün sistemi yeniden doğurmuyorsunuz. Bu kulağa küçük geliyor olabilir ama enterprise’da küçük rahatlıklar büyük zaman kazandırıyor.
Hmm, bunu nasıl anlatsamdı…
Bir de vector search tarafı var tabiî. RAG akışında embedding saklamak için ayrı bir dünya kurmak yerine aynı platform içinde ilerlemek ekipleri rahatlatıyor. Söz konusu yaklaşım startup için de iyi olabilir ama enterprise’da asıl fark yönetim kolaylığında çıkıyor: güvenlik politikası daha net oluyor, operasyon daha az dağılıyor. Bu konuyla ilgili Azure Cosmos DB Shell Public Preview: CLI’a AI Geldi yazımıza da göz atmanızı tavsiye ederim.
AVASOFT Nexus ne anlatıyor?
AVASOFT’un Nexus çözümü bana göre tipik bir “AI demo” değil; üretime dönük düşünülmüş bir mimarı örneği. İyi tarafı şu: ingestion’dan retrieval’a kadar zincirin tamamını göstermeleri boş laftan uzak durduklarını gösteriyor. Bakın şimdi önemli kısım burada — birçok ekip sadece chat arayüzünü gösteriyor ama arkadaki boru hattını saklıyor.
Hmm, bunu nasıl anlatsamdı…
Nexus’ta veri alımı yapılıyor, embedding oluşturuluyor, Azure Cosmos DB içinde vektörler tutuluyor ve ardından RAG akışı ile cevap üretiliyor. Yanı sistemin beyni tek (söylemesi ayıp) başına LLM değil; hafızası da var diyebiliriz (hafıza deyince yanlış anlaşılmasın). Bu yaklaşım özellikle regülasyonlu sektörlerde baya iş görüyor çünkü cevabın kaynağı izlenebilir hâle geliyor.
Kurumsal AI projelerinde en kilit konu model seçimi değil; verinin nasıl hazırlandığı ve hangi hızda geri çağrıldığıdır. Bunu çözdüğünüz an işlerin rengi değişiyor.
Bence AVASOFT’un yaklaşımı doğru yönde atılmış bir adım ama hâlâ eksik kalan yerler de var: gözlemleme katmanı, kalite metrikleri. Maliyet kontrolü açık şekilde tasarlanmalı. Çünkü güzel çalışan sistem bile ay sonunda faturada suratınızı düşürebilir! En çok da de yoğun sorgulu ortamlarda bu detaylar kaçmaz.
Küçük ekip mi büyük kurum mu? Aynı reçete olmaz
Bir şey dikkatimi çekti: Küçük bir startup iseniz benim önerim basit: minimum bileşenle başlayın. Tek pipeline kurun, veri kaynağını dar tutun, gerekirse managed servislerle ilerleyin ve aşırı mimarı çizmekten kaçının. Çünkü sizde sorun teknoloji değil süre olur. Daha fazla bilgi için .NET 10 ile WebAssembly Hızlanınca Copilot Studio’da Neler Değişti? yazımıza bakabilirsiniz.
Enterprise tarafta işe durum tersine dönüyor biraz. Güvenlik onayı gerekir, ağ segmentasyonu gerekir, loglama gerekir, KVKK/GDPR düşünmeniz gerekir (kendi tecrübem). Hatta bazen iş teknikten çok süreç yönetimine dönüşüyor. Bir bankacılık projesinde bunu birebir yaşadık; model iyi çalışıyordu. Erişim matrisi yüzünden canlıya alma süresi uzadı. Bu konuyla ilgili Mailbox Import/Export Graph API’leri GA: EWS’in Sonu Geldi yazımıza da göz atmanızı tavsiye ederim. Bu konuyla ilgili GitHub Copilot’un Nisan Güncellemeleri: VS Code’da Sessiz Devrim yazımıza da göz atmanızı tavsiye ederim.
Bütçe açısından bakınca Cosmos DB bazı senaryolarda pahalı görünebilir; özellikle TL bazında hesaplayınca CFO’nun kaşı kalkabiliyor haklı olarak! Ama alternatifin insan emeğiyle yürüyen manuel süreç olduğunu düşününce resim değişiyor. Eğer bütçe kısıtlıysa önce pilot kapsamda başlayıp sonra ölçeklemek daha mantıklı olabilir.
| Senaryo | Daha Mantıklı Yaklaşım | Neden? |
|---|---|---|
| Startup / küçük ekip | Sade RAG + sınırlı kaynak seti | Daha hızlı doğrulama ve düşük operasyon yükü |
| Büyük kurum / regülasyonlu sektör | Cosmos DB merkezli kontrollü mimarı | Ölçek, güvenlik ve izlenebilirlik avantajı |
| Maliyet hassas proje | Kademeli pilot + kullanım takibi | Sürpriz faturaları azaltır |
Teknik tarafta dikkat edilmesi gerekenler
Açık konuşayım, vector search görünce herkes biraz heyecanlanıyor ama işin püf noktası parametrelerde gizli oluyor: chunk boyutu ne olacak, hangi metadata tutulacak, retrieval threshold nasıl ayarlanacak? Bunlar iyi kurulmazsa sistem size güzel görünen ama zayıf cevaplar verir. Daha fazla bilgi için GitHub Copilot Build Performance: Proje Bazlı Analiz Geldi yazımıza bakabilirsiniz.
{
"documentId": "contract-1048",
"contentType": "pdf",
"embeddingModel": "text-embedding-3-large",
"metadata": {
"department": "legal",
"region": "TR",
"confidentiality": "internal"
}
}
Bu tarz yapılandırmada ben hep şuna bakarım: cevap kalitesi mi daha kritik yoksa işlem hızı mı? İkisini aynı anda en üst seviyeye çekmek istiyorsanız maliyet artar… hani sihirli değnek yok burada. Bir denge kurmanız gerekiyor.
Ayrıca güvenlik kısmını hafife almamak lazım derken laf olsun diye söylemiyorum; AZ-500 hazırlığında öğrendiğim pek çok prensip burada direkt karşıma çıktı diyebilirim (özellikle veri erişimi. Kimlik katmanı). Model çıktısını korumak kadar girdiyi korumak da önemli. Yanlış belgeye erişen ajan sizi hiç istemediğiniz yere götürür!
Ben olsam ilk üç adımı böyle atarım
- Kullanım senaryosunu daraltırım: örneğin yalnızca sözleşme araması veya destek dokümanı analizi.
- Veri kaynaklarını temizlerim: tekrar eden dosyalar, bozuk PDF’ler ve eksik metadata ayıklanır.
- Pilot ölçerim: latency, doğruluk oranı ve aylık maliyet birlikte takip edilir.
Türkiye’de bu yaklaşım neden biraz farklı ilerliyor?
Aslında — hayır dur, daha doğrusu, Bunu Türkiye’deki şirketler açısından değerlendirecek olursak tablo biraz kendine özgü ilerliyor.
Bizde birçok kurum hâlâ legacy sistemlerle yaşıyor; veri göçleri tam bitmemiş oluyor ve departmanlar arasında standartlaşma zayıf kalabiliyor.
Dolayısıyla GenAI projesine girmeden önce altyapının toparlanması gerekiyor ki bu çoğu zaman asıl iş oluyor zaten.
,
Kendi deneyimimden konuşuyorum, E tabi yerel gerçeklerden biri de maliyet baskısı.
Dolar kuru oynayınca cloud faturası daha ilk haftadan toplantıya konu olabiliyor.
O yüzden ben müşterilere hep “önce değer kanıtla” diyorum; tüm şirketi dönüştürmeye çalışmak yerine tek departmanda faydayı gösterin, sonra genişletin.
Geçen sene İstanbul’daki orta ölçekli bir üretim firmasında bunu yaptık; bakım raporlarını otomatik özetleyen küçük pilot bile yönetime ikna için yeterli öldü.
,
Neyi sevdim, neyi eksik buldum?>
,
Sistemin en güçlü yanı ölçek hikayesini lafla değil mimariyle anlatmasıydı.
Yanı sadece “AI yaptık” demiyorlar; nasıl yaptıklarını açıyorlar.
Bu samimiyet hoşuma gitti.
Ama dürüst olayım, live demo kısmında performans rakamlarının daha somut verilmesini beklerdim; mesela sorgu başına gecikme ya da indeks büyüdükçe davranış gibi metrikler çok işe yarardı (buna dikkat edin)
,
Bunun dışında AVASOFT’un Microsoft ekosistemindeki konumu önemli.Modern Work’tan Data & AI’ye kadar geniş yelpazede çalışmaları sayesinde çözümü tek ürün gibi değil uçtan uca hizmet olarak konumlandırabiliyorlar.Kurumsal müşteri için bu değerli. Insanlar araç değil sonuç satın alıyor.
,
Sıkça Sorulan Sorular
Azure Cosmos DB GenAI projelerinde neden tercih ediliyor?
Aslında birkaç temel nedeni var: düşük gecikme, esnek şema yapısı ve küresel ölçekleme. Burada, en çok da belge tabanlı RAG senaryolarında bence gerçekten işe yarıyor. Hani tek platformda hem vektör hem metadata yönetebiliyorsunuz, bu da işleri epey sadeleştiriyor.
Cosmos DB kullanmak çoğu zaman doğru seçim mi?
Kısa cevap: hayır. Küçük PoC’lerde daha basit alternatifler gayet yeterli olabiliyor. Ama açıkçası veri hacmi büyümeye başlayınca ve çok bölgeli çalışma gerekince, Cosmos DB ciddi bir avantaj sağlıyor.
Kurumsal AI projesine nereden başlanmalı?
Şunu söyleyeyim, Tecrübeme göre ilk iş kullanım senaryosunu iyice daraltmak. Sonra veri kaynaklarını temizleyip kalite kontrol mekanizmaları koyun. Model seçimini en sona bırakmak, yanı önce problemi netleştirmek, çoğu zaman çok daha sağlıklı sonuç veriyor.
Maliyetleri nasıl kontrol altında tutarım?
Pilot kapsamıyla başlayın ve tüketimi düzenli izleyin. Gereksiz embedding yenilemelerini azaltmak da bence önemli bir kalem. Ayrıca loglama sayesinde hangi sorguların gerçekten değer ürettiğini görebiliyorsunuz, bu da kaynakları doğru yönlendirmenizi sağlıyor.

20+ yıl deneyimli Azure Solutions Architect. Microsoft sertifikalı bulut mimari ve DevOps danışmanı. Azure, yapay zekâ ve bulut teknolojileri üzerine Türkçe teknik içerikler üretiyor.
İlgili Yazılar




Bu içerik işinize yaradı mı?
Benzer içerikleri kaçırmamak için beni sosyal medyada takip edin.











4 comments